Barnett L A, Lewis M, Mallen C D, Peat G
Arthritis Research UK Primary Care Centre, Research Institute for Primary Care and Health Sciences, Keele University, Staffordshire, ST5 5BG, UK.
Trials. 2017 Dec 4;18(1):585. doi: 10.1186/s13063-017-2329-1.
Selection bias is a concern when designing cluster randomised controlled trials (c-RCT). Despite addressing potential issues at the design stage, bias cannot always be eradicated from a trial design. The application of bias analysis presents an important step forward in evaluating whether trial findings are credible. The aim of this paper is to give an example of the technique to quantify potential selection bias in c-RCTs.
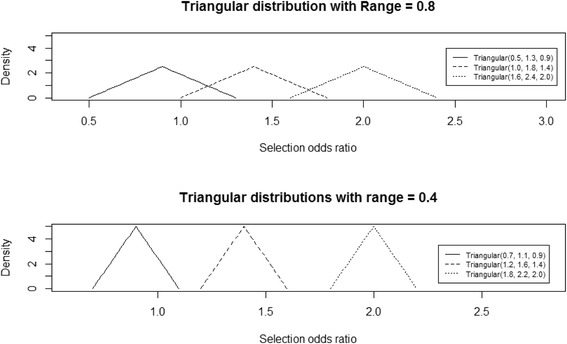
This analysis uses data from the Primary care Osteoarthritis Screening Trial (POST). The primary aim of this trial was to test whether screening for anxiety and depression, and providing appropriate care for patients consulting their GP with osteoarthritis would improve clinical outcomes. Quantitative bias analysis is a seldom-used technique that can quantify types of bias present in studies. Due to lack of information on the selection probability, probabilistic bias analysis with a range of triangular distributions was also used, applied at all three follow-up time points; 3, 6, and 12 months post consultation. A simple bias analysis was also applied to the study.
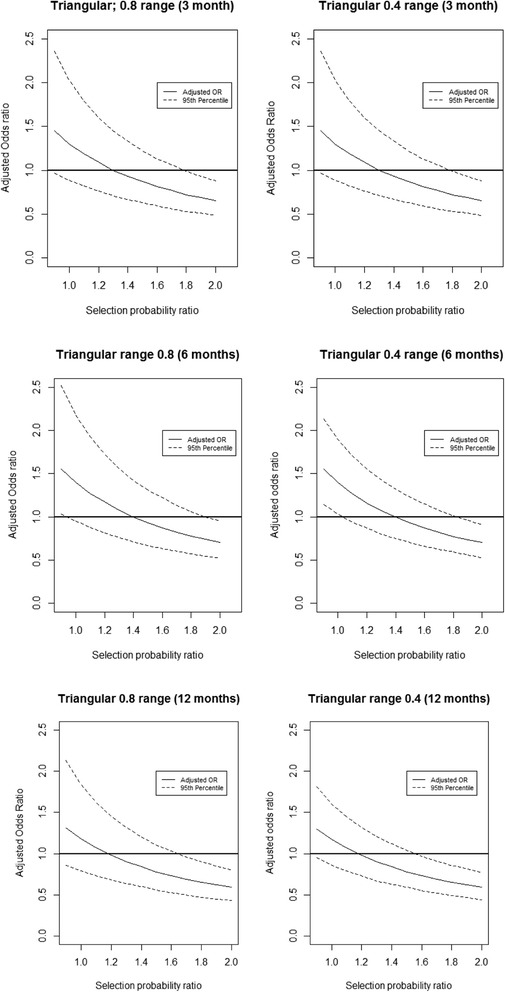
Worse pain outcomes were observed among intervention participants than control participants (crude odds ratio at 3, 6, and 12 months: 1.30 (95% CI 1.01, 1.67), 1.39 (1.07, 1.80), and 1.17 (95% CI 0.90, 1.53), respectively). Probabilistic bias analysis suggested that the observed effect became statistically non-significant if the selection probability ratio was between 1.2 and 1.4. Selection probability ratios of > 1.8 were needed to mask a statistically significant benefit of the intervention.
The use of probabilistic bias analysis in this c-RCT suggested that worse outcomes observed in the intervention arm could plausibly be attributed to selection bias. A very large degree of selection of bias was needed to mask a beneficial effect of intervention making this interpretation less plausible.
在设计整群随机对照试验(c-RCT)时,选择偏倚是一个需要关注的问题。尽管在设计阶段解决了潜在问题,但偏倚并非总能从试验设计中消除。偏倚分析的应用是评估试验结果是否可信的重要一步。本文旨在给出一个量化c-RCT中潜在选择偏倚技术的示例。
本分析使用了初级保健骨关节炎筛查试验(POST)的数据。该试验的主要目的是测试焦虑和抑郁筛查以及为因骨关节炎咨询全科医生的患者提供适当护理是否能改善临床结局。定量偏倚分析是一种很少使用的技术,可量化研究中存在的偏倚类型。由于缺乏选择概率的信息,还使用了一系列三角分布的概率偏倚分析,应用于所有三个随访时间点:咨询后3个月、6个月和12个月。还对该研究进行了简单的偏倚分析。
干预组参与者的疼痛结局比对照组参与者更差(3个月、6个月和12个月时的粗比值比分别为1.30(95%CI 1.01,1.67)、1.39(1.07,1.80)和1.17(95%CI 0.90,1.53))。概率偏倚分析表明,如果选择概率比在1.2至1.4之间,观察到的效应在统计学上变得不显著。需要>1.8的选择概率比来掩盖干预的统计学显著益处。
在这项c-RCT中使用概率偏倚分析表明,干预组中观察到的较差结局可能合理地归因于选择偏倚。需要非常大程度的选择偏倚来掩盖干预的有益效果,这使得这种解释不太可信。