Institute of Human Genetics and Medical Genetics, Charité - Universitätsmedizin Berlin, corporate member of Freie Universität Berlin, Humboldt-Universität zu Berlin, and Berlin Institute of Health, Berlin, Germany.
Institute for Genomic Statistics and Bioinformatics, University Hospital Bonn, Rheinische Friedrich-Wilhelms-Universität Bonn, Bonn, Germany.
J Inherit Metab Dis. 2018 May;41(3):533-539. doi: 10.1007/s10545-018-0174-3. Epub 2018 Apr 5.
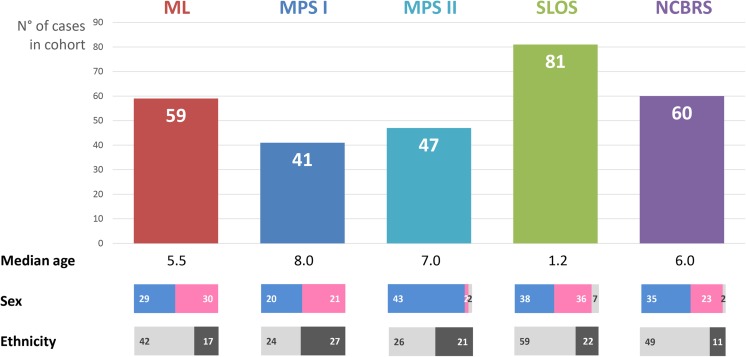
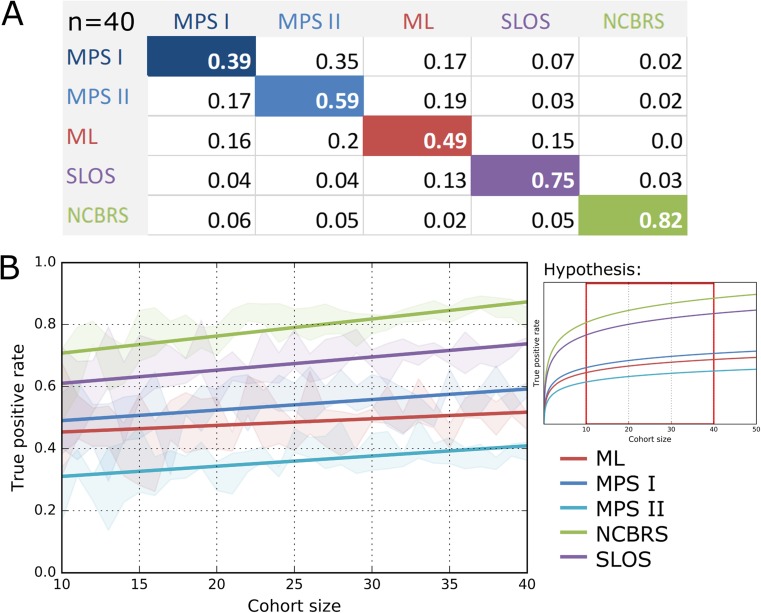
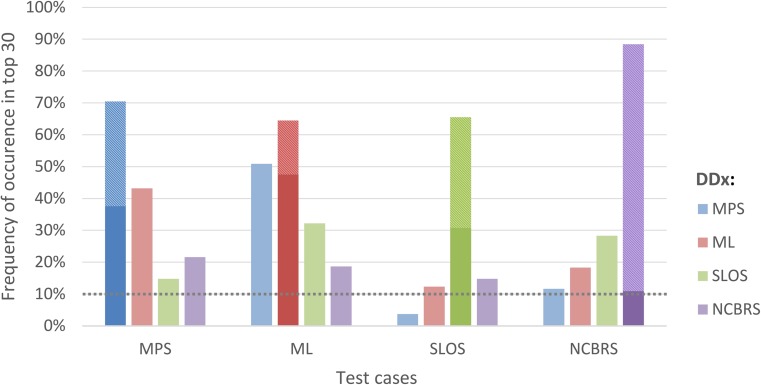
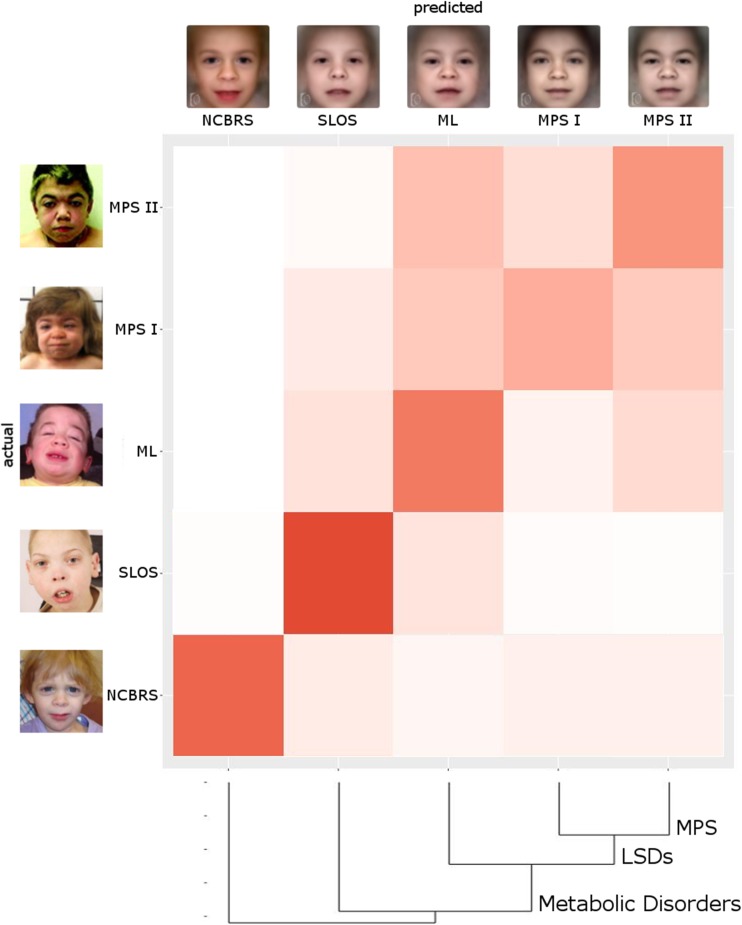
Significant improvements in automated image analysis have been achieved in recent years and tools are now increasingly being used in computer-assisted syndromology. However, the ability to recognize a syndromic facial gestalt might depend on the syndrome and may also be confounded by severity of phenotype, size of available training sets, ethnicity, age, and sex. Therefore, benchmarking and comparing the performance of deep-learned classification processes is inherently difficult. For a systematic analysis of these influencing factors we chose the lysosomal storage diseases mucolipidosis as well as mucopolysaccharidosis type I and II that are known for their wide and overlapping phenotypic spectra. For a dysmorphic comparison we used Smith-Lemli-Opitz syndrome as another inborn error of metabolism and Nicolaides-Baraitser syndrome as another disorder that is also characterized by coarse facies. A classifier that was trained on these five cohorts, comprising 289 patients in total, achieved a mean accuracy of 62%. We also developed a simulation framework to analyze the effect of potential confounders, such as cohort size, age, sex, or ethnic background on the distinguishability of phenotypes. We found that the true positive rate increases for all analyzed disorders for growing cohorts (n = [10...40]) while ethnicity and sex have no significant influence. The dynamics of the accuracies strongly suggest that the maximum distinguishability is a phenotype-specific value, which has not been reached yet for any of the studied disorders. This should also be a motivation to further intensify data sharing efforts, as computer-assisted syndrome classification can still be improved by enlarging the available training sets.
近年来,自动化图像分析取得了显著的进展,现在越来越多的工具被用于计算机辅助综合征学。然而,识别综合征性面部整体特征的能力可能取决于综合征,并且还可能受到表型严重程度、可用训练集大小、种族、年龄和性别的影响而变得复杂。因此,基准测试和比较深度学习分类过程的性能本质上是困难的。为了系统地分析这些影响因素,我们选择了溶酶体贮积症粘脂贮积症以及粘多糖贮积症 I 型和 II 型,这些疾病的表型谱广泛且重叠。为了进行畸形比较,我们使用 Smith-Lemli-Opitz 综合征作为另一种先天性代谢缺陷,以及 Nicolaides-Baraitser 综合征作为另一种也以粗面为特征的疾病。一个经过这五个队列(总共 289 名患者)训练的分类器,平均准确率为 62%。我们还开发了一个模拟框架来分析潜在混杂因素(如队列大小、年龄、性别或种族背景)对表型可区分性的影响。我们发现,对于所有分析的疾病,随着队列的增加(n = [10...40]),真阳性率增加,而种族和性别没有显著影响。准确性的动态强烈表明,最大可区分性是一个特定于表型的数值,对于任何研究的疾病都尚未达到。这也应该是进一步加强数据共享努力的动力,因为通过扩大可用的训练集,可以进一步提高计算机辅助综合征分类的能力。