Computational and Analytical Sciences, Rothamsted Research, Harpenden, AL5 2JQ, UK.
BMC Bioinformatics. 2018 Jul 9;19(Suppl 7):199. doi: 10.1186/s12859-018-2173-7.
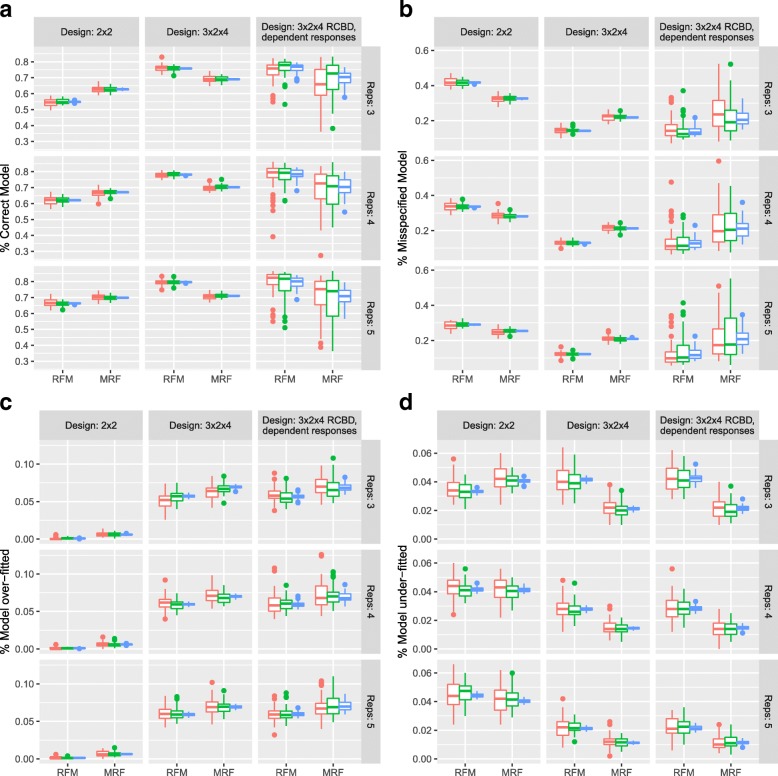
With ever increasing accessibility to high throughput technologies, more complex treatment structures can be assessed in a variety of 'omics applications. This adds an extra layer of complexity to the analysis and interpretation, in particular when inferential univariate methods are applied en masse. It is well-known that mass univariate testing suffers from multiplicity issues and although this has been well documented for simple comparative tests, few approaches have focussed on more complex explanatory structures.
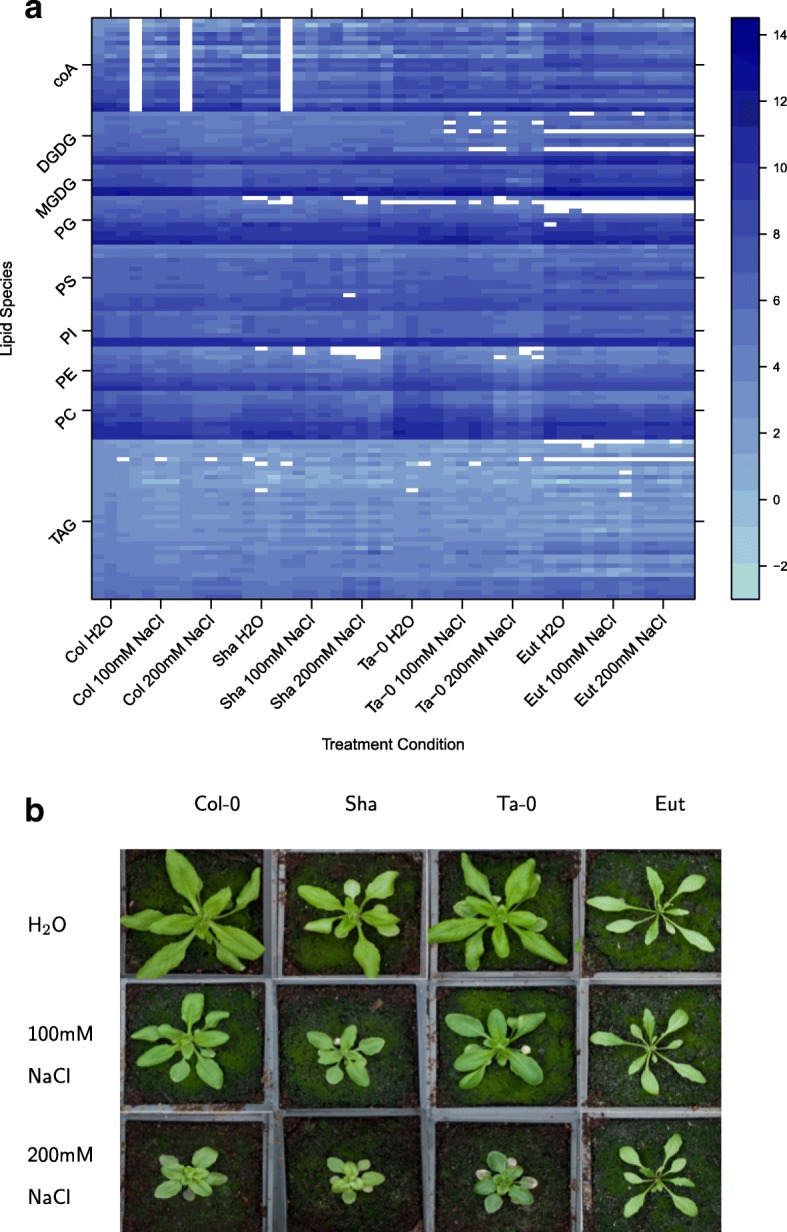
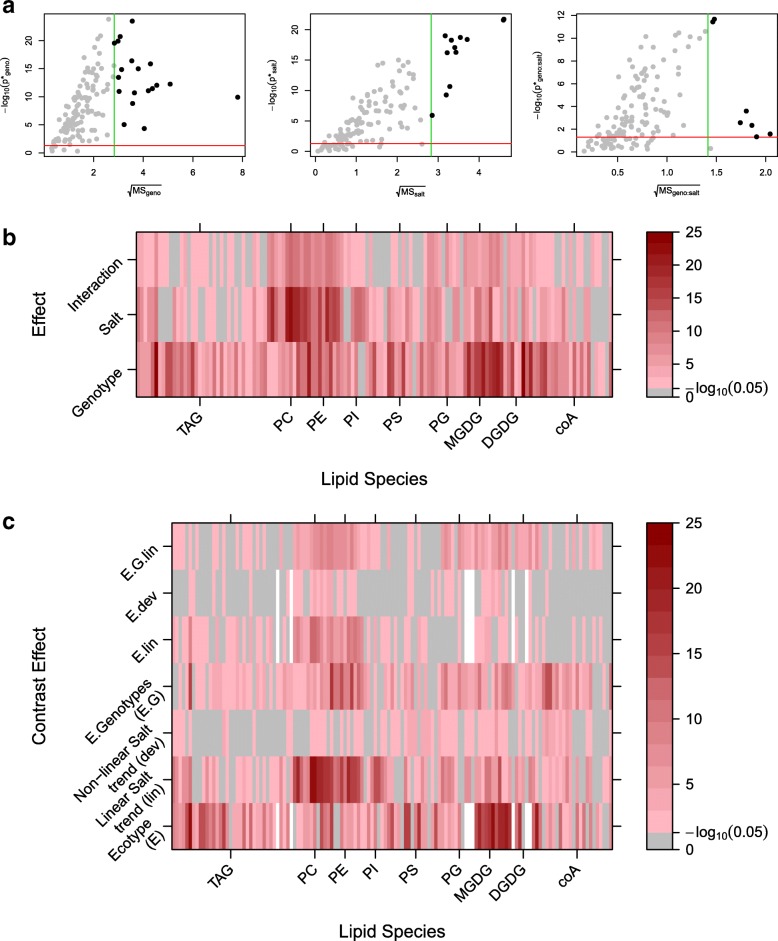
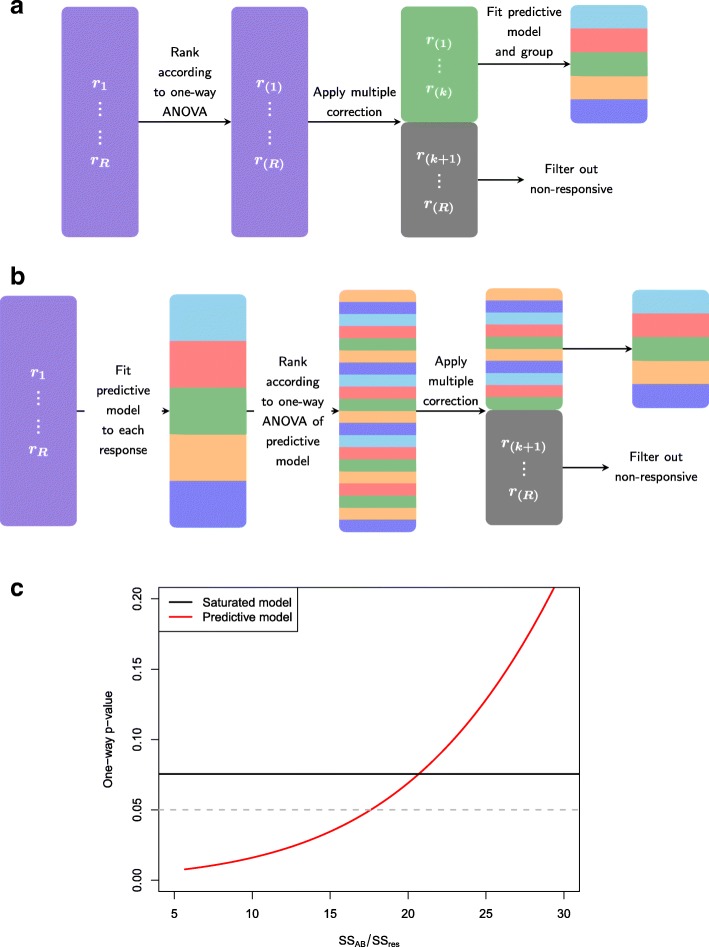
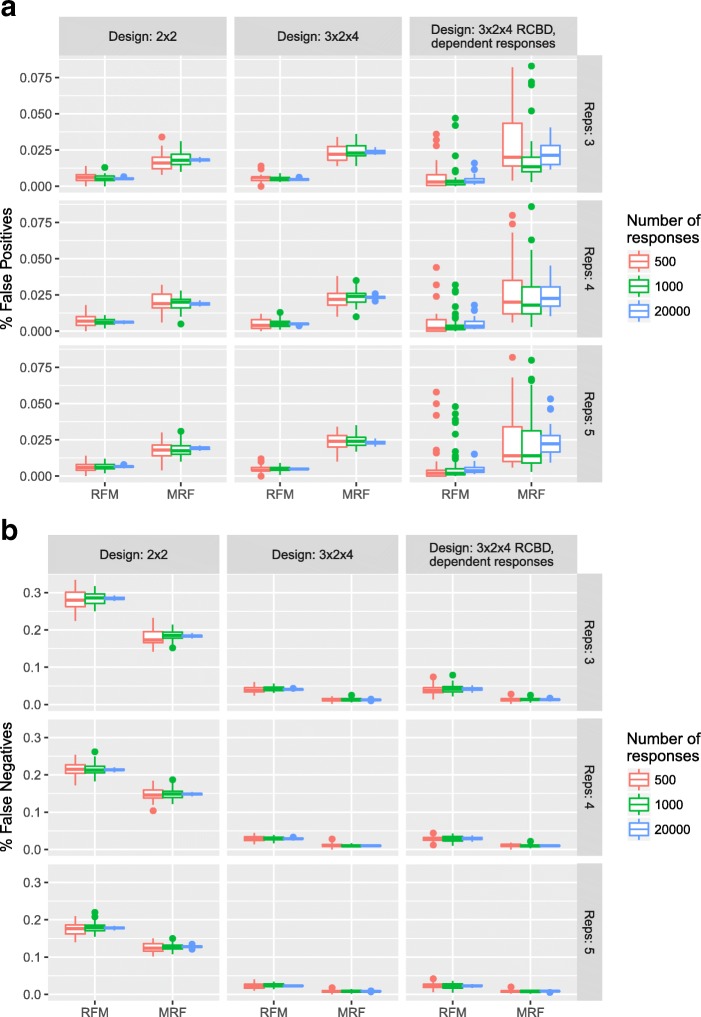
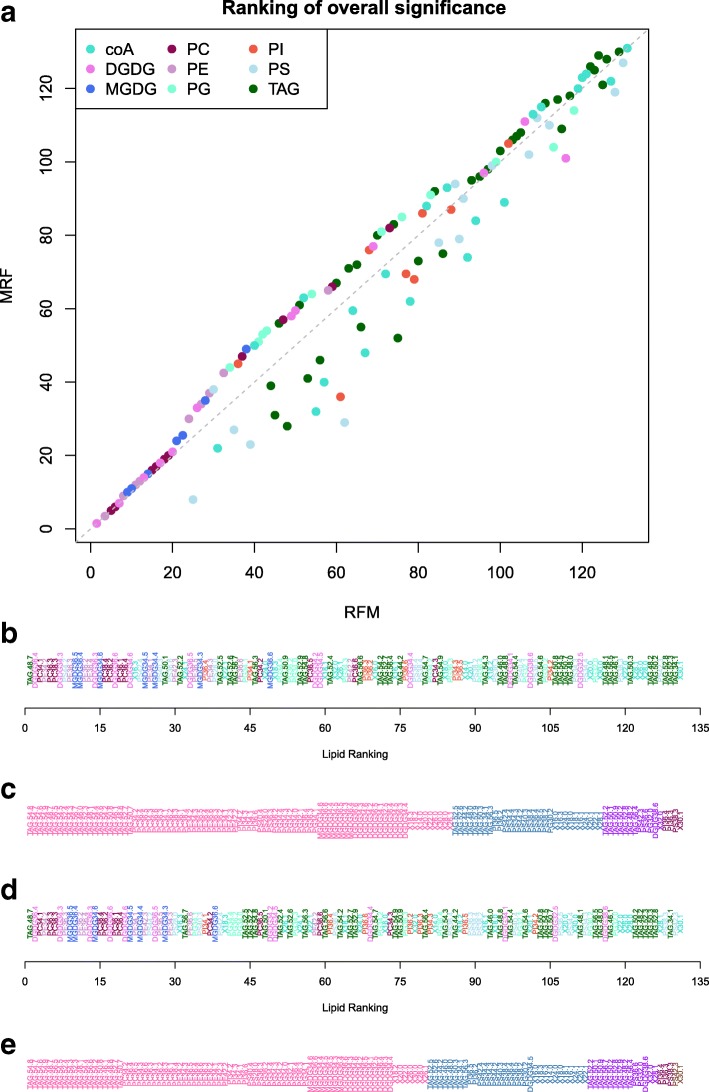
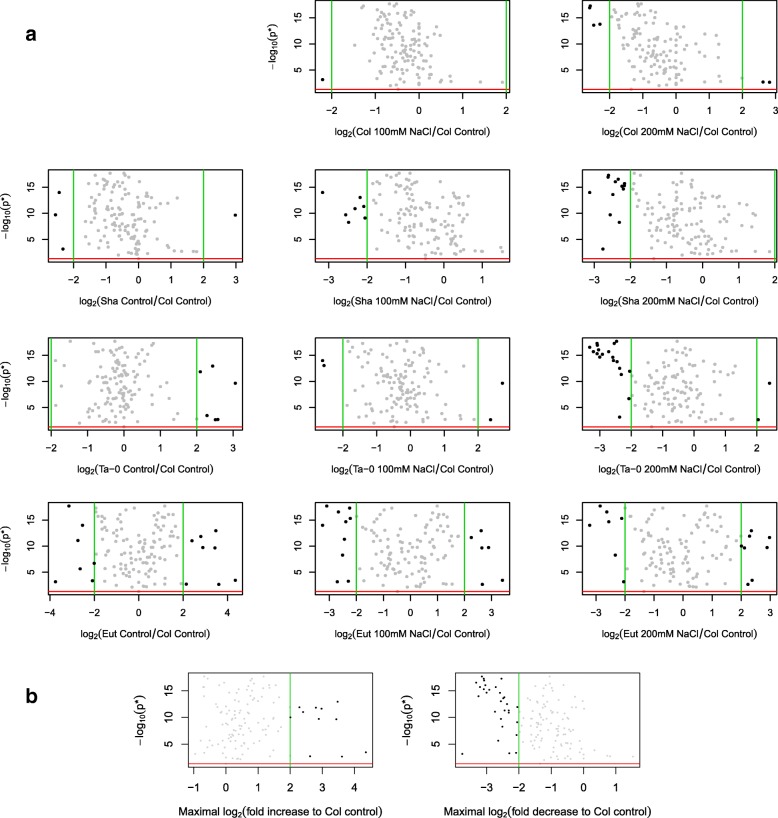
Two frameworks are introduced incorporating corrections for multiplicity whilst maintaining appropriate structure in the explanatory variables. Within this paradigm, a choice has to be made as to whether multiplicity corrections should be applied to the saturated model, putting emphasis on controlling the rate of false positives, or to the predictive model, where emphasis is on model selection. This choice has implications for both the ranking and selection of the response variables identified as differentially expressed. The theoretical difference is demonstrated between the two approaches along with an empirical study of lipid composition in Arabidopsis under differing levels of salt stress.
Multiplicity corrections have an inherent weakness when the full explanatory structure is not properly incorporated. Although a unifying 'single best' recommendation is not provided, two reasonable alternatives are provided and the applicability of these approaches is discussed for different scenarios where the aims of analysis will differ. The key result is that the point at which multiplicity is incorporated into the analysis will fundamentally change the interpretation of the results, and the choice of approach should therefore be driven by the specific aims of the experiment.
随着高通量技术的不断普及,越来越多的复杂治疗结构可以在各种“组学”应用中进行评估。这给分析和解释增加了一个额外的复杂性层次,特别是当大量应用推断性单变量方法时。众所周知,大规模单变量检验存在多重性问题,尽管这在简单的比较检验中已经得到了很好的记录,但很少有方法关注更复杂的解释结构。
引入了两种框架,在保持解释变量适当结构的同时,对多重性进行校正。在此范式中,必须在饱和模型(强调控制假阳性率)或预测模型(强调模型选择)中选择是否应用多重性校正。这一选择对被确定为差异表达的响应变量的排名和选择都有影响。本文沿着两个方向对这两种方法进行了理论上的比较,同时还对拟南芥在不同盐胁迫水平下的脂质组成进行了实证研究。
当未正确纳入完整的解释结构时,多重性校正存在固有弱点。尽管没有提供统一的“最佳”推荐,但提供了两种合理的替代方案,并讨论了这些方法在分析目标不同的不同情况下的适用性。关键结果是,将多重性纳入分析的程度将从根本上改变结果的解释,因此方法的选择应取决于实验的具体目标。