Roosa Kimberlyn, Chowell Gerardo
Department of Population Health Sciences, School of Public Health, Georgia State University, Atlanta, GA, USA.
Division of International Epidemiology and Population Studies, Fogarty International Center, National Institute of Health, Bethesda, MD, USA.
Theor Biol Med Model. 2019 Jan 14;16(1):1. doi: 10.1186/s12976-018-0097-6.
Mathematical modeling is now frequently used in outbreak investigations to understand underlying mechanisms of infectious disease dynamics, assess patterns in epidemiological data, and forecast the trajectory of epidemics. However, the successful application of mathematical models to guide public health interventions lies in the ability to reliably estimate model parameters and their corresponding uncertainty. Here, we present and illustrate a simple computational method for assessing parameter identifiability in compartmental epidemic models.
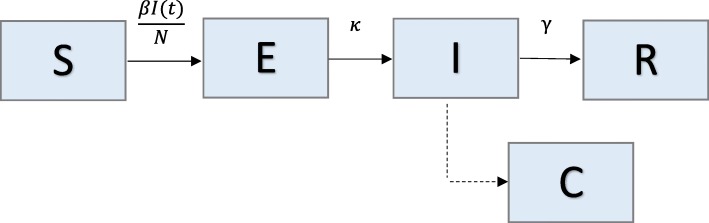
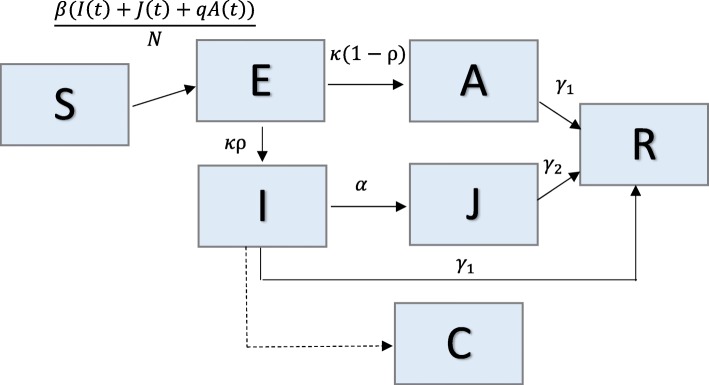
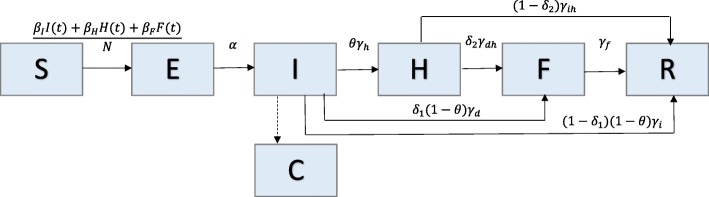
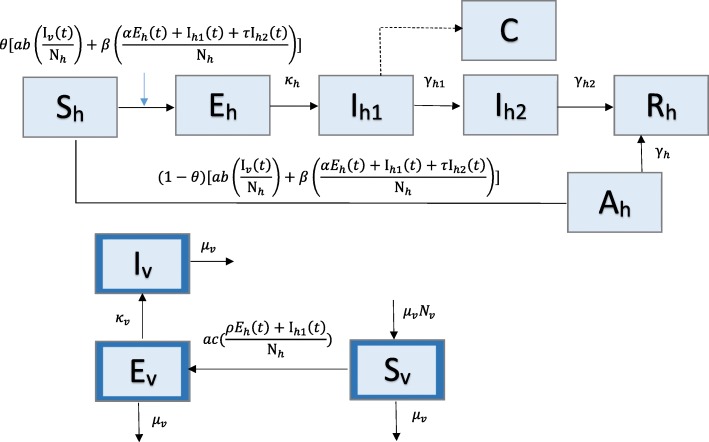
We describe a parametric bootstrap approach to generate simulated data from dynamical systems to quantify parameter uncertainty and identifiability. We calculate confidence intervals and mean squared error of estimated parameter distributions to assess parameter identifiability. To demonstrate this approach, we begin with a low-complexity SEIR model and work through examples of increasingly more complex compartmental models that correspond with applications to pandemic influenza, Ebola, and Zika.
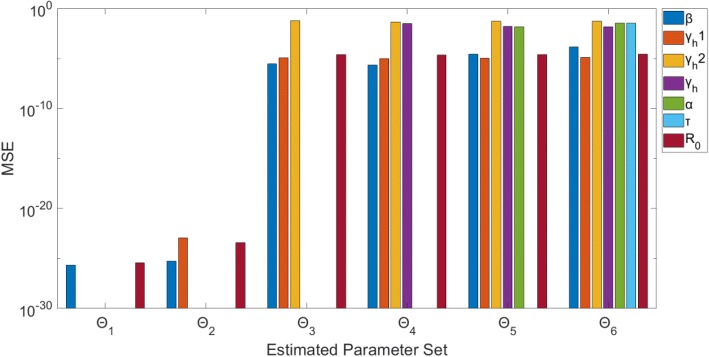
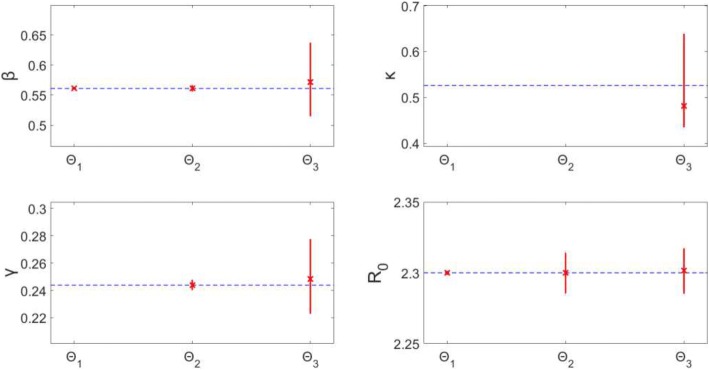
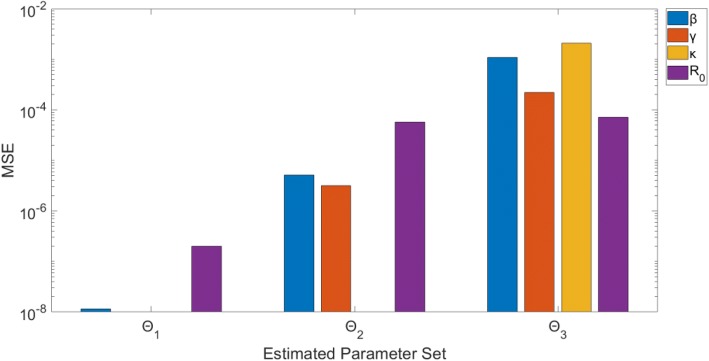
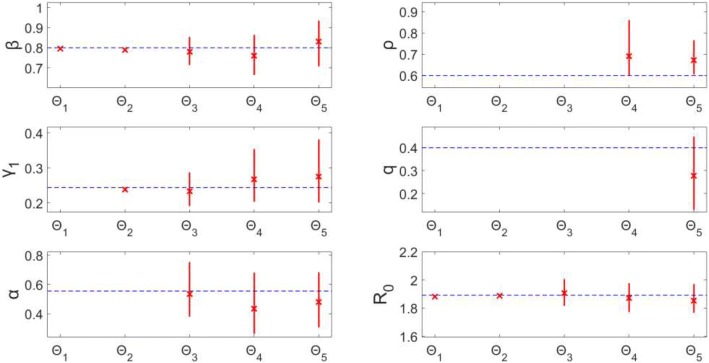
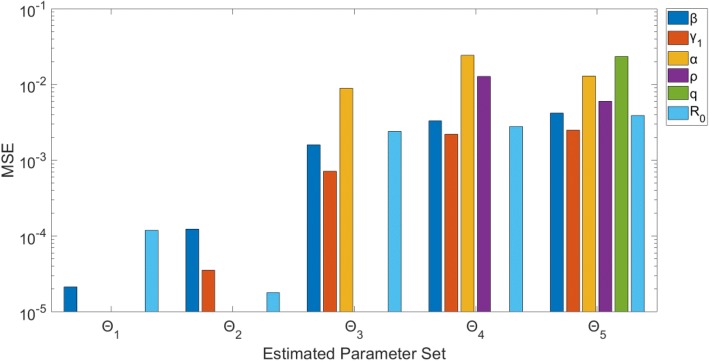
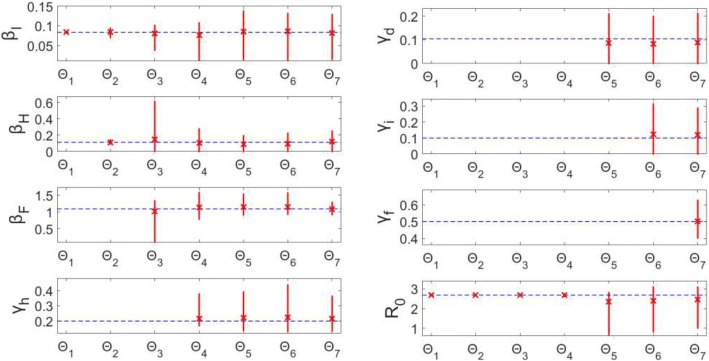
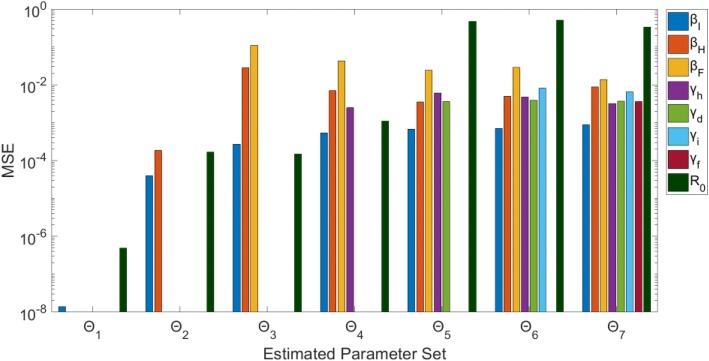
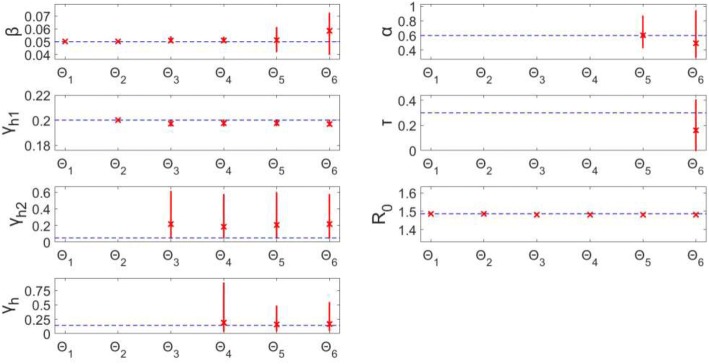
Overall, parameter identifiability issues are more likely to arise with more complex models (based on number of equations/states and parameters). As the number of parameters being jointly estimated increases, the uncertainty surrounding estimated parameters tends to increase, on average, as well. We found that, in most cases, R is often robust to parameter identifiability issues affecting individual parameters in the model. Despite large confidence intervals and higher mean squared error of other individual model parameters, R can still be estimated with precision and accuracy.
Because public health policies can be influenced by results of mathematical modeling studies, it is important to conduct parameter identifiability analyses prior to fitting the models to available data and to report parameter estimates with quantified uncertainty. The method described is helpful in these regards and enhances the essential toolkit for conducting model-based inferences using compartmental dynamic models.
数学建模如今在疫情调查中经常被用于理解传染病动态的潜在机制、评估流行病学数据模式以及预测疫情发展轨迹。然而,数学模型成功应用于指导公共卫生干预措施的关键在于能够可靠地估计模型参数及其相应的不确定性。在此,我们提出并阐述一种用于评估 compartmental 疫情模型中参数可识别性的简单计算方法。
我们描述了一种参数自抽样方法,用于从动态系统生成模拟数据,以量化参数不确定性和可识别性。我们计算估计参数分布的置信区间和均方误差,以评估参数可识别性。为了演示这种方法,我们从一个低复杂度的 SEIR 模型开始,并逐步分析越来越复杂的 compartmental 模型的示例,这些模型分别对应于大流行性流感、埃博拉和寨卡病毒的应用场景。
总体而言,更复杂的模型(基于方程/状态和参数的数量)更有可能出现参数可识别性问题。随着联合估计的参数数量增加,估计参数周围的不确定性平均而言也往往会增加。我们发现,在大多数情况下,R 通常对影响模型中单个参数的参数可识别性问题具有稳健性。尽管其他单个模型参数的置信区间较大且均方误差较高,但仍可以精确且准确地估计 R。
由于公共卫生政策可能会受到数学建模研究结果的影响,因此在将模型拟合到现有数据之前进行参数可识别性分析,并报告具有量化不确定性的参数估计值非常重要。所描述的方法在这些方面很有帮助,并增强了使用 compartmental 动态模型进行基于模型的推断的基本工具集。