Department of Genetics, Stanford University School of Medicine, Stanford, CA, USA.
Department of Mathematics, California Institute of Technology, Pasadena, CA, USA.
Sci Rep. 2018 Feb 19;8(1):3291. doi: 10.1038/s41598-018-21444-4.
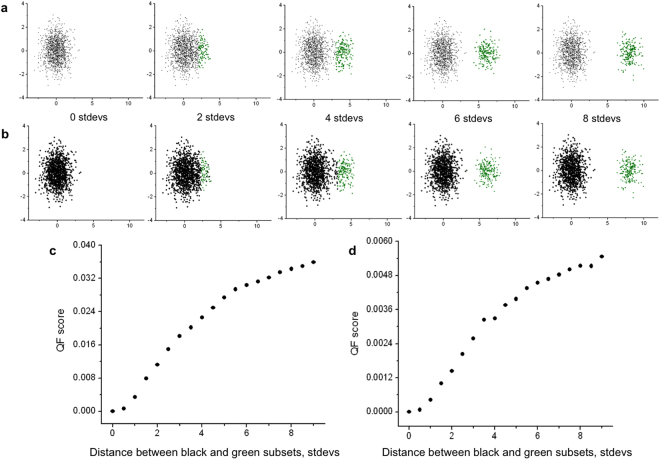
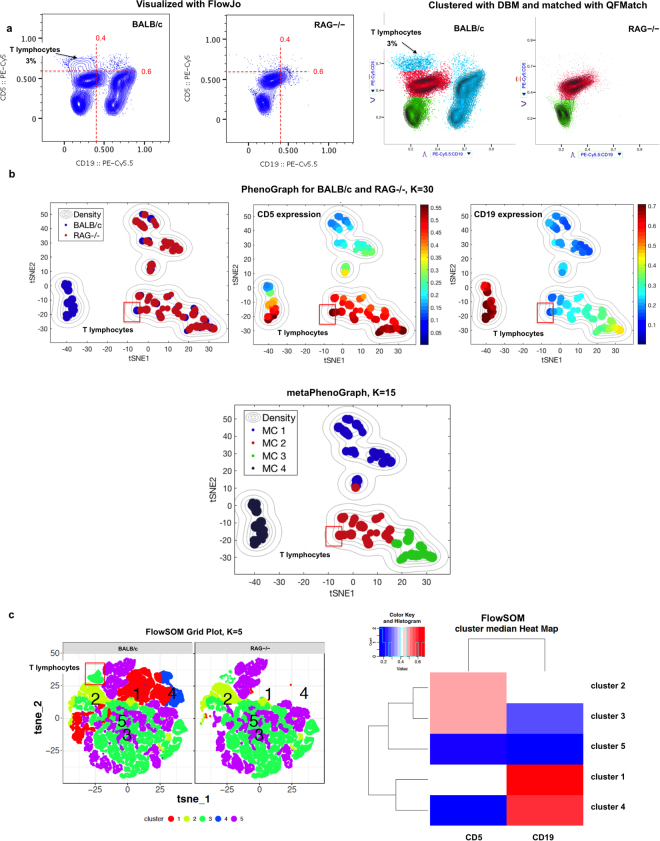
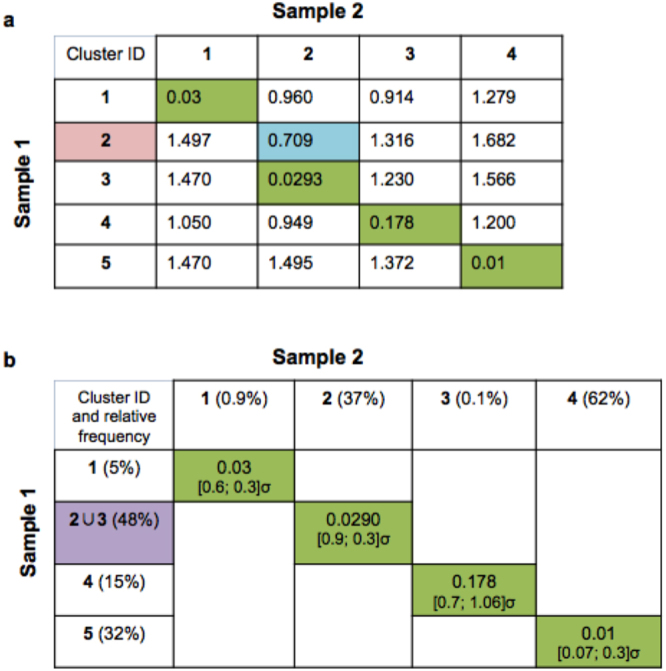
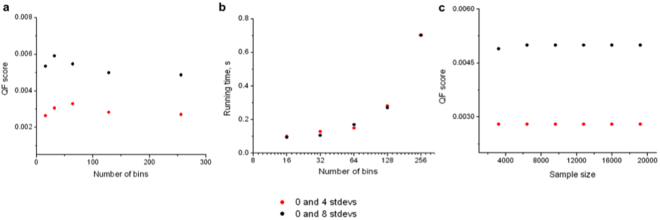
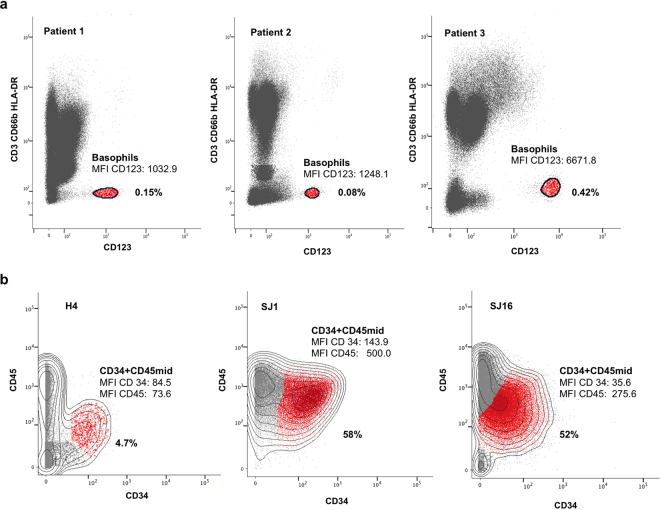
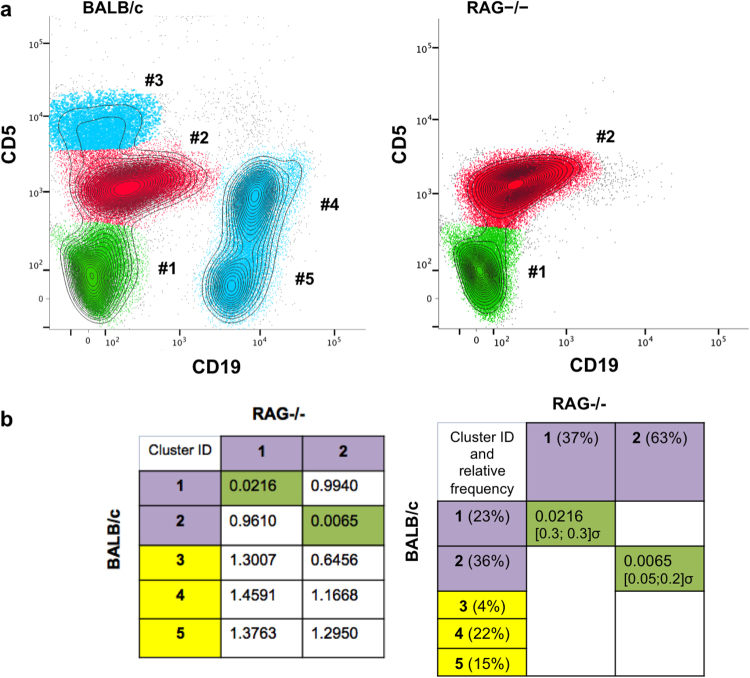
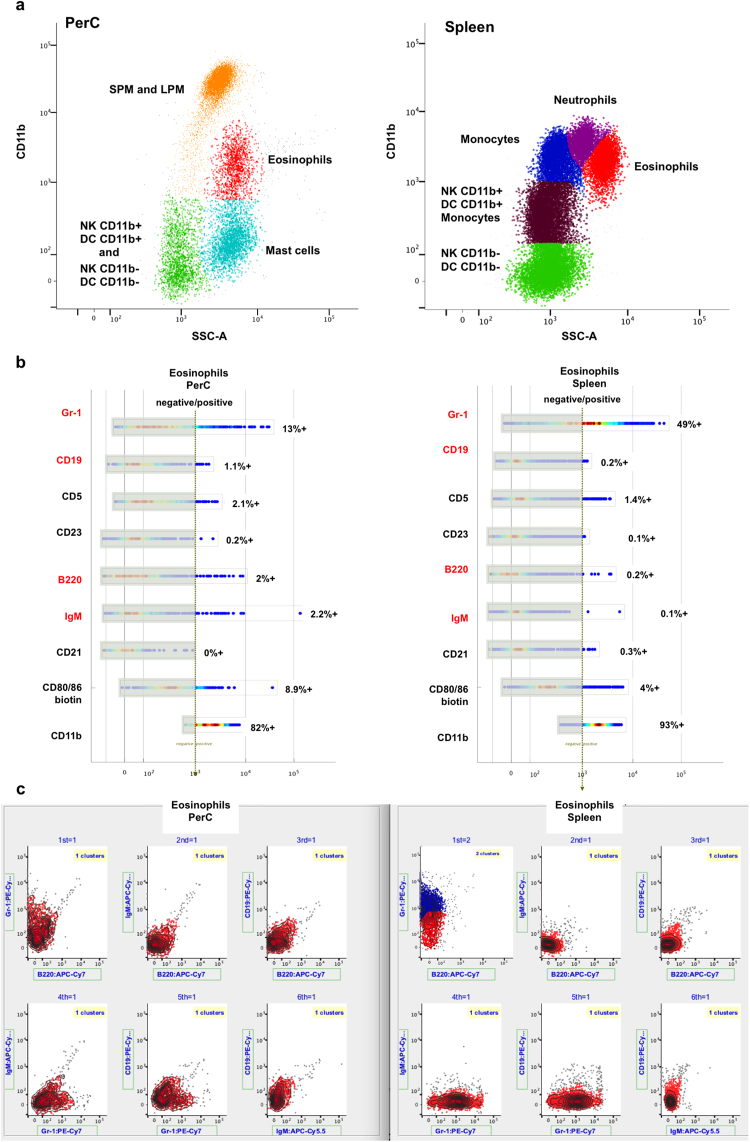
Part of the flow/mass cytometry data analysis process is aligning (matching) cell subsets between relevant samples. Current methods address this cluster-matching problem in ways that are either computationally expensive, affected by the curse of dimensionality, or fail when population patterns significantly vary between samples. Here, we introduce a quadratic form (QF)-based cluster matching algorithm (QFMatch) that is computationally efficient and accommodates cases where population locations differ significantly (or even disappear or appear) from sample to sample. We demonstrate the effectiveness of QFMatch by evaluating sample datasets from immunology studies. The algorithm is based on a novel multivariate extension of the quadratic form distance for the comparison of flow cytometry data sets. We show that this QF distance has attractive computational and statistical properties that make it well suited for analysis tasks that involve the comparison of flow/mass cytometry samples.
流式/质谱细胞术数据分析流程的一部分是在相关样本之间对齐(匹配)细胞亚群。目前的方法在解决聚类匹配问题时存在计算成本高、受维度诅咒影响或在样本间群体模式差异显著时失败等问题。在这里,我们引入了一种基于二次型(QF)的聚类匹配算法(QFMatch),该算法计算效率高,适用于群体位置在样本间差异显著(甚至消失或出现)的情况。我们通过评估免疫学研究中的样本数据集来证明 QFMatch 的有效性。该算法基于二次型距离的一种新的多变量扩展,用于比较流式细胞术数据集。我们表明,这种 QF 距离具有吸引人的计算和统计特性,非常适合涉及流式/质谱细胞术样本比较的分析任务。