The Francis Crick Institute, Molecular Biology of Metabolism laboratory, London, UK; Department of Biochemistry and Cambridge Systems Biology Centre, University of Cambridge, Cambridge, UK; Department of Biology and Biological Engineering, Chalmers University of Technology, Gothenburg, Sweden; Science for Life Laboratory, KTH - Royal Institute of Technology, Stockholm, Sweden.
Department of Biochemistry and Cambridge Systems Biology Centre, University of Cambridge, Cambridge, UK; Biognosys AG, Schlieren, Switzerland.
Cell Syst. 2018 Sep 26;7(3):269-283.e6. doi: 10.1016/j.cels.2018.08.001. Epub 2018 Sep 5.
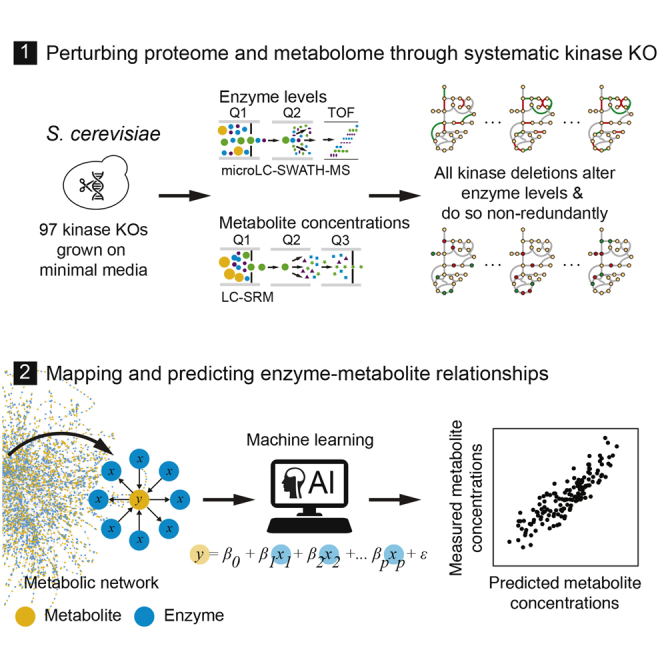
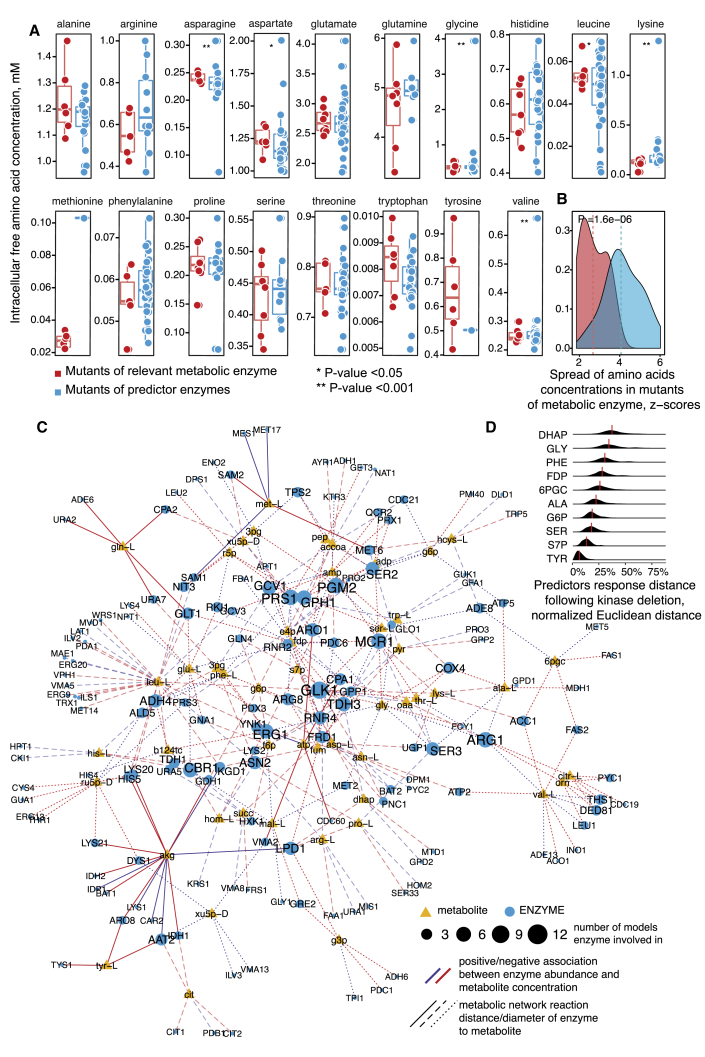
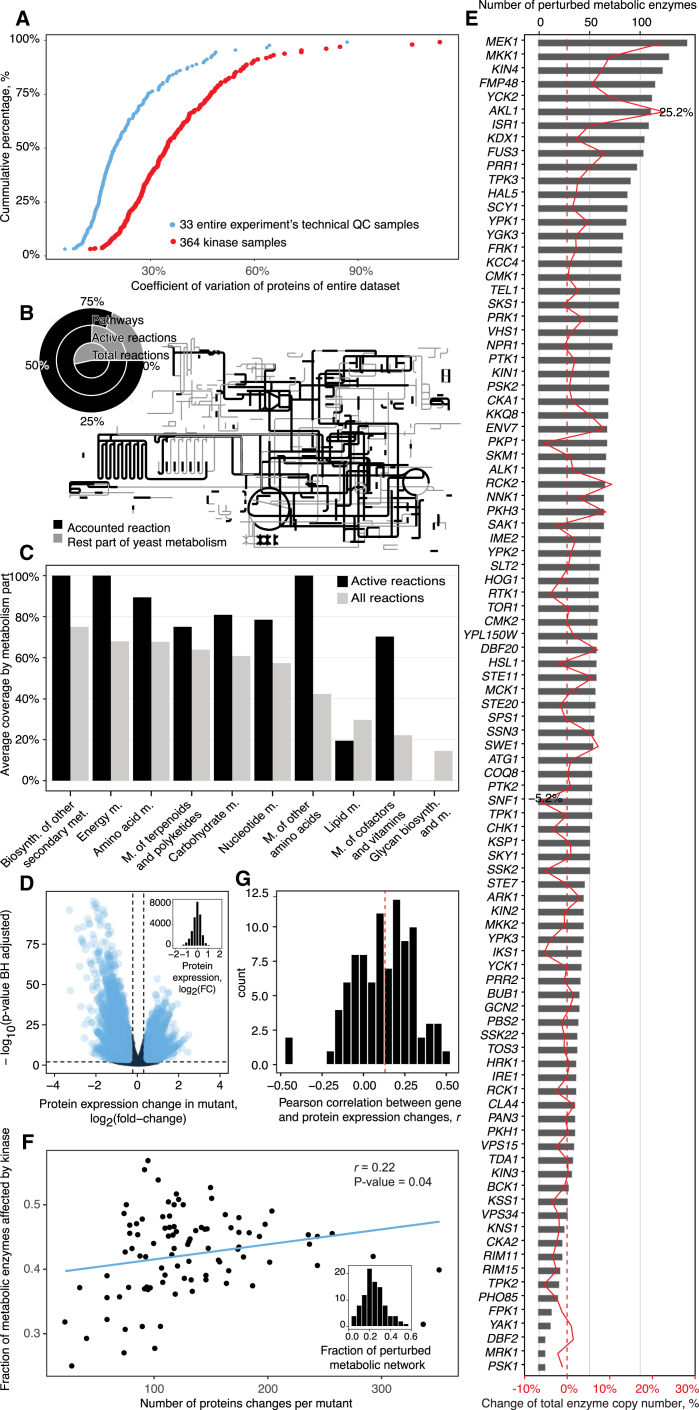
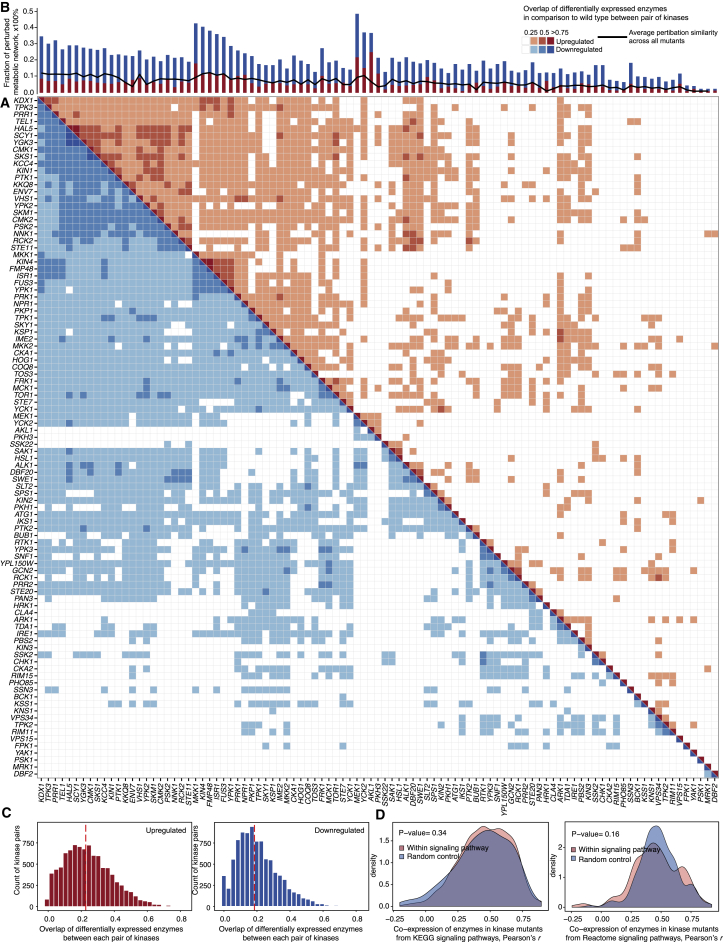
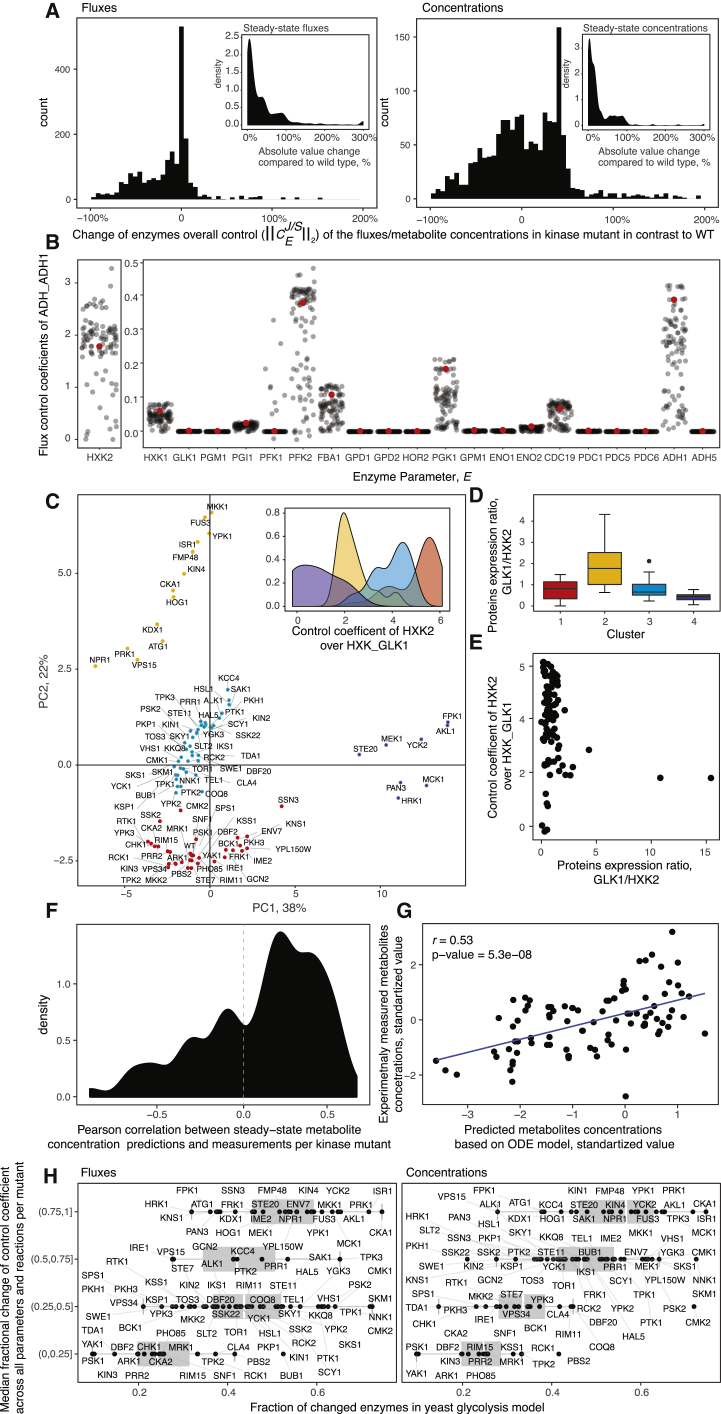
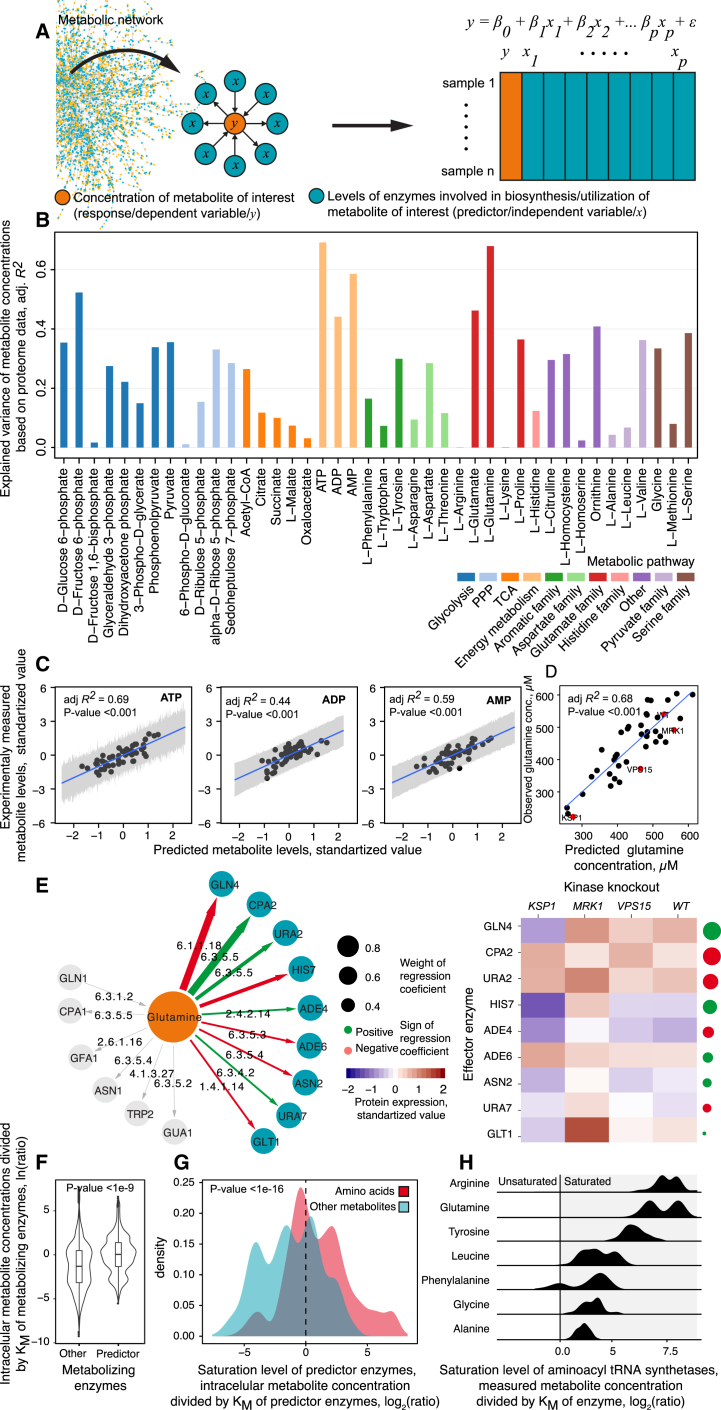
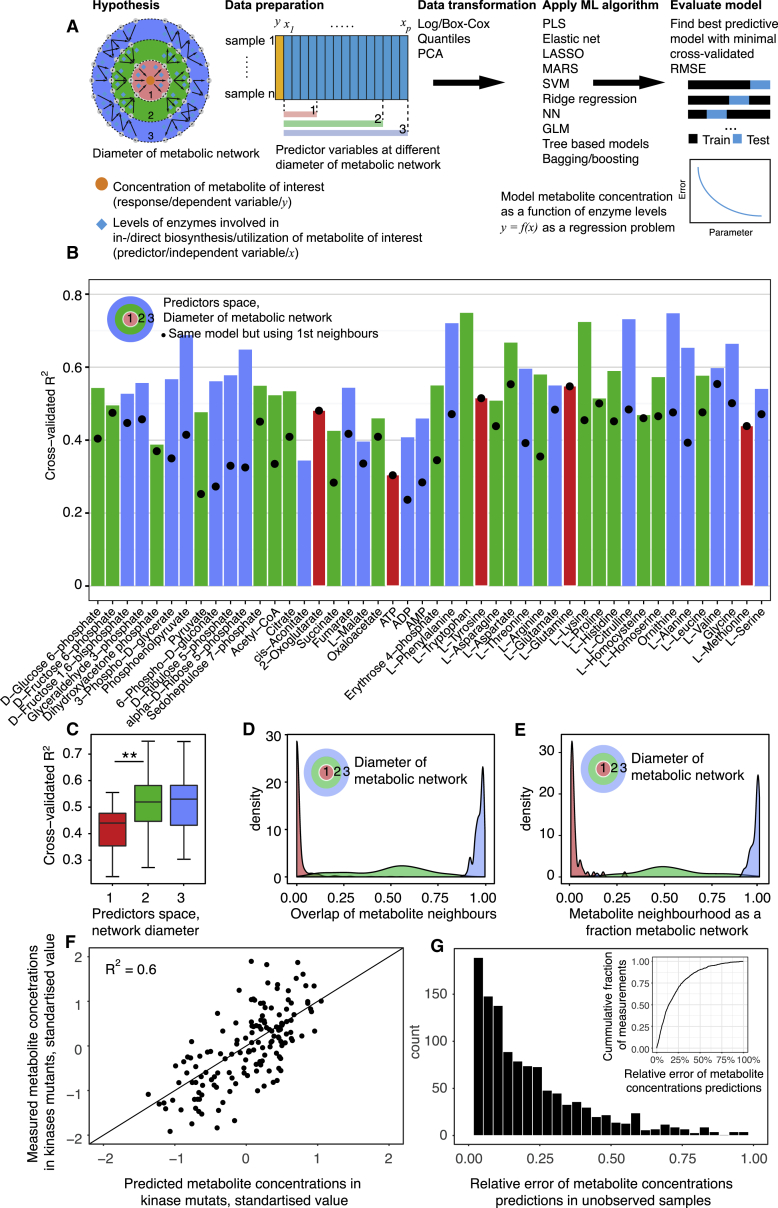
A challenge in solving the genotype-to-phenotype relationship is to predict a cell's metabolome, believed to correlate poorly with gene expression. Using comparative quantitative proteomics, we found that differential protein expression in 97 Saccharomyces cerevisiae kinase deletion strains is non-redundant and dominated by abundance changes in metabolic enzymes. Associating differential enzyme expression landscapes to corresponding metabolomes using network models provided reasoning for poor proteome-metabolome correlations; differential protein expression redistributes flux control between many enzymes acting in concert, a mechanism not captured by one-to-one correlation statistics. Mapping these regulatory patterns using machine learning enabled the prediction of metabolite concentrations, as well as identification of candidate genes important for the regulation of metabolism. Overall, our study reveals that a large part of metabolism regulation is explained through coordinated enzyme expression changes. Our quantitative data indicate that this mechanism explains more than half of metabolism regulation and underlies the interdependency between enzyme levels and metabolism, which renders the metabolome a predictable phenotype.
解决基因型到表型关系的一个挑战是预测细胞的代谢组,人们认为代谢组与基因表达相关性较差。通过比较定量蛋白质组学,我们发现 97 株酿酒酵母激酶缺失菌株中差异蛋白表达是非冗余的,主要是代谢酶的丰度变化。使用网络模型将差异酶表达图谱与相应的代谢组学关联,为较差的蛋白质组-代谢组相关性提供了依据;差异蛋白表达在协同作用的许多酶之间重新分配通量控制,这种机制无法通过一对一相关统计来捕捉。使用机器学习对这些调控模式进行映射,可以预测代谢物浓度,并确定对代谢调控重要的候选基因。总的来说,我们的研究表明,大部分代谢调控是通过协调的酶表达变化来解释的。我们的定量数据表明,这种机制解释了超过一半的代谢调控,并且是酶水平和代谢之间相互依赖的基础,这使得代谢组成为一个可预测的表型。