Department of Biological Sciences, Vanderbilt University, Nashville, TN, USA.
Department of Biochemistry, Purdue University, West Lafayette, IN, USA.
BMC Med Genomics. 2018 Nov 19;11(1):107. doi: 10.1186/s12920-018-0426-y.
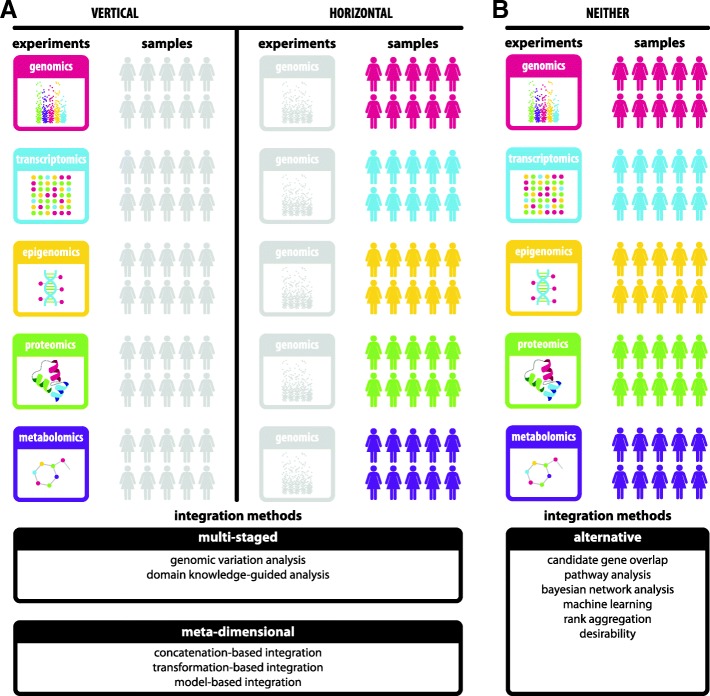
The integration of high-quality, genome-wide analyses offers a robust approach to elucidating genetic factors involved in complex human diseases. Even though several methods exist to integrate heterogeneous omics data, most biologists still manually select candidate genes by examining the intersection of lists of candidates stemming from analyses of different types of omics data that have been generated by imposing hard (strict) thresholds on quantitative variables, such as P-values and fold changes, increasing the chance of missing potentially important candidates.
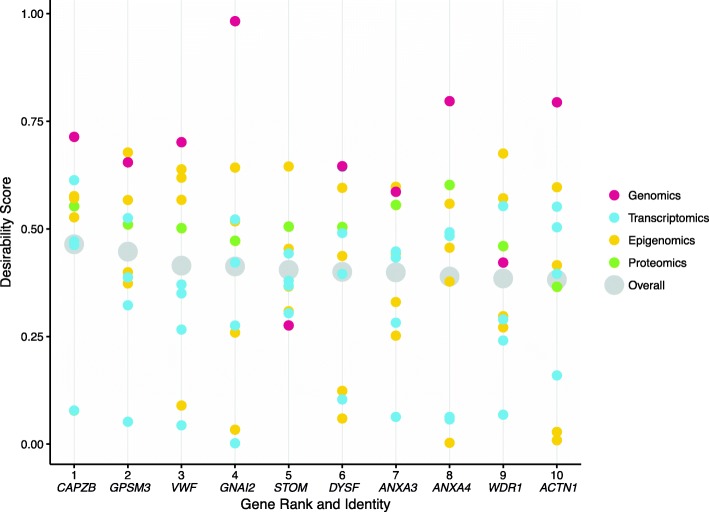
To better facilitate the unbiased integration of heterogeneous omics data collected from diverse platforms and samples, we propose a desirability function framework for identifying candidate genes with strong evidence across data types as targets for follow-up functional analysis. Our approach is targeted towards disease systems with sparse, heterogeneous omics data, so we tested it on one such pathology: spontaneous preterm birth (sPTB).
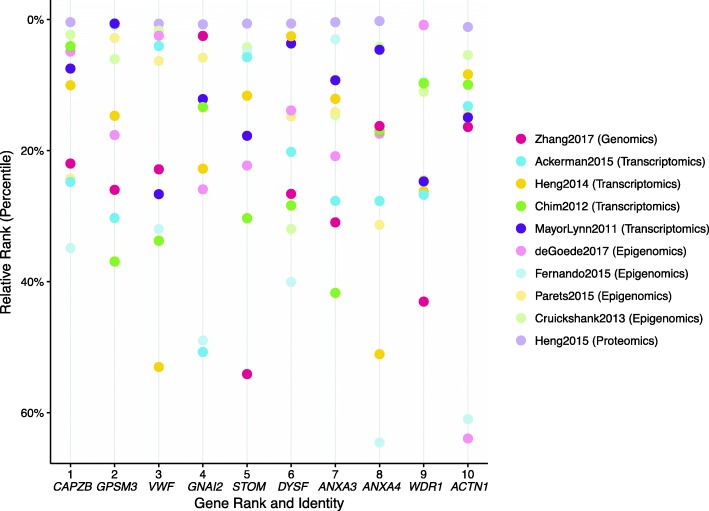
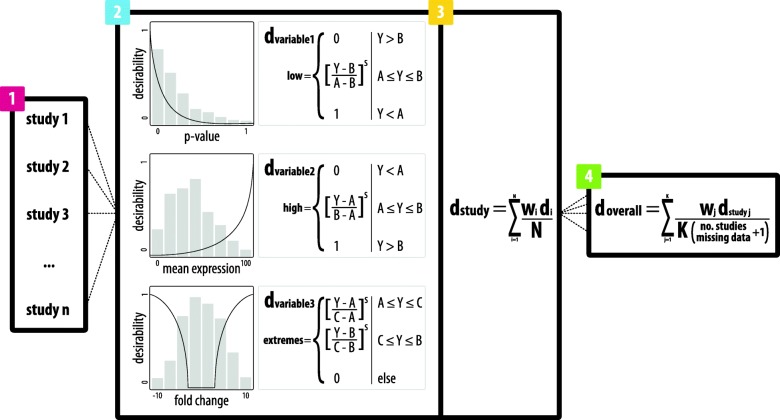
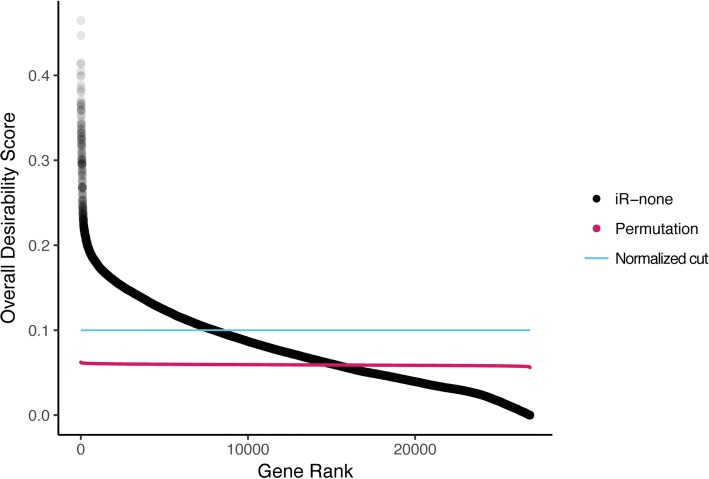
We developed the software integRATE, which uses desirability functions to rank genes both within and across studies, identifying well-supported candidate genes according to the cumulative weight of biological evidence rather than based on imposition of hard thresholds of key variables. Integrating 10 sPTB omics studies identified both genes in pathways previously suspected to be involved in sPTB as well as novel genes never before linked to this syndrome. integRATE is available as an R package on GitHub ( https://github.com/haleyeidem/integRATE ).
Desirability-based data integration is a solution most applicable in biological research areas where omics data is especially heterogeneous and sparse, allowing for the prioritization of candidate genes that can be used to inform more targeted downstream functional analyses.
整合高质量的全基因组分析为阐明复杂人类疾病相关的遗传因素提供了一种强有力的方法。尽管存在几种方法可以整合异构组学数据,但大多数生物学家仍然通过检查不同类型组学数据分析生成的候选列表的交集来手动选择候选基因,这些候选列表是通过对定量变量(如 P 值和倍数变化)施加硬性(严格)阈值来生成的,从而增加了错过潜在重要候选基因的机会。
为了更好地促进从不同平台和样本中收集的异构组学数据的无偏整合,我们提出了一种理想函数框架,用于识别具有跨数据类型强证据的候选基因作为后续功能分析的目标。我们的方法针对的是具有稀疏、异构组学数据的疾病系统,因此我们在一个这样的病理学中对其进行了测试:自发性早产(sPTB)。
我们开发了 integRATE 软件,该软件使用理想函数对研究内和研究间的基因进行排名,根据生物证据的累积权重而不是基于关键变量的硬性阈值来识别得到强有力支持的候选基因。整合 10 个 sPTB 组学研究,确定了先前怀疑与 sPTB 相关的途径中的基因以及从未与该综合征相关的新基因。integRATE 可在 GitHub 上作为 R 包获得(https://github.com/haleyeidem/integRATE)。
基于理想的数据分析整合是最适用于组学数据特别异构和稀疏的生物研究领域的解决方案,可优先考虑可用于告知更有针对性的下游功能分析的候选基因。