Varghese Julian, Fujarski Michael, Hegselmann Stefan, Neuhaus Philipp, Dugas Martin
Institute of Medical Informatics, University of Münster,
Faculty of Mathematics and Computer Sciences, University of Münster.
Clin Epidemiol. 2018 Aug 10;10:961-970. doi: 10.2147/CLEP.S170075. eCollection 2018.
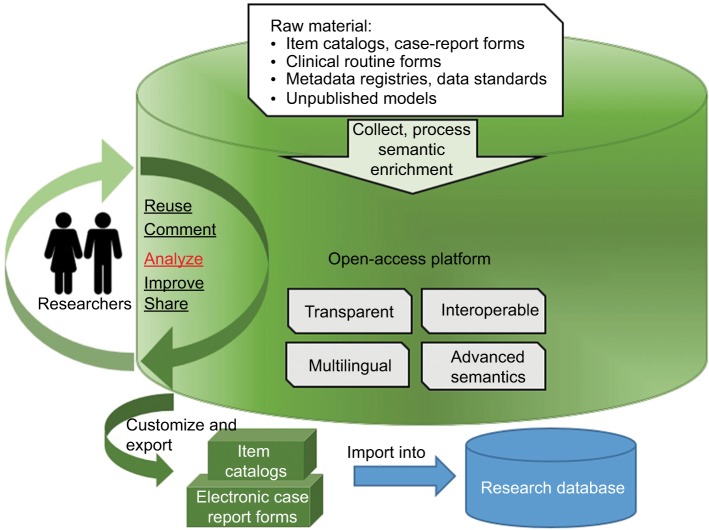
Best-practice data models harmonize semantics and data structure of medical variables in clinical or epidemiological studies. While there exist several published data sets, it remains challenging to find and reuse published eligibility criteria or other data items that match specific needs of a newly planned study or registry. A novel Internet-based method for rapid comparison of published data models was implemented to enable reuse, customization, and harmonization of item catalogs for the early planning and development phase of research databases.
Based on prior work, a European information infrastructure with a large collection of medical data models was established. A newly developed analysis module called CDEGenerator provides systematic comparison of selected data models and user-tailored creation of minimum data sets or harmonized item catalogs. Usability was assessed by eight external medical documentation experts in a workshop by the umbrella organization for networked medical research in Germany with the System Usability Scale.
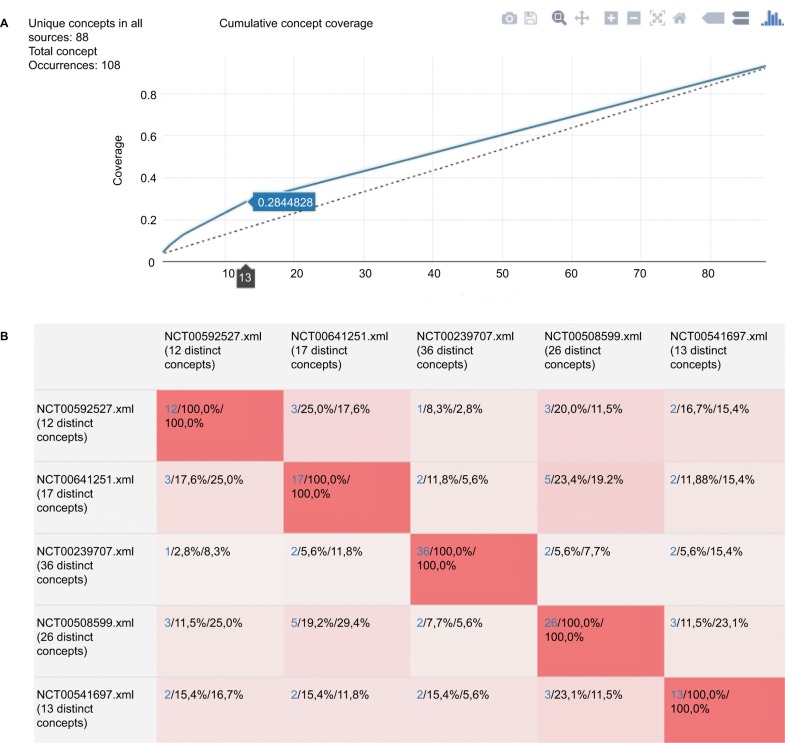
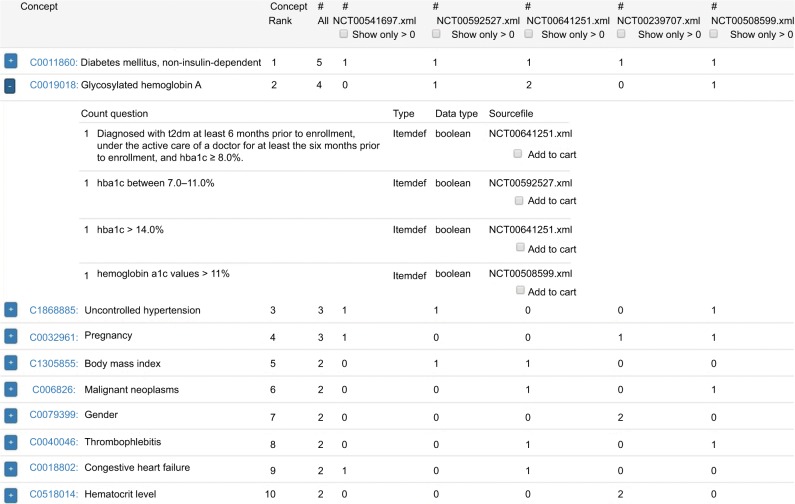
The analysis and item-tailoring module provides multilingual comparisons of semantically complex eligibility criteria of clinical trials. The System Usability Scale yielded "good usability" (mean 75.0, range 65.0-92.5). User-tailored models can be exported to several data formats, such as XLS, REDCap or Operational Data Model by the Clinical Data Interchange Standards Consortium, which is supported by the US Food and Drug Administration and European Medicines Agency for metadata exchange of clinical studies.
The online tool provides user-friendly methods to reuse, compare, and thus learn from data items of standardized or published models to design a blueprint for a harmonized research database.
最佳实践数据模型可协调临床或流行病学研究中医学变量的语义和数据结构。虽然已有多个已发表的数据集,但要找到并重用与新规划研究或登记处的特定需求相匹配的已发表入选标准或其他数据项仍具有挑战性。实施了一种基于互联网的新颖方法,用于快速比较已发表的数据模型,以便在研究数据库的早期规划和开发阶段实现项目目录的重用、定制和协调。
基于先前的工作,建立了一个拥有大量医学数据模型的欧洲信息基础设施。一个名为CDEGenerator的新开发分析模块可对选定的数据模型进行系统比较,并根据用户需求创建最小数据集或协调的项目目录。德国网络医学研究伞式组织在一次研讨会上,由八位外部医学文档专家使用系统可用性量表对其可用性进行了评估。
该分析和项目定制模块可对临床试验语义复杂的入选标准进行多语言比较。系统可用性量表得出“良好可用性”(平均75.0,范围65.0 - 92.5)。用户定制的模型可以导出为多种数据格式,如XLS、REDCap或临床数据交换标准协会的操作数据模型,美国食品药品监督管理局和欧洲药品管理局支持该协会进行临床研究的元数据交换。
该在线工具提供了用户友好的方法,可重用、比较并借鉴标准化或已发表模型的数据项,从而为协调的研究数据库设计蓝图。