Cai Menglan, Li Limin
School of Mathematics and Statistics, Xi'an Jiaotong University, Xianning West 28, Xi'an, China.
BMC Med Genomics. 2017 Dec 21;10(Suppl 4):75. doi: 10.1186/s12920-017-0306-x.
The Cancer Genome Atlas (TCGA) has collected transcriptome, genome and epigenome information for over 20 cancers from thousands of patients. The availability of these diverse data types makes it necessary to combine these data to capture the heterogeneity of biological processes and phenotypes and further identify homogeneous subtypes for cancers such as breast cancer. Many multi-view clustering approaches are proposed to discover clusters across different data types. The problem is challenging when different data types show poor agreement of clustering structure.
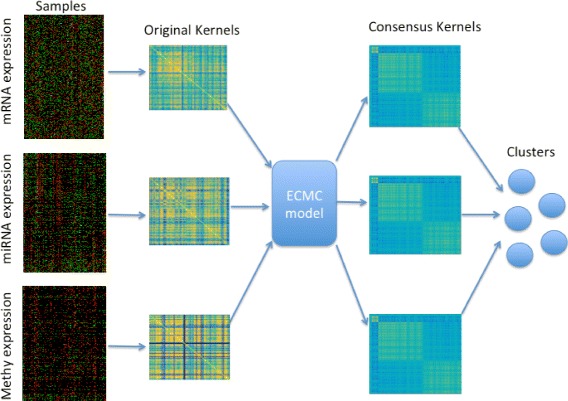
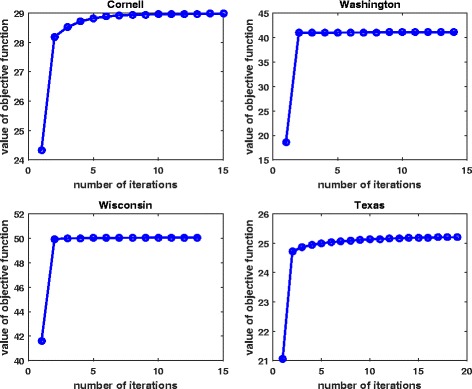
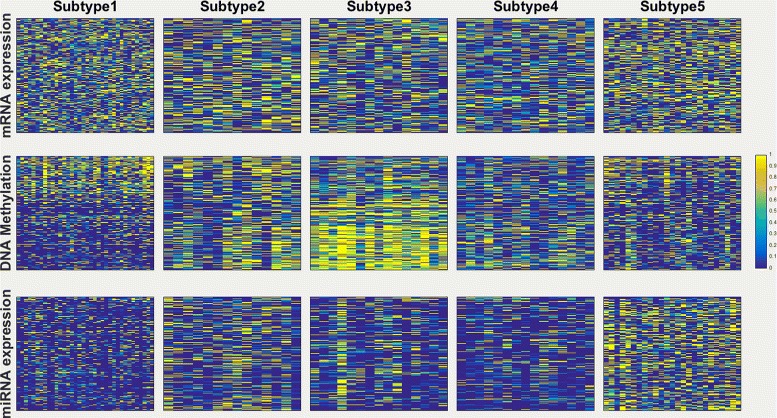
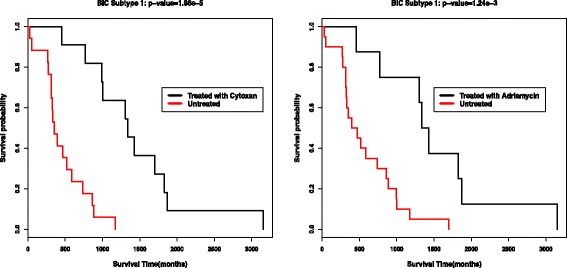
In this work, we first propose a multi-view clustering approach with consensus (CMC), which tries to find consensus kernels among views by using Hilbert Schmidt Independence Criterion. To tackle the problem when poor agreement among views exists, we further propose a multi-view clustering approach with enhanced consensus (ECMC) to solve this problem by decomposing the kernel information in each view into a consensus part and a disagreement part. The consensus parts for different views are supposed to be similar, and the disagreement parts should be independent with the consensus parts. Both the CMC and ECMC models can be solved by alternative updating with semi-definite programming. Our experiments on both simulation datasets and real-world benchmark datasets show that ECMC model could achieve higher clustering accuracies than other state-of-art multi-view clustering approaches. We also apply the ECMC model to integrate mRNA expression, DNA methylation and microRNA (miRNA) expression data for five cancer data sets, and the survival analysis show that our ECMC model outperforms other methods when identifying cancer subtypes. By Fisher's combination test method, we found that three computed subtypes roughly correspond to three known breast cancer subtypes including luminal B, HER2 and basal-like subtypes.
Integrating heterogeneous TCGA datasets by our proposed multi-view clustering approach ECMC could effectively identify cancer subtypes.
癌症基因组图谱(TCGA)已收集了数千名患者的20多种癌症的转录组、基因组和表观基因组信息。这些多样的数据类型使得有必要将这些数据结合起来,以捕捉生物过程和表型的异质性,并进一步识别乳腺癌等癌症的同质亚型。许多多视图聚类方法被提出来发现不同数据类型中的聚类。当不同数据类型的聚类结构一致性较差时,这个问题具有挑战性。
在这项工作中,我们首先提出了一种具有一致性的多视图聚类方法(CMC),该方法试图通过使用希尔伯特 - 施密特独立性准则在视图之间找到一致核。为了解决视图之间一致性较差的问题,我们进一步提出了一种具有增强一致性的多视图聚类方法(ECMC),通过将每个视图中的核信息分解为一个一致部分和一个不一致部分来解决这个问题。不同视图的一致部分应该相似,并且不一致部分应该与一致部分独立。CMC和ECMC模型都可以通过半定规划的交替更新来求解。我们在模拟数据集和真实世界基准数据集上的实验表明,ECMC模型比其他现有的多视图聚类方法能够获得更高的聚类准确率。我们还将ECMC模型应用于整合五个癌症数据集的mRNA表达、DNA甲基化和 microRNA(miRNA)表达数据,生存分析表明,我们的ECMC模型在识别癌症亚型方面优于其他方法。通过费舍尔组合检验方法,我们发现三个计算出的亚型大致对应于三种已知的乳腺癌亚型,包括管腔B型、HER2型和基底样亚型。
通过我们提出的多视图聚类方法ECMC整合异质的TCGA数据集可以有效地识别癌症亚型。