Department of Life Science, Shiv Nadar University, Greater Noida, UP, 201314, India.
Department of Animal Biotechnology, Sher-e-Kashmir University of Agricultural Sciences and Technology, Shuhama, Jammu and Kashmir, 190016, India.
Sci Rep. 2017 Oct 2;7(1):12543. doi: 10.1038/s41598-017-13083-y.
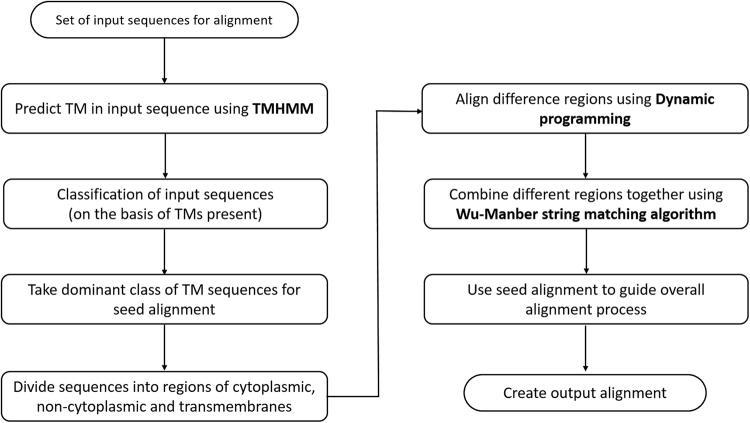
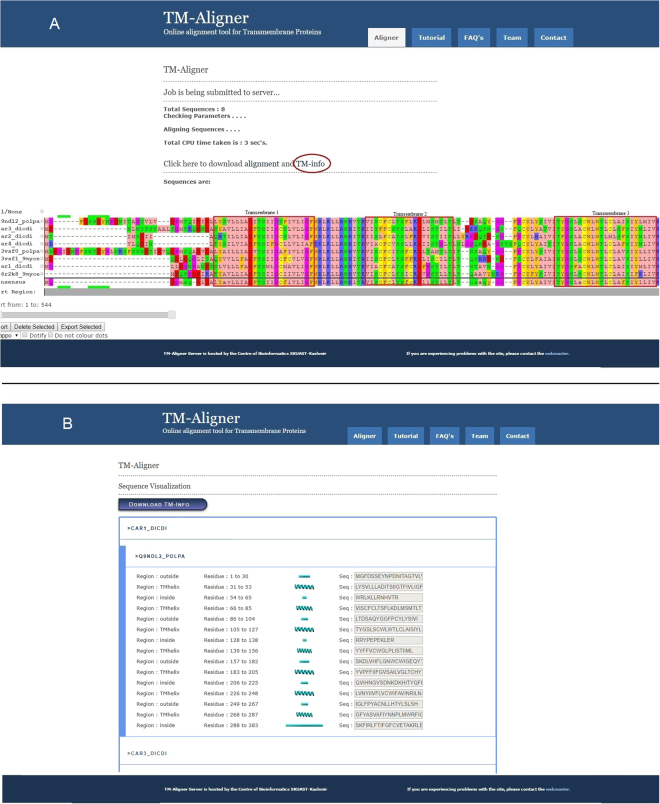
Membrane proteins plays significant role in living cells. Transmembrane proteins are estimated to constitute approximately 30% of proteins at genomic scale. It has been a difficult task to develop specific alignment tools for transmembrane proteins due to limited number of experimentally validated protein structures. Alignment tools based on homology modeling provide fairly good result by recapitulating 70-80% residues in reference alignment provided all input sequences should have known template structures. However, homology modeling tools took substantial amount of time, thus aligning large numbers of sequences becomes computationally demanding. Here we present TM-Aligner, a new tool for transmembrane protein sequence alignment. TM-Aligner is based on Wu-Manber and dynamic string matching algorithm which has significantly improved its accuracy and speed of multiple sequence alignment. We compared TM-Aligner with prevailing other popular tools and performed benchmarking using three separate reference sets, BaliBASE3.0 reference set7 of alpha-helical transmembrane proteins, structure based alignment of transmembrane proteins from Pfam database and structure alignment from GPCRDB. Benchmarking against reference datasets indicated that TM-Aligner is more advanced method having least turnaround time with significant improvements over the most accurate methods such as PROMALS, MAFFT, TM-Coffee, Kalign, ClustalW, Muscle and PRALINE. TM-Aligner is freely available through http://lms.snu.edu.in/TM-Aligner/ .
膜蛋白在活细胞中起着重要作用。跨膜蛋白估计约占基因组规模蛋白质的 30%。由于实验验证的蛋白质结构数量有限,因此开发针对跨膜蛋白的特异性对齐工具一直是一项艰巨的任务。基于同源建模的对齐工具通过在提供的参考对齐中重新生成 70-80%的残基,提供了相当好的结果,前提是所有输入序列都应该具有已知的模板结构。然而,同源建模工具需要大量的时间,因此对齐大量序列在计算上变得具有挑战性。在这里,我们介绍了 TM-Aligner,这是一种用于跨膜蛋白序列对齐的新工具。TM-Aligner 基于 Wu-Manber 和动态字符串匹配算法,显著提高了其在参考对齐中重新生成 70-80%残基的准确性和速度,所有输入序列都应该具有已知的模板结构。然而,同源建模工具需要大量的时间,因此对齐大量序列在计算上变得具有挑战性。在这里,我们介绍了 TM-Aligner,这是一种用于跨膜蛋白序列对齐的新工具。TM-Aligner 基于 Wu-Manber 和动态字符串匹配算法,显著提高了其在参考对齐中重新生成 70-80%残基的准确性和速度,所有输入序列都应该具有已知的模板结构。然而,同源建模工具需要大量的时间,因此对齐大量序列在计算上变得具有挑战性。在这里,我们介绍了 TM-Aligner,这是一种用于跨膜蛋白序列对齐的新工具。TM-Aligner 基于 Wu-Manber 和动态字符串匹配算法,显著提高了其在参考对齐中重新生成 70-80%残基的准确性和速度,
我们将 TM-Aligner 与现有的其他流行工具进行了比较,并使用三个独立的参考数据集(BaliBASE3.0 参考集 7 的α-螺旋跨膜蛋白、来自 Pfam 数据库的基于结构的跨膜蛋白比对和来自 GPCRDB 的结构比对)进行了基准测试。与参考数据集的基准测试表明,TM-Aligner 是一种更先进的方法,具有最短的周转时间,并在最准确的方法(如 PROMALS、MAFFT、TM-Coffee、Kalign、ClustalW、Muscle 和 PRALINE)上取得了显著的改进。TM-Aligner 可通过 http://lms.snu.edu.in/TM-Aligner/ 免费获得。