Pi Lira, Halabi Susan
Department of Biostatistics and Bioinformatics, Duke University Medical Center, Durham, NC 27710.
Diagn Progn Res. 2018;2. doi: 10.1186/s41512-018-0043-4. Epub 2018 Sep 26.
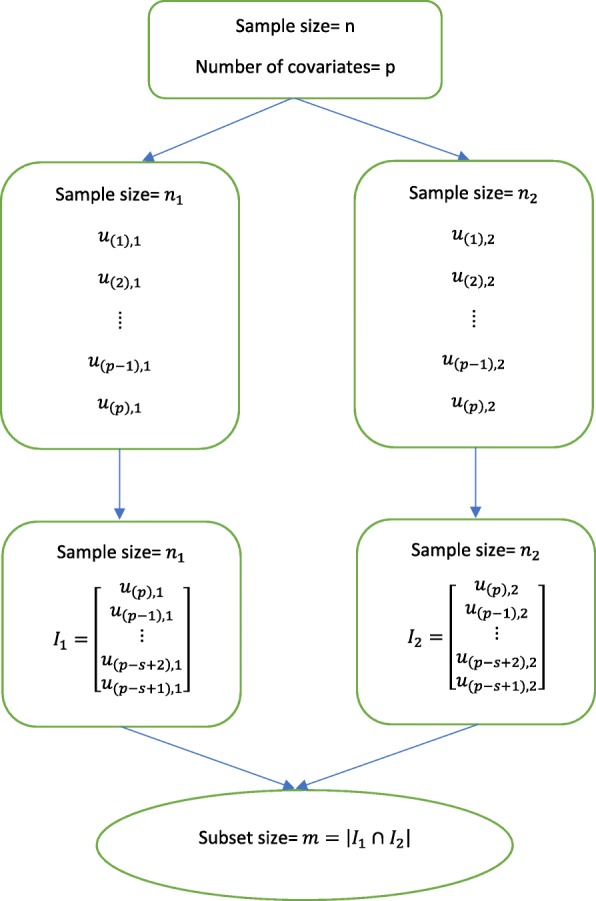
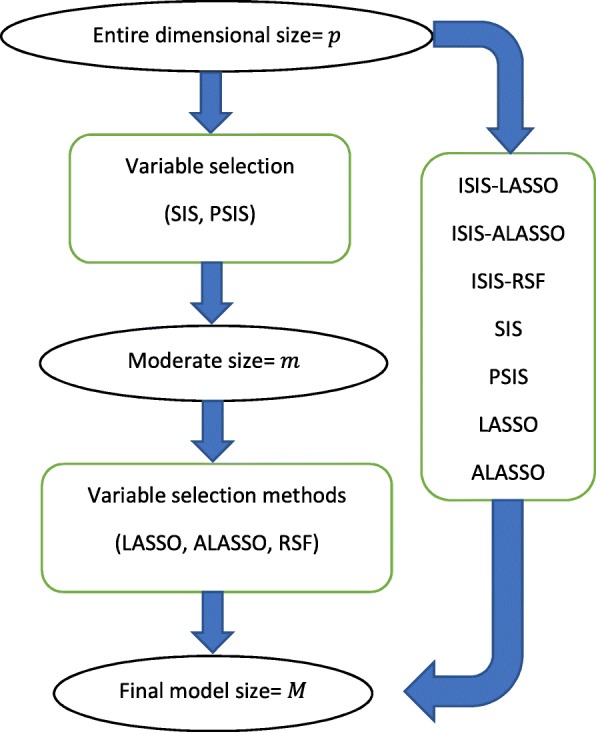
Building prognostic models of clinical outcomes is an increasingly important research task and will remain a vital area in genomic medicine. Prognostic models of clinical outcomes are usually built and validated utilizing variable selection methods and machine learning tools. The challenges, however, in ultra-high dimensional space are not only to reduce the dimensionality of the data, but also to retain the important variables which predict the outcome. Screening approaches, such as the sure independence screening (SIS), iterative SIS (ISIS) and principled SIS (PSIS) have been developed to overcome the challenge of high dimensionality. We are interested in identifying important single-nucleotide polymorphisms (SNPs) and integrating them into a validated prognostic model of overall survival in patients with metastatic prostate cancer. While the abovementioned variable selection approaches have theoretical justification in selecting SNPs, the comparison and the performance of these combined methods in predicting time-to-event outcomes have not been previously studied in ultra-high dimensional space with hundreds of thousands of variables.
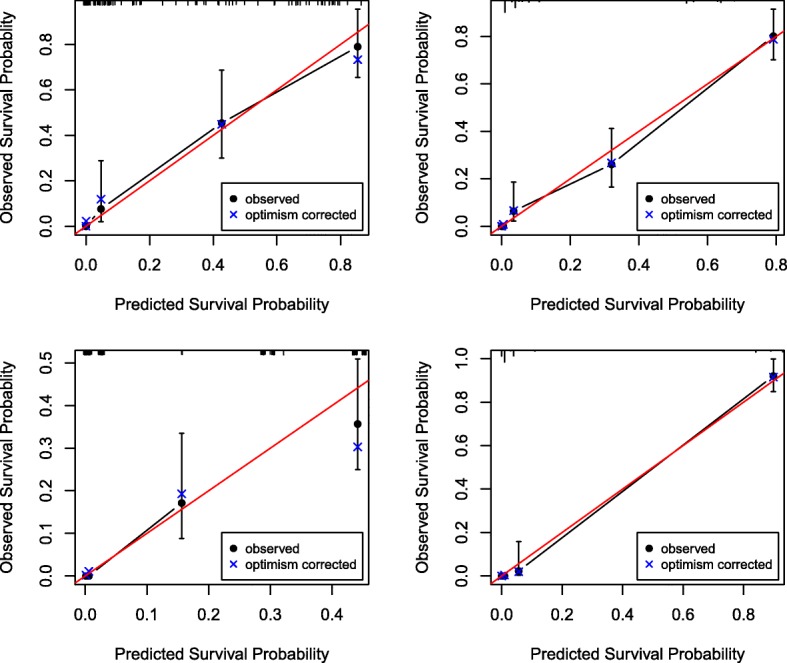
We conducted a series of simulations to compare the performance of different combinations of variable selection approaches and classification trees, such as the least absolute shrinkage and selection operator (LASSO), adaptive least absolute shrinkage and selection operator (ALASSO) and random survival forest (RSF), in ultra-high dimensional setting data for the purpose of developing prognostic models for a time-to-event outcome that is subject to censoring. The variable selection methods were evaluated for discrimination (Harrell's concordance statistic), calibration and overall performance. In addition, we applied these approaches to 498,081 SNPs from 623 Caucasian patients with prostate cancer.
When n=300, ISIS-LASSO and ISIS-ALASSO chose all the informative variables which resulted in the highest Harrell's c-index (>0.80). On the other hand, with a small sample size (n=150), ALASSO performed better than any other combinations as demonstrated by the highest c-index and/or overall performance, although there was evidence of overfitting. In analyzing the prostate cancer data, ISIS-ALASSO, SIS-LASSO, and SIS-ALASSO combinations achieved the highest discrimination with c-index of 0.67.
Choosing the appropriate variable selection method for training a model is a critical step in developing a robust prognostic model. Based on the simulation studies, the effective use of ALASSO or a combination of methods, such as ISIS-LASSO and ISIS-ALASSO, allows both for the development of prognostic models with high predictive accuracy and a low risk of overfitting assuming moderate sample sizes.
构建临床结局的预后模型是一项日益重要的研究任务,并且仍将是基因组医学中的一个关键领域。临床结局的预后模型通常利用变量选择方法和机器学习工具来构建和验证。然而,在超高维空间中的挑战不仅在于降低数据的维度,还在于保留预测结局的重要变量。已经开发了筛选方法,如确定性独立筛选(SIS)、迭代SIS(ISIS)和原则性SIS(PSIS)来克服高维性的挑战。我们有兴趣识别重要的单核苷酸多态性(SNP),并将它们整合到转移性前列腺癌患者总生存的经过验证的预后模型中。虽然上述变量选择方法在选择SNP方面有理论依据,但这些组合方法在预测事件发生时间结局方面的比较和性能此前尚未在具有数十万变量的超高维空间中进行研究。
我们进行了一系列模拟,以比较变量选择方法和分类树的不同组合,如最小绝对收缩和选择算子(LASSO)、自适应最小绝对收缩和选择算子(ALASSO)以及随机生存森林(RSF)在超高维设置数据中的性能,目的是为受删失影响的事件发生时间结局开发预后模型。对变量选择方法进行了区分度(Harrell一致性统计量)、校准和整体性能的评估。此外,我们将这些方法应用于来自623名白种人前列腺癌患者的498,081个SNP。
当n = 300时,ISIS - LASSO和ISIS - ALASSO选择了所有信息变量,从而获得了最高的Harrell c指数(> 0.80)。另一方面,在小样本量(n = 150)时,尽管有过拟合的证据,但ALASSO的表现优于任何其他组合,这体现在最高的c指数和/或整体性能上。在分析前列腺癌数据时,ISIS - ALASSO、SIS - LASSO和SIS - ALASSO组合实现了最高的区分度,c指数为0.67。
选择合适的变量选择方法来训练模型是开发稳健预后模型的关键步骤。基于模拟研究,有效使用ALASSO或方法组合,如ISIS - LASSO和ISIS - ALASSO,在中等样本量的情况下,既能开发出具有高预测准确性且过拟合风险低的预后模型。