Department of Biomedical Informatics, Vanderbilt University Medical Center, United States; Department of Medicine, Vanderbilt University Medical Center, United States; Department of Psychiatry, Vanderbilt University Medical Center, United States.
Department of Biomedical Informatics, Vanderbilt University Medical Center, United States.
J Biomed Inform. 2017 Dec;76:9-18. doi: 10.1016/j.jbi.2017.10.008. Epub 2017 Oct 24.
Prior to implementing predictive models in novel settings, analyses of calibration and clinical usefulness remain as important as discrimination, but they are not frequently discussed. Calibration is a model's reflection of actual outcome prevalence in its predictions. Clinical usefulness refers to the utilities, costs, and harms of using a predictive model in practice. A decision analytic approach to calibrating and selecting an optimal intervention threshold may help maximize the impact of readmission risk and other preventive interventions.
To select a pragmatic means of calibrating predictive models that requires a minimum amount of validation data and that performs well in practice. To evaluate the impact of miscalibration on utility and cost via clinical usefulness analyses.
Observational, retrospective cohort study with electronic health record data from 120,000 inpatient admissions at an urban, academic center in Manhattan. The primary outcome was thirty-day readmission for three causes: all-cause, congestive heart failure, and chronic coronary atherosclerotic disease. Predictive modeling was performed via L1-regularized logistic regression. Calibration methods were compared including Platt Scaling, Logistic Calibration, and Prevalence Adjustment. Performance of predictive modeling and calibration was assessed via discrimination (c-statistic), calibration (Spiegelhalter Z-statistic, Root Mean Square Error [RMSE] of binned predictions, Sanders and Murphy Resolutions of the Brier Score, Calibration Slope and Intercept), and clinical usefulness (utility terms represented as costs). The amount of validation data necessary to apply each calibration algorithm was also assessed.
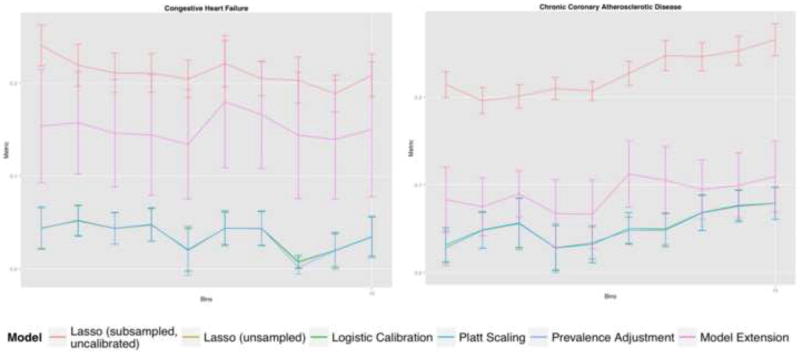
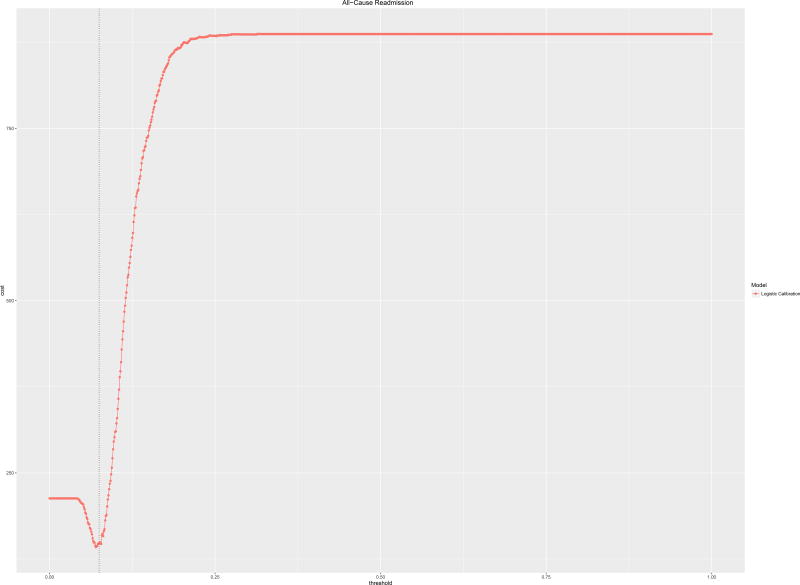
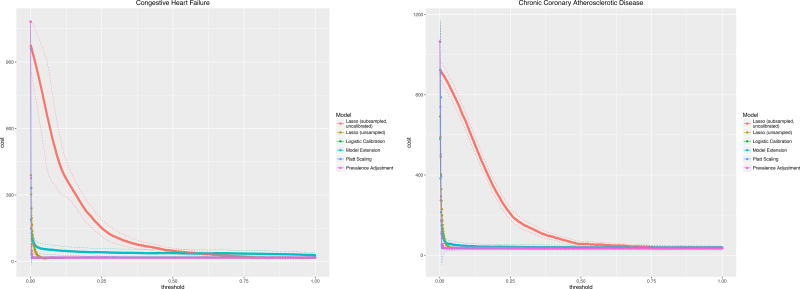
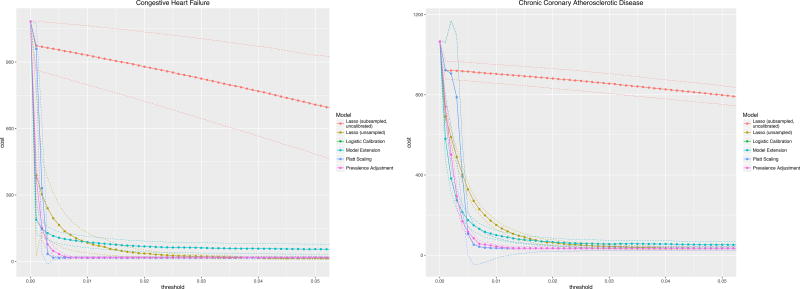
C-statistics by diagnosis ranged from 0.7 for all-cause readmission to 0.86 (0.78-0.93) for congestive heart failure. Logistic Calibration and Platt Scaling performed best and this difference required analyzing multiple metrics of calibration simultaneously, in particular Calibration Slopes and Intercepts. Clinical usefulness analyses provided optimal risk thresholds, which varied by reason for readmission, outcome prevalence, and calibration algorithm. Utility analyses also suggested maximum tolerable intervention costs, e.g., $1720 for all-cause readmissions based on a published cost of readmission of $11,862.
Choice of calibration method depends on availability of validation data and on performance. Improperly calibrated models may contribute to higher costs of intervention as measured via clinical usefulness. Decision-makers must understand underlying utilities or costs inherent in the use-case at hand to assess usefulness and will obtain the optimal risk threshold to trigger intervention with intervention cost limits as a result.
在将预测模型应用于新环境之前,校准和临床实用性的分析与区分度同样重要,但目前对此讨论较少。校准是模型对预测中实际结果发生率的反映。临床实用性是指在实践中使用预测模型的效用、成本和危害。通过决策分析方法对校准和选择最佳干预阈值进行分析,可能有助于最大限度地提高再入院风险和其他预防干预措施的效果。
选择一种实用的校准预测模型的方法,该方法只需最少的验证数据,并且在实践中表现良好。通过临床实用性分析评估校准不当对效用和成本的影响。
这是一项基于电子病历数据的观察性、回顾性队列研究,数据来自曼哈顿市一所城市学术中心的 12 万例住院患者。主要结局指标是 30 天内因三种原因(全因、充血性心力衰竭和慢性冠状动脉粥样硬化性疾病)的再入院。通过 L1-正则化逻辑回归进行预测建模。比较了几种校准方法,包括 Platt 缩放、逻辑校准和患病率调整。通过区分度(c 统计量)、校准(Spiegelhalter Z 统计量、分箱预测的均方根误差 [RMSE]、桑德斯和墨菲的 Brier 评分分辨率、校准斜率和截距)和临床实用性(效用项表示为成本)评估预测模型和校准的性能。还评估了应用每种校准算法所需的验证数据量。
根据诊断,c 统计量范围从全因再入院的 0.7 到充血性心力衰竭的 0.86(0.78-0.93)。逻辑校准和 Platt 缩放表现最好,这一差异需要同时分析校准的多个指标,特别是校准斜率和截距。临床实用性分析提供了最佳风险阈值,这些阈值因再入院原因、结果发生率和校准算法而异。效用分析还表明了最大可容忍干预成本,例如,基于发表的再入院成本 11862 美元,全因再入院的最高可容忍干预成本为 1720 美元。
校准方法的选择取决于验证数据的可用性和性能。校准不当的模型可能会导致干预成本增加,这可以通过临床实用性来衡量。决策者必须了解手头用例中固有的效用或成本,以评估效用,并根据干预成本限制获得最佳风险阈值,以触发干预。