Department of Genomics, Faculty of Biotechnology, University of Wrocław, Wrocław, Poland.
PLoS One. 2018 Aug 9;13(8):e0201715. doi: 10.1371/journal.pone.0201715. eCollection 2018.
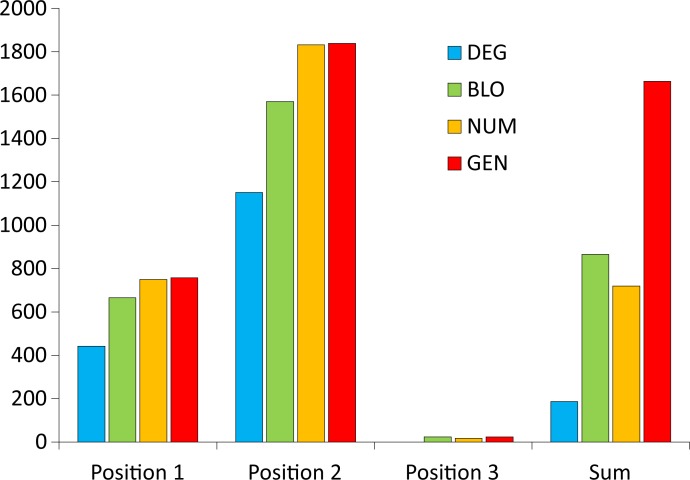
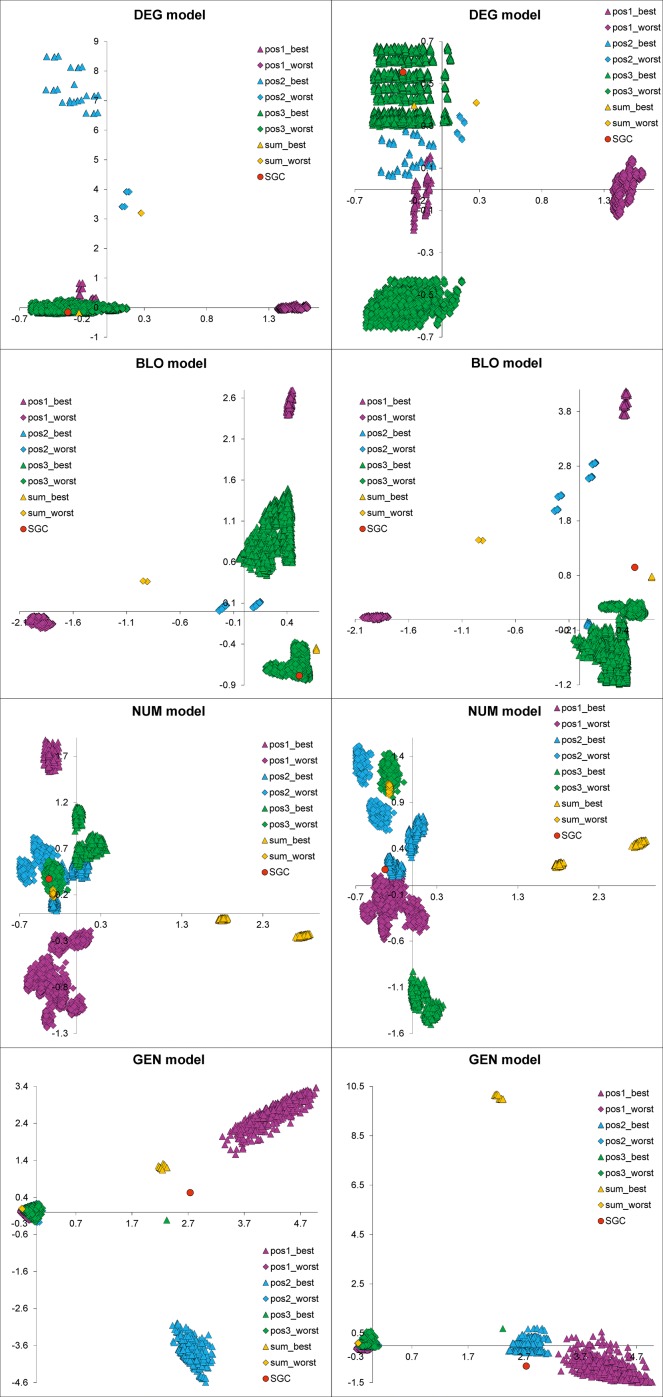
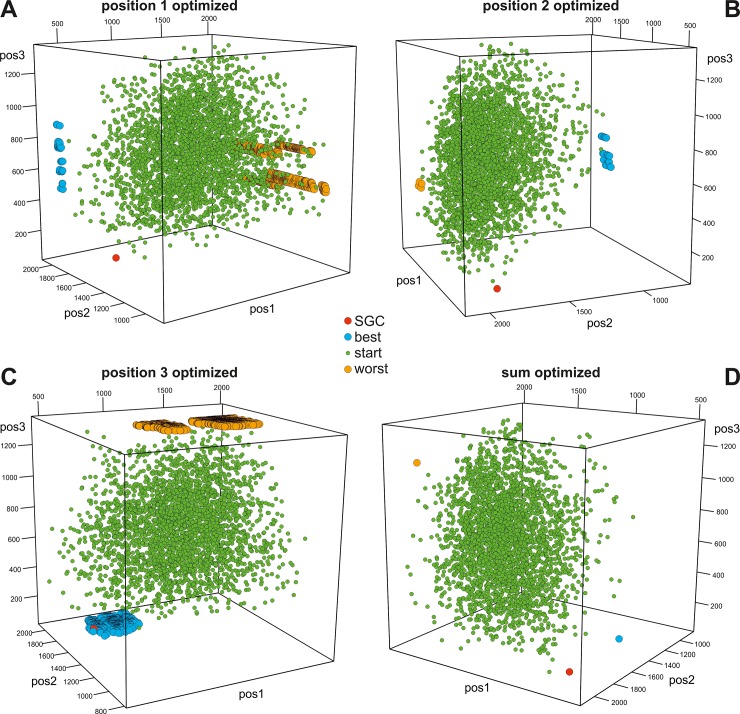
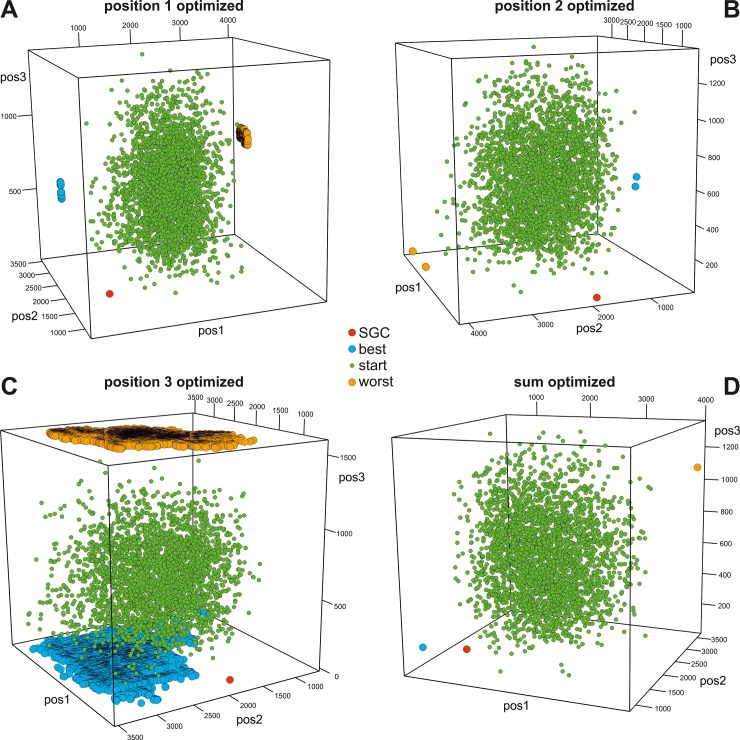
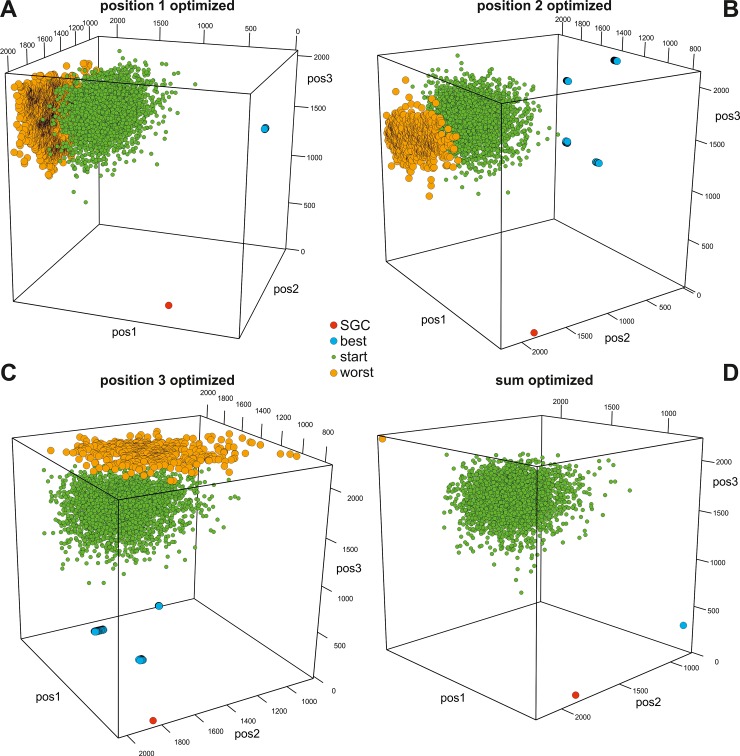
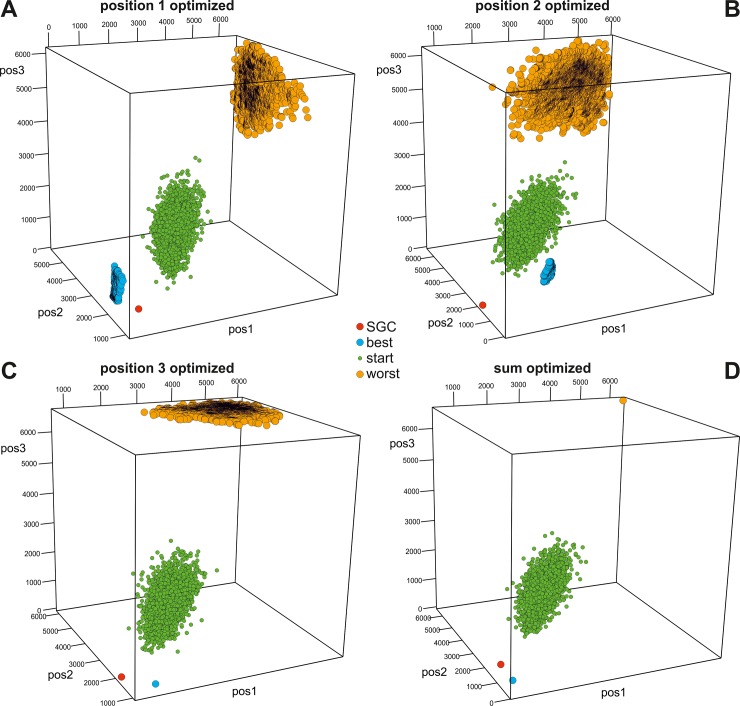
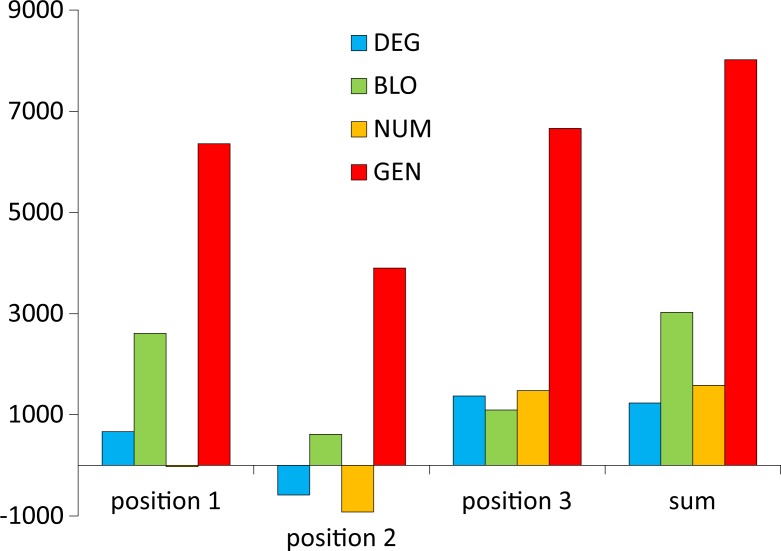
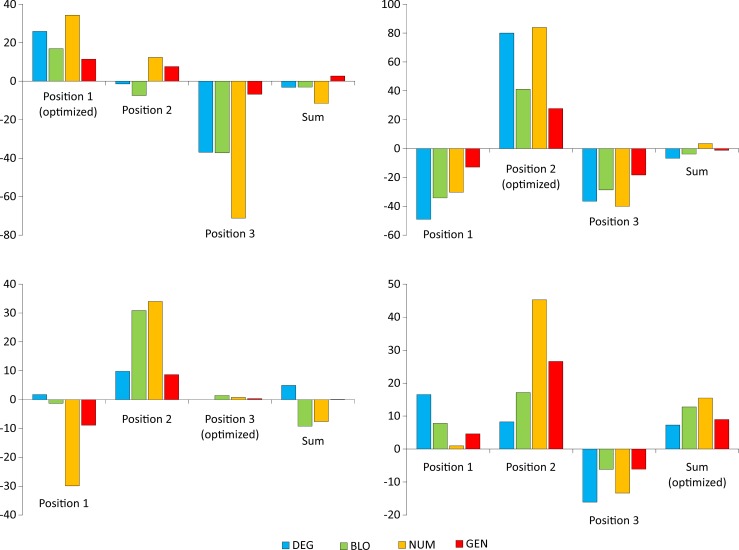
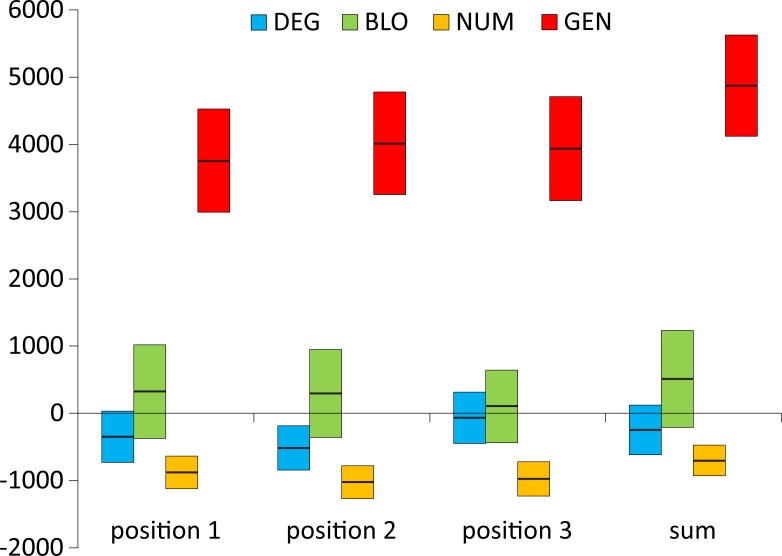
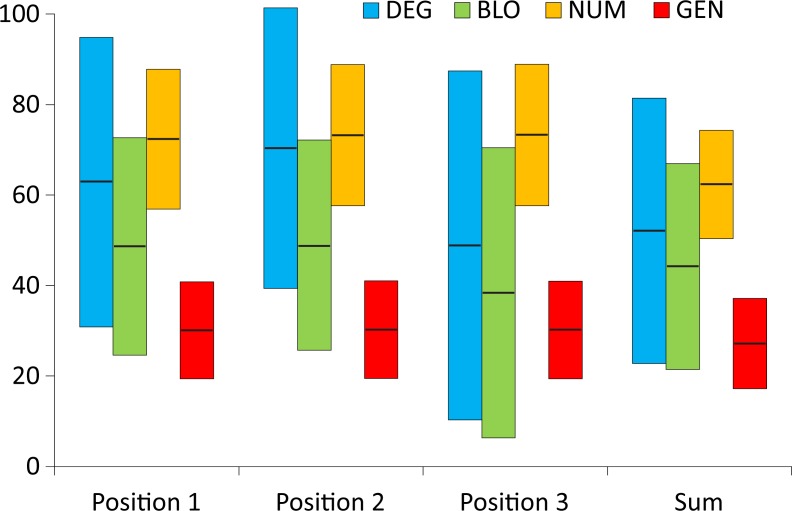
Many biological systems are typically examined from the point of view of adaptation to certain conditions or requirements. One such system is the standard genetic code (SGC), which generally minimizes the cost of amino acid replacements resulting from mutations or mistranslations. However, no full consensus has been reached on the factors that caused the evolution of this feature. One of the hypotheses suggests that code optimality was directly selected as an advantage to preserve information about encoded proteins. An important feature that should be considered when studying the SGC is the different roles of the three codon positions. Therefore, we investigated the robustness of this code regarding the cost of amino acid replacements resulting from substitutions in these positions separately and the sum of these costs. We applied a modified evolutionary algorithm and included four models of the genetic code assuming various restrictions on its structure. The SGC was compared both with the codes that minimize the objective function and those that maximize it. This approach allowed us to place the SGC in the global space of possible codes, which is a more appropriate and unbiased comparison than that with randomly generated codes because they are characterized by relatively uniform amino acid assignments to codons. The SGC appeared to be well optimized at the global scale, but its individual positions were not fully optimized because there were codes that were optimized for only one codon position and simultaneously outperformed the SGC at the other positions. We also found that different code structures may lead to the same optimality and that random codes can show a tendency to minimize costs under some of the genetic code models. Our results suggest that the optimality of SGC could be a by-product of other processes.
许多生物系统通常从适应某些条件或要求的角度进行研究。标准遗传密码(SGC)就是这样一个系统,它通常可以将突变或翻译错误导致的氨基酸替换成本最小化。然而,对于导致这种特征进化的因素,尚未达成完全共识。其中一个假设表明,代码最优性被直接选择为一种优势,以保留有关编码蛋白的信息。在研究 SGC 时,应该考虑到一个重要特征,即三个密码子位置的不同作用。因此,我们研究了这个代码在这些位置的替换导致的氨基酸替换成本以及这些成本之和方面的稳健性。我们应用了一种改进的进化算法,并包括了四个遗传密码模型,假设对其结构有各种限制。将 SGC 与最小化目标函数的代码和最大化目标函数的代码进行了比较。这种方法使我们能够将 SGC 置于可能的代码全局空间中,与随机生成的代码进行比较更加合适和公正,因为它们的特征是相对均匀的将氨基酸分配给密码子。在全局范围内,SGC 似乎得到了很好的优化,但它的个别位置并没有完全优化,因为有些代码只对一个密码子位置进行了优化,同时在其他位置上表现优于 SGC。我们还发现,不同的代码结构可能导致相同的最优性,并且在某些遗传密码模型下,随机代码可能表现出降低成本的趋势。我们的结果表明,SGC 的最优性可能是其他过程的副产品。