Chen Tao, Dredze Mark, Weiner Jonathan P, Hernandez Leilani, Kimura Joe, Kharrazi Hadi
Center for Language and Speech Processing, Whiting School of Engineering, Johns Hopkins University, Baltimore, MD, United States.
Department of Computer Science, Whiting School of Engineering, Johns Hopkins University, Baltimore, MD, United States.
JMIR Med Inform. 2019 Mar 26;7(1):e13039. doi: 10.2196/13039.
Geriatric syndromes in older adults are associated with adverse outcomes. However, despite being reported in clinical notes, these syndromes are often poorly captured by diagnostic codes in the structured fields of electronic health records (EHRs) or administrative records.
We aim to automatically determine if a patient has any geriatric syndromes by mining the free text of associated EHR clinical notes. We assessed which statistical natural language processing (NLP) techniques are most effective.
We applied conditional random fields (CRFs), a widely used machine learning algorithm, to identify each of 10 geriatric syndrome constructs in a clinical note. We assessed three sets of features and attributes for CRF operations: a base set, enhanced token, and contextual features. We trained the CRF on 3901 manually annotated notes from 85 patients, tuned the CRF on a validation set of 50 patients, and evaluated it on 50 held-out test patients. These notes were from a group of US Medicare patients over 65 years of age enrolled in a Medicare Advantage Health Maintenance Organization and cared for by a large group practice in Massachusetts.
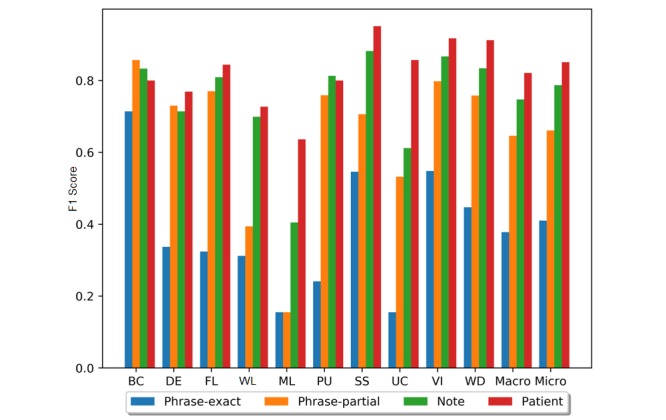
A final feature set was formed through comprehensive feature ablation experiments. The final CRF model performed well at patient-level determination (macroaverage F1=0.834, microaverage F1=0.851); however, performance varied by construct. For example, at phrase-partial evaluation, the CRF model worked well on constructs such as absence of fecal control (F1=0.857) and vision impairment (F1=0.798) but poorly on malnutrition (F1=0.155), weight loss (F1=0.394), and severe urinary control issues (F1=0.532). Errors were primarily due to previously unobserved words (ie, out-of-vocabulary) and a lack of context.
This study shows that statistical NLP can be used to identify geriatric syndromes from EHR-extracted clinical notes. This creates new opportunities to identify patients with geriatric syndromes and study their health outcomes.
老年人的老年综合征与不良后果相关。然而,尽管这些综合征在临床记录中有报告,但在电子健康记录(EHR)或行政记录的结构化字段中,诊断代码往往难以准确捕捉到这些综合征。
我们旨在通过挖掘相关EHR临床记录的自由文本,自动确定患者是否患有任何老年综合征。我们评估了哪些统计自然语言处理(NLP)技术最有效。
我们应用条件随机字段(CRF),一种广泛使用的机器学习算法,在临床记录中识别10种老年综合征结构中的每一种。我们评估了用于CRF操作的三组特征和属性:基础集、增强令牌和上下文特征。我们在来自85名患者的3901份人工标注记录上训练CRF,在50名患者的验证集上调整CRF,并在50名预留测试患者上进行评估。这些记录来自一组年龄超过65岁的美国医疗保险患者,他们参加了医疗保险优势健康维护组织,并由马萨诸塞州的一个大型团体诊所提供护理。
通过全面的特征消融实验形成了最终的特征集。最终的CRF模型在患者水平的判定上表现良好(宏观平均F1 = 0.834,微观平均F1 = 0.851);然而,不同结构的表现有所不同。例如,在短语部分评估中,CRF模型在诸如大便失禁(F1 = 0.857)和视力障碍(F1 = 0.798)等结构上表现良好,但在营养不良(F1 = 0.155)、体重减轻(F1 = 0.394)和严重的排尿控制问题(F1 = 0.532)上表现不佳。错误主要是由于以前未观察到的单词(即词汇外)和缺乏上下文。
本研究表明,统计NLP可用于从EHR提取的临床记录中识别老年综合征。这为识别患有老年综合征的患者并研究他们的健康结果创造了新的机会。