Ameur Adam, Che Huiwen, Martin Marcel, Bunikis Ignas, Dahlberg Johan, Höijer Ida, Häggqvist Susana, Vezzi Francesco, Nordlund Jessica, Olason Pall, Feuk Lars, Gyllensten Ulf
Science for Life Laboratory, Department of Immunology, Genetics and Pathology, Uppsala University, 752 36 Uppsala, Sweden.
Science for Life Laboratory, Department of Biochemistry and Biophysics (DBB), Stockholm University, 114 19 Stockholm, Sweden.
Genes (Basel). 2018 Oct 9;9(10):486. doi: 10.3390/genes9100486.
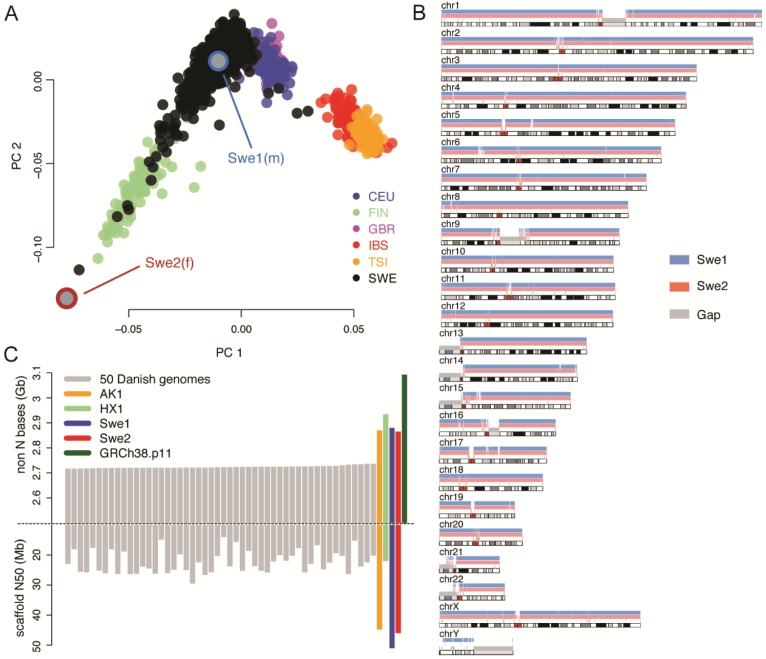
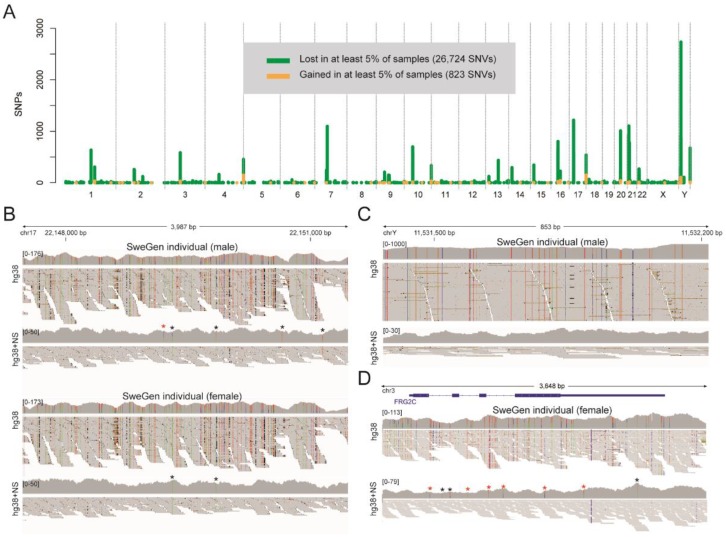
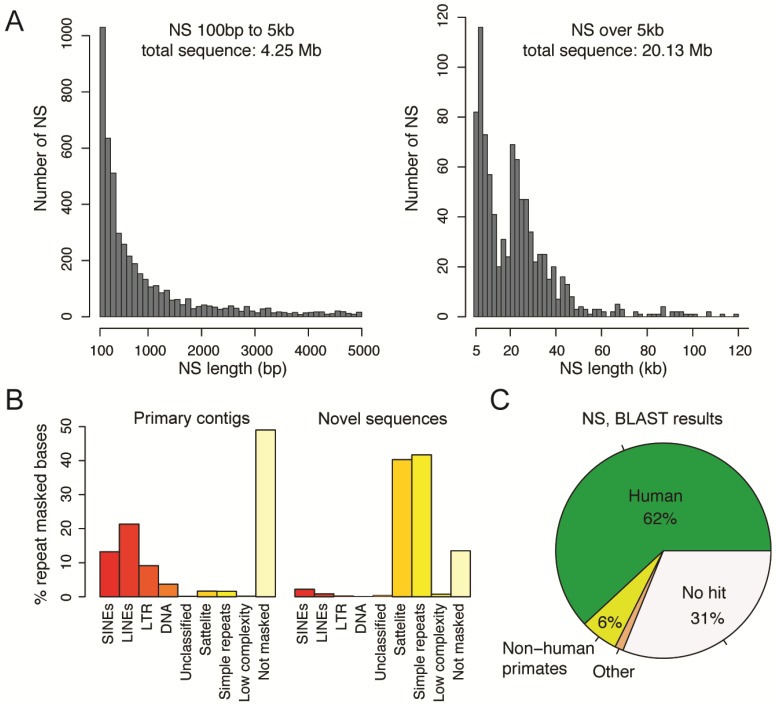
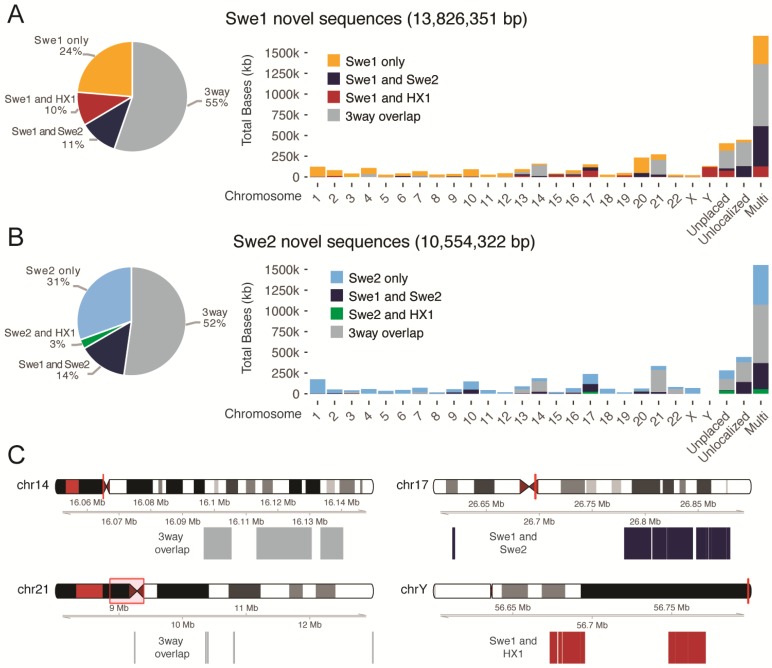
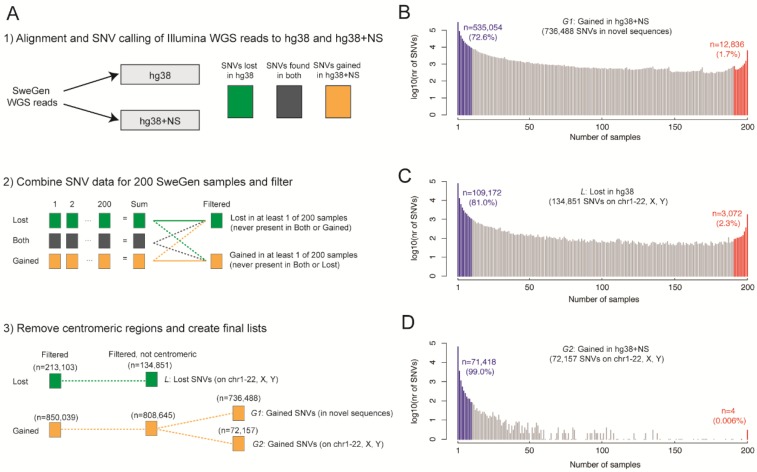
The current human reference sequence (GRCh38) is a foundation for large-scale sequencing projects. However, recent studies have suggested that GRCh38 may be incomplete and give a suboptimal representation of specific population groups. Here, we performed a de novo assembly of two Swedish genomes that revealed over 10 Mb of sequences absent from the human GRCh38 reference in each individual. Around 6 Mb of these novel sequences (NS) are shared with a Chinese personal genome. The NS are highly repetitive, have an elevated GC-content, and are primarily located in centromeric or telomeric regions. Up to 1 Mb of NS can be assigned to chromosome Y, and large segments are also missing from GRCh38 at chromosomes 14, 17, and 21. Inclusion of NS into the GRCh38 reference radically improves the alignment and variant calling from short-read whole-genome sequencing data at several genomic loci. A re-analysis of a Swedish population-scale sequencing project yields > 75,000 putative novel single nucleotide variants (SNVs) and removes > 10,000 false positive SNV calls per individual, some of which are located in protein coding regions. Our results highlight that the GRCh38 reference is not yet complete and demonstrate that personal genome assemblies from local populations can improve the analysis of short-read whole-genome sequencing data.
当前的人类参考序列(GRCh38)是大规模测序项目的基础。然而,最近的研究表明,GRCh38可能不完整,无法很好地代表特定人群。在此,我们对两个瑞典基因组进行了从头组装,结果显示每个个体中都有超过10 Mb的序列在人类GRCh38参考序列中缺失。这些新序列(NS)中约6 Mb与一个中国个人基因组共有。NS具有高度重复性,GC含量升高,主要位于着丝粒或端粒区域。多达1 Mb的NS可定位到Y染色体,14号、17号和21号染色体上的GRCh38也缺失大片段。将NS纳入GRCh38参考序列可从根本上改善几个基因组位点短读长全基因组测序数据的比对和变异检测。对一个瑞典人群规模测序项目的重新分析产生了超过75,000个推定的新型单核苷酸变异(SNV),并消除了每个个体中超过10,000个假阳性SNV,其中一些位于蛋白质编码区域。我们的结果突出表明GRCh38参考序列尚未完整,并证明来自当地人群的个人基因组组装可以改善短读长全基因组测序数据的分析。