Song Jie, Zhai Jingjing, Bian Enze, Song Yujia, Yu Jiantao, Ma Chuang
State Key Laboratory of Crop Stress Biology for Arid Areas, Center of Bioinformatics, College of Life Sciences, Northwest A&F University, Shaanxi, China.
Key Laboratory of Biology and Genetics Improvement of Maize in Arid Area of Northwest Region, Ministry of Agriculture, Northwest A&F University, Shaanxi, China.
Front Plant Sci. 2018 Apr 18;9:519. doi: 10.3389/fpls.2018.00519. eCollection 2018.
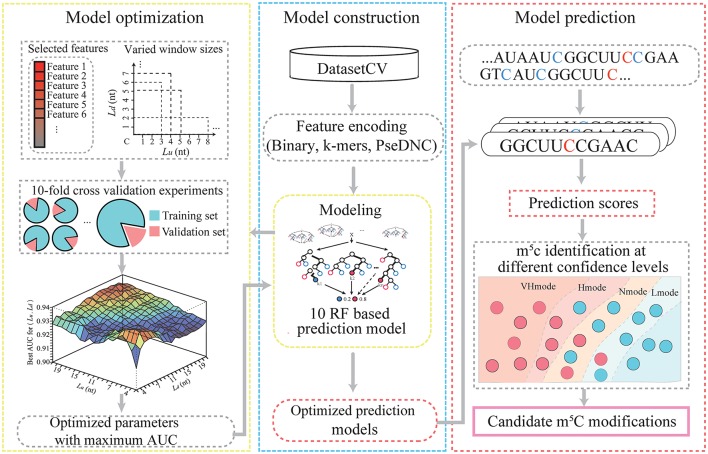
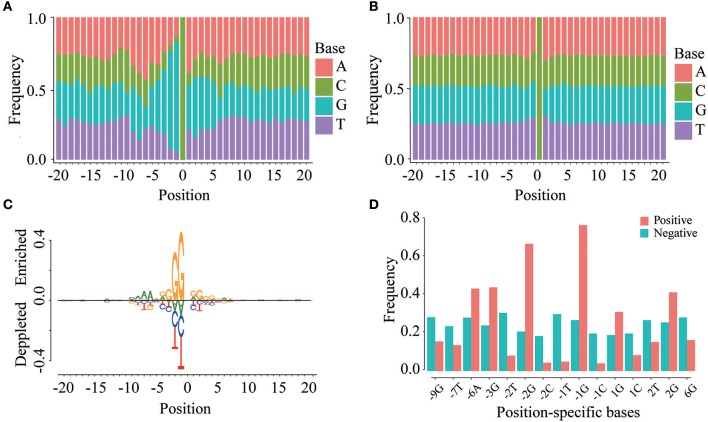
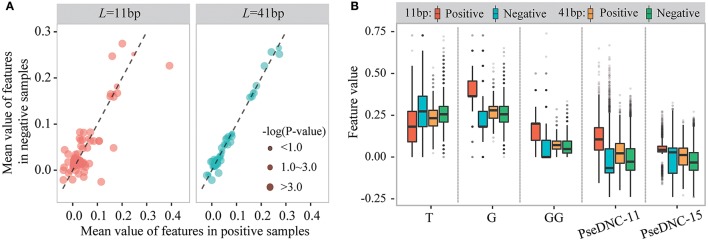
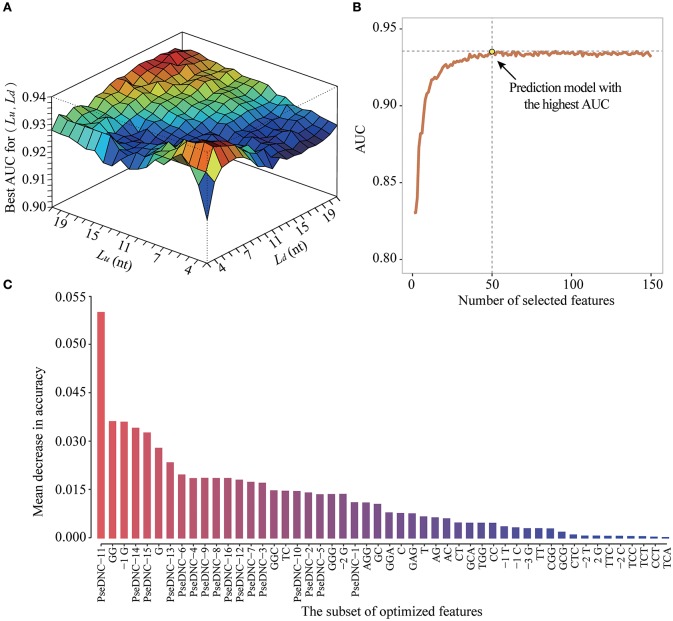
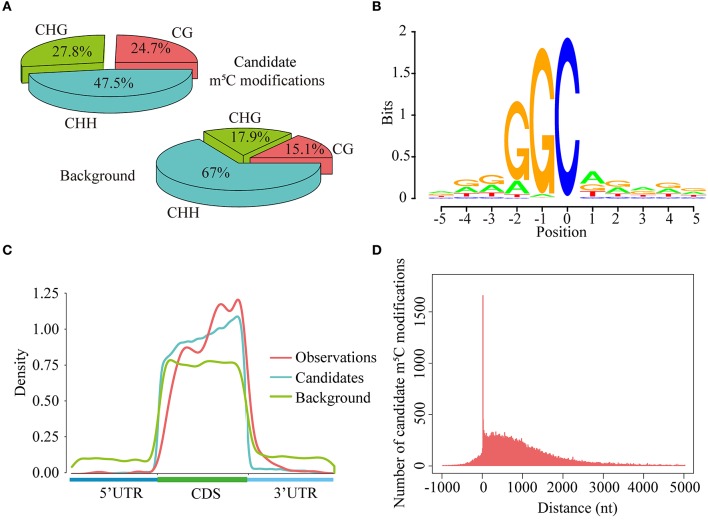
The emergence of epitranscriptome opened a new chapter in gene regulation. 5-methylcytosine (mC), as an important post-transcriptional modification, has been identified to be involved in a variety of biological processes such as subcellular localization and translational fidelity. Though high-throughput experimental technologies have been developed and applied to profile mC modifications under certain conditions, transcriptome-wide studies of mC modifications are still hindered by the dynamic and reversible nature of mC and the lack of computational prediction methods. In this study, we introduced PEA-m5C, a machine learning-based mC predictor trained with features extracted from the flanking sequence of mC modifications. PEA-m5C yielded an average AUC (area under the receiver operating characteristic) of 0.939 in 10-fold cross-validation experiments based on known mC modifications. A rigorous independent testing showed that PEA-m5C (Accuracy [Acc] = 0.835, Matthews correlation coefficient [MCC] = 0.688) is remarkably superior to the recently developed mC predictor iRNAm5C-PseDNC (Acc = 0.665, MCC = 0.332). PEA-m5C has been applied to predict candidate mC modifications in annotated transcripts. Further analysis of these mC candidates showed that 4nt downstream of the translational start site is the most frequently methylated position. PEA-m5C is freely available to academic users at: https://github.com/cma2015/PEA-m5C.
表观转录组的出现开启了基因调控的新篇章。5-甲基胞嘧啶(mC)作为一种重要的转录后修饰,已被证实参与多种生物学过程,如亚细胞定位和翻译保真度。尽管高通量实验技术已得到发展并应用于在特定条件下描绘mC修饰,但mC修饰的全转录组研究仍受到mC的动态可逆性质以及缺乏计算预测方法的阻碍。在本研究中,我们引入了PEA-m5C,这是一种基于机器学习的mC预测器,使用从mC修饰侧翼序列提取的特征进行训练。在基于已知mC修饰的10折交叉验证实验中,PEA-m5C的平均AUC(受试者工作特征曲线下面积)为0.939。严格的独立测试表明,PEA-m5C(准确率[Acc]=0.835,马修斯相关系数[MCC]=0.688)明显优于最近开发的mC预测器iRNAm5C-PseDNC(Acc = 0.665,MCC = 0.332)。PEA-m5C已被应用于预测注释转录本中的候选mC修饰。对这些mC候选物的进一步分析表明,翻译起始位点下游4nt是最常发生甲基化的位置。学术用户可通过以下链接免费获取PEA-m5C:https://github.com/cma2015/PEA-m5C 。