Department of Computation Science and Artificial Intelligence, University of the Basque Country UPV/EHU, Donostia, Spain.
Department of Genetics, Microbiology and Statistics, University of Barcelona, Barcelona, Spain.
BMC Bioinformatics. 2018 Sep 10;19(1):317. doi: 10.1186/s12859-018-2318-8.
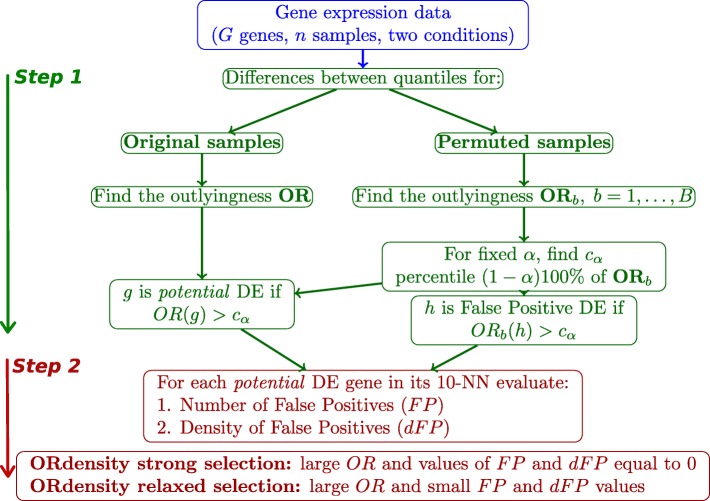
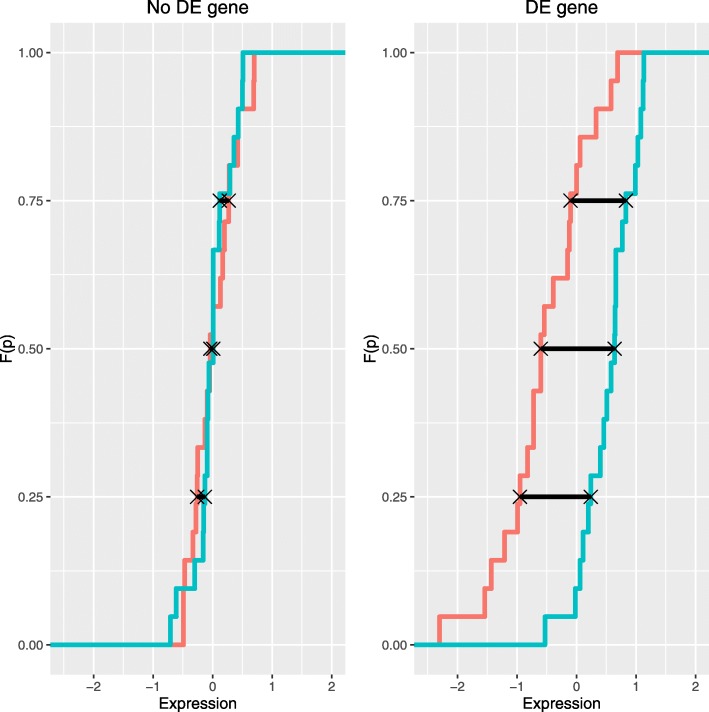
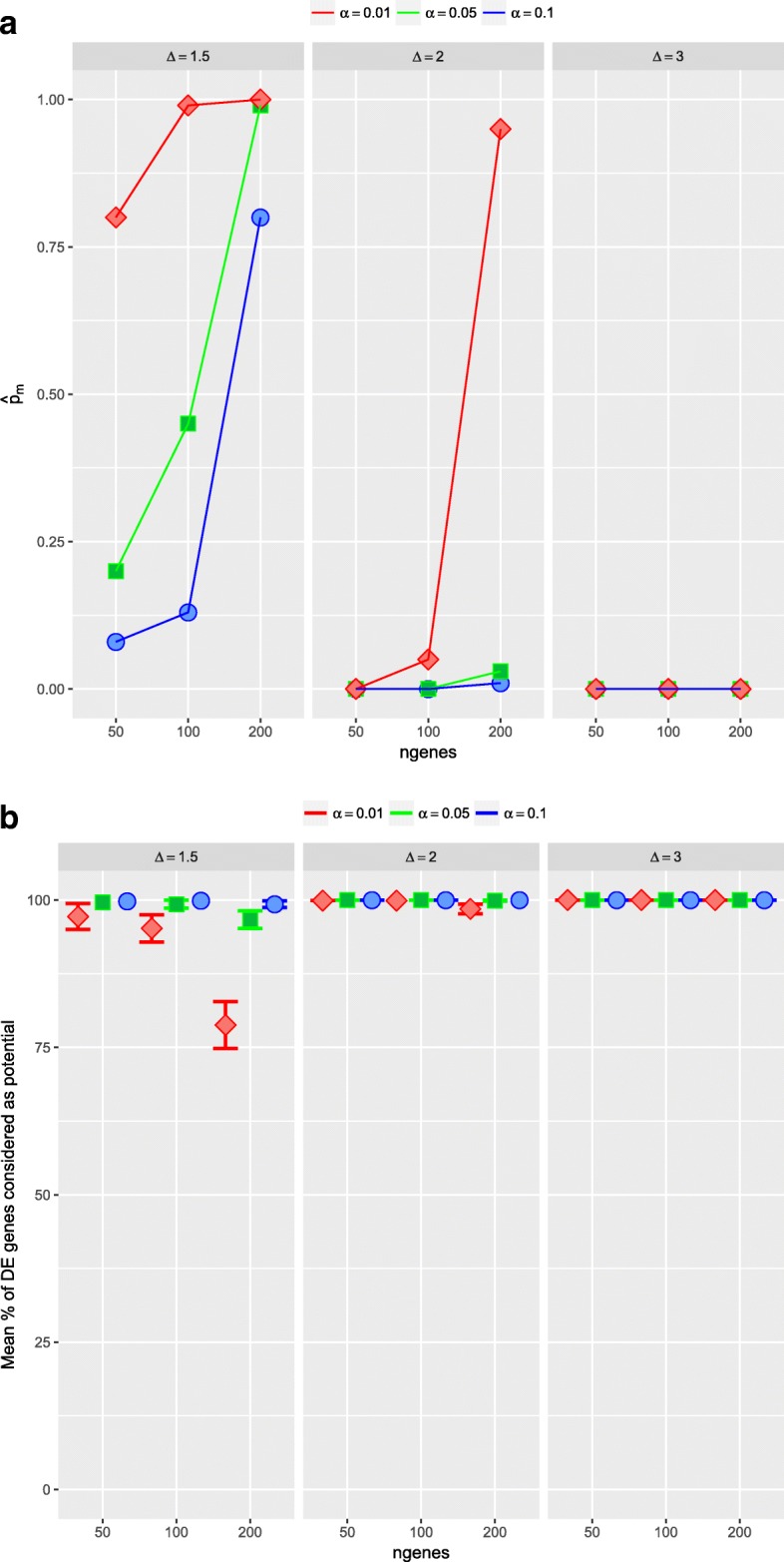
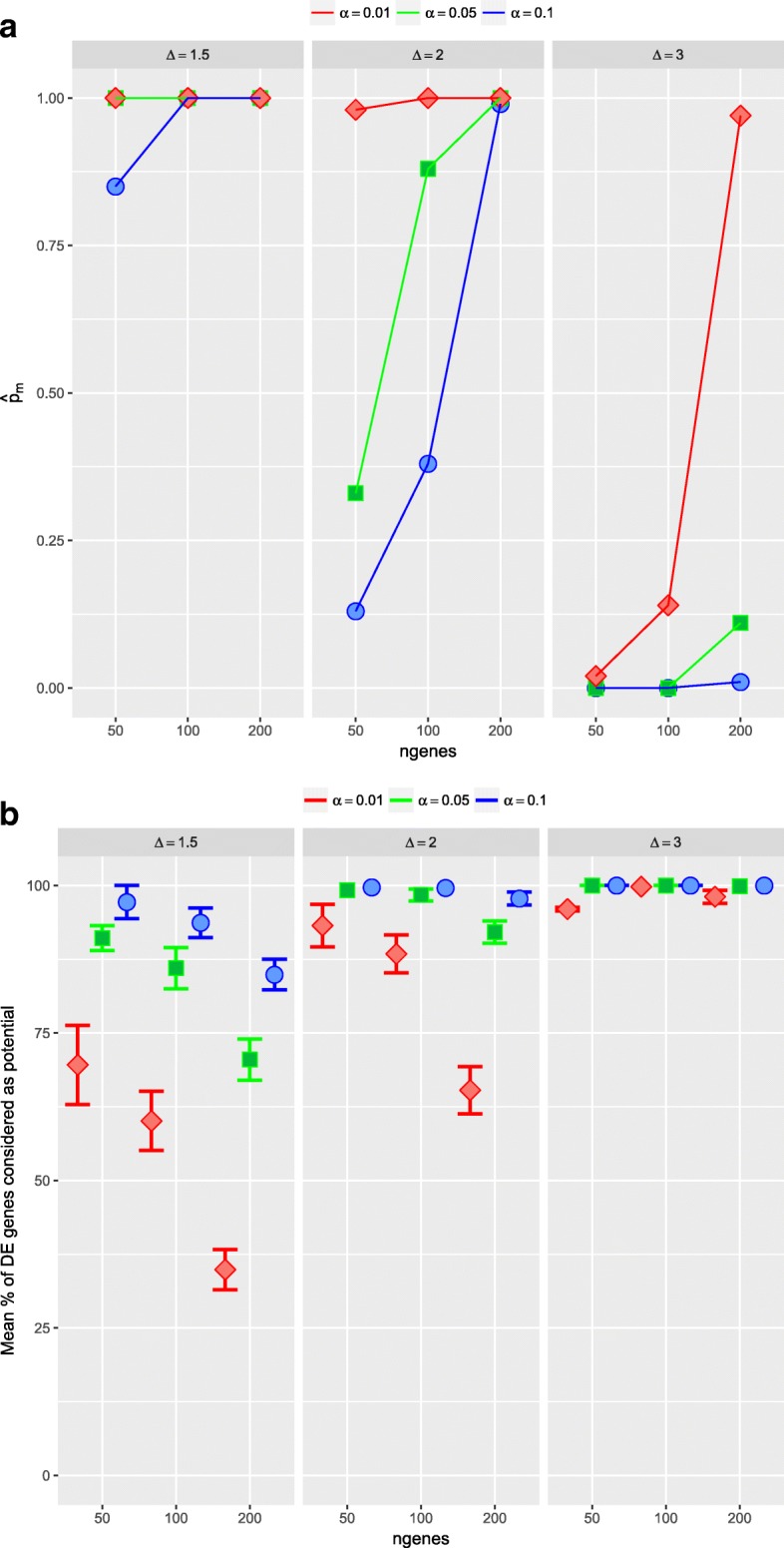
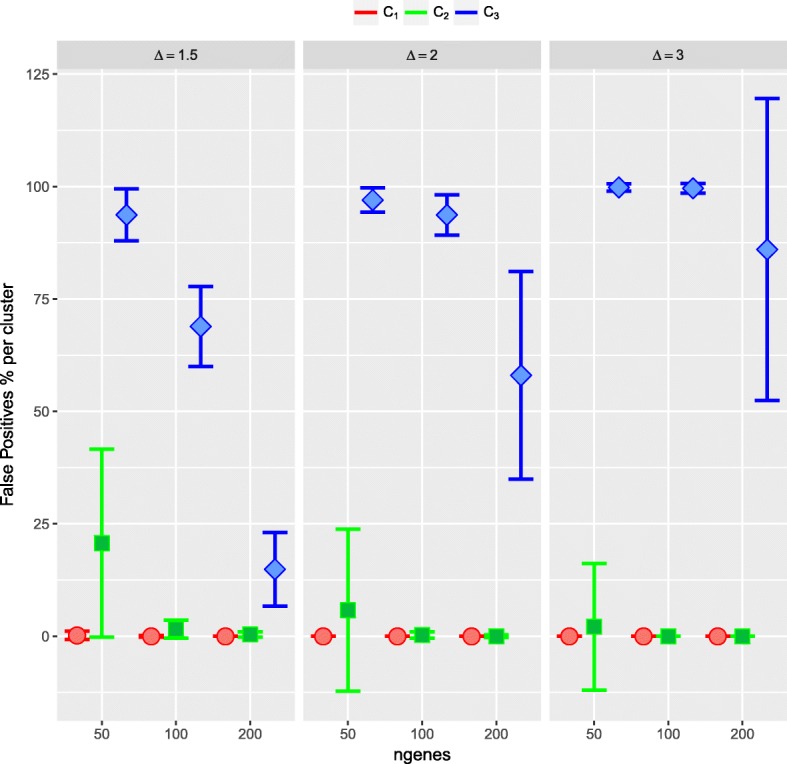
An important issue in microarray data is to select, from thousands of genes, a small number of informative differentially expressed (DE) genes which may be key elements for a disease. If each gene is analyzed individually, there is a big number of hypotheses to test and a multiple comparison correction method must be used. Consequently, the resulting cut-off value may be too small. Moreover, an important issue is the selection's replicability of the DE genes. We present a new method, called ORdensity, to obtain a reproducible selection of DE genes. It takes into account the relation between all genes and it is not a gene-by-gene approach, unlike the usually applied techniques to DE gene selection.
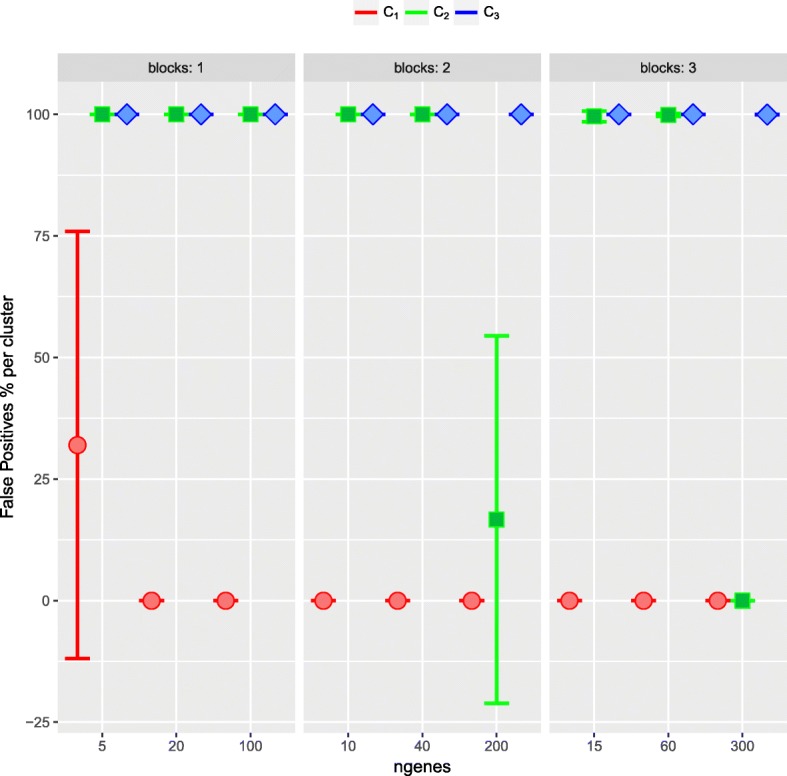
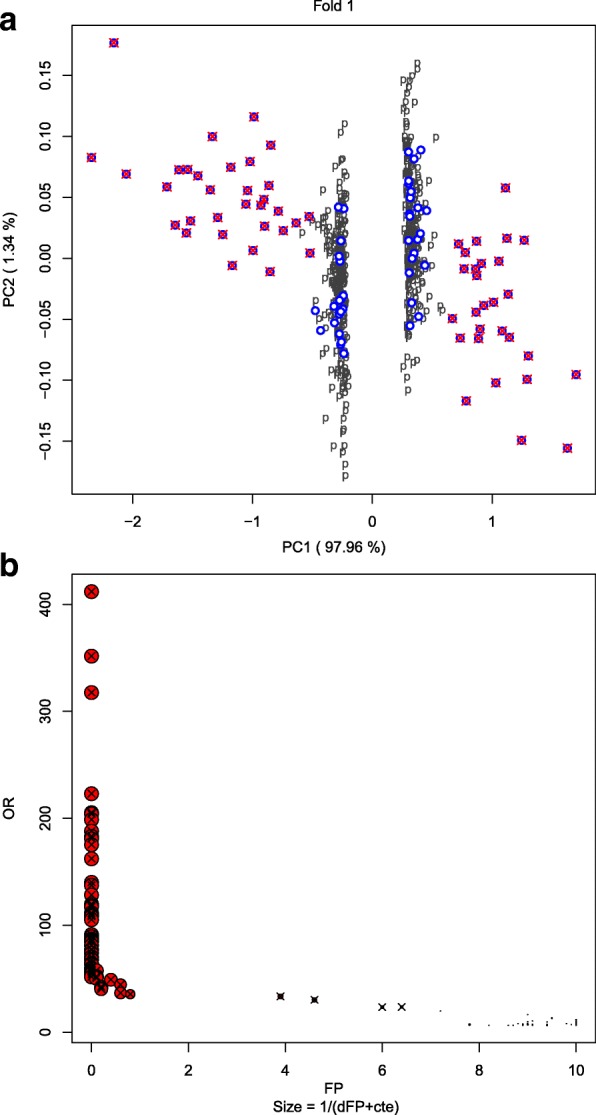
The proposed method returns three measures, related to the concepts of outlier and density of false positives in a neighbourhood, which allow us to identify the DE genes with high classification accuracy. To assess the performance of ORdensity, we used simulated microarray data and four real microarray cancer data sets. The results indicated that the method correctly detects the DE genes; it is competitive with other well accepted methods; the list of DE genes that it obtains is useful for the correct classification or diagnosis of new future samples and, in general, it is more stable than other procedures.
ORdensity is a new method for identifying DE genes that avoids some of the shortcomings of the individual gene identification and it is stable when the original sample is changed by subsamples.
在微阵列数据中,一个重要的问题是从数千个基因中选择少数有信息的差异表达(DE)基因,这些基因可能是疾病的关键因素。如果逐个分析每个基因,那么需要测试的假设数量非常多,必须使用多重比较校正方法。因此,得出的截止值可能太小。此外,一个重要的问题是 DE 基因选择的可重复性。我们提出了一种新的方法,称为 ORdensity,以获得可重复的 DE 基因选择。它考虑了所有基因之间的关系,而不是像通常应用于 DE 基因选择的技术那样逐个基因进行分析。
所提出的方法返回三个度量值,与邻域中伪阳性的异常值和密度的概念有关,这些度量值可用于识别具有高分类准确性的 DE 基因。为了评估 ORdensity 的性能,我们使用了模拟微阵列数据和四个真实的微阵列癌症数据集。结果表明,该方法可以正确检测 DE 基因;它与其他公认的方法具有竞争力;它获得的 DE 基因列表对于新未来样本的正确分类或诊断非常有用,并且通常比其他程序更稳定。
ORdensity 是一种识别 DE 基因的新方法,它避免了个别基因识别的一些缺点,并且在原始样本通过子样本发生变化时也很稳定。