Lee Scott H
Centers for Disease Control and Prevention, Atlanta, GA, USA.
NPJ Digit Med. 2018 Nov 19;1:63. doi: 10.1038/s41746-018-0070-0. Print 2018.
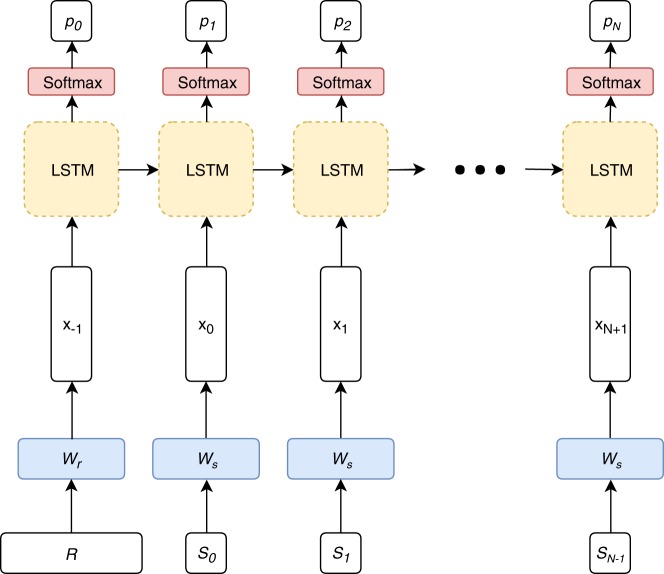
One broad goal of biomedical informatics is to generate fully-synthetic, faithfully representative electronic health records (EHRs) to facilitate data sharing between healthcare providers and researchers and promote methodological research. A variety of methods existing for generating synthetic EHRs, but they are not capable of generating unstructured text, like emergency department (ED) chief complaints, history of present illness, or progress notes. Here, we use the encoder-decoder model, a deep learning algorithm that features in many contemporary machine translation systems, to generate synthetic chief complaints from discrete variables in EHRs, like age group, gender, and discharge diagnosis. After being trained end-to-end on authentic records, the model can generate realistic chief complaint text that appears to preserve the epidemiological information encoded in the original record-sentence pairs. As a side effect of the model's optimization goal, these synthetic chief complaints are also free of relatively uncommon abbreviation and misspellings, and they include none of the personally identifiable information (PII) that was in the training data, suggesting that this model may be used to support the de-identification of text in EHRs. When combined with algorithms like generative adversarial networks (GANs), our model could be used to generate fully-synthetic EHRs, allowing healthcare providers to share faithful representations of multimodal medical data without compromising patient privacy. This is an important advance that we hope will facilitate the development of machine-learning methods for clinical decision support, disease surveillance, and other data-hungry applications in biomedical informatics.
生物医学信息学的一个广泛目标是生成完全合成的、具有忠实代表性的电子健康记录(EHR),以促进医疗保健提供者和研究人员之间的数据共享,并推动方法学研究。现有的多种方法可用于生成合成EHR,但它们无法生成非结构化文本,如急诊科(ED)主诉、现病史或病程记录。在此,我们使用编码器-解码器模型(一种在许多当代机器翻译系统中具有特色的深度学习算法),根据EHR中的离散变量(如年龄组、性别和出院诊断)生成合成主诉。在对真实记录进行端到端训练后,该模型可以生成逼真的主诉文本,这些文本似乎保留了原始记录-句子对中编码的流行病学信息。作为模型优化目标的一个附带效果,这些合成主诉也没有相对罕见的缩写和拼写错误,并且不包含训练数据中的任何个人身份信息(PII),这表明该模型可用于支持EHR中文本的去识别。当与生成对抗网络(GAN)等算法结合使用时,我们的模型可用于生成完全合成的EHR,使医疗保健提供者能够共享多模态医疗数据的忠实表示,而不会损害患者隐私。这是一项重要进展,我们希望它将促进用于临床决策支持、疾病监测以及生物医学信息学中其他数据需求大的应用的机器学习方法的发展。