Population Health Sciences, Bristol Medical School, University of Bristol, Oakfield House, Oakfield Grove, Bristol BS8 2BN, UK.
Population Health Sciences, Bristol Medical School, University of Bristol, Oakfield House, Oakfield Grove, Bristol BS8 2BN, UK; MRC Integrative Epidemiology Unit, University of Bristol, Oakfield House, Oakfield Grove, Bristol BS8 2BN, UK.
J Clin Epidemiol. 2019 Jun;110:63-73. doi: 10.1016/j.jclinepi.2019.02.016. Epub 2019 Mar 13.
Researchers are concerned whether multiple imputation (MI) or complete case analysis should be used when a large proportion of data are missing. We aimed to provide guidance for drawing conclusions from data with a large proportion of missingness.
Via simulations, we investigated how the proportion of missing data, the fraction of missing information (FMI), and availability of auxiliary variables affected MI performance. Outcome data were missing completely at random or missing at random (MAR).
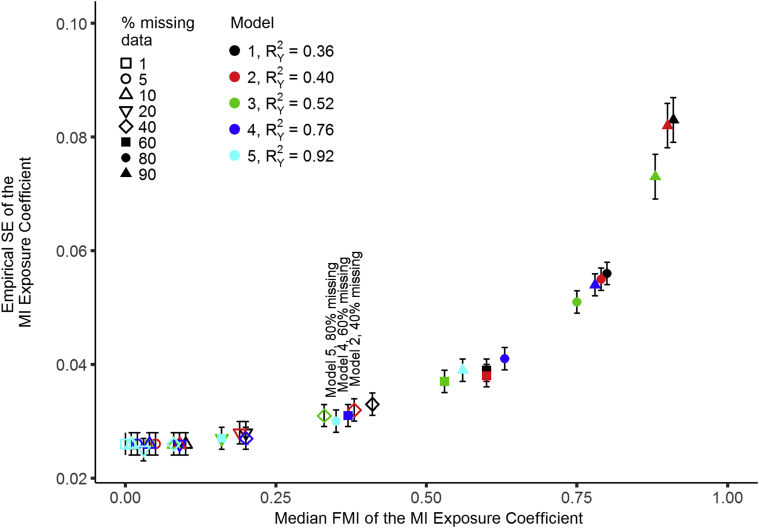
Provided sufficient auxiliary information was available; MI was beneficial in terms of bias and never detrimental in terms of efficiency. Models with similar FMI values, but differing proportions of missing data, also had similar precision for effect estimates. In the absence of bias, the FMI was a better guide to the efficiency gains using MI than the proportion of missing data.
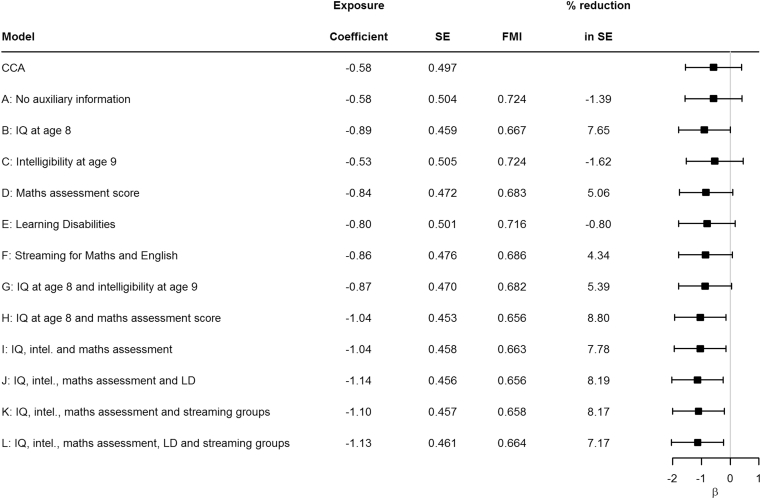
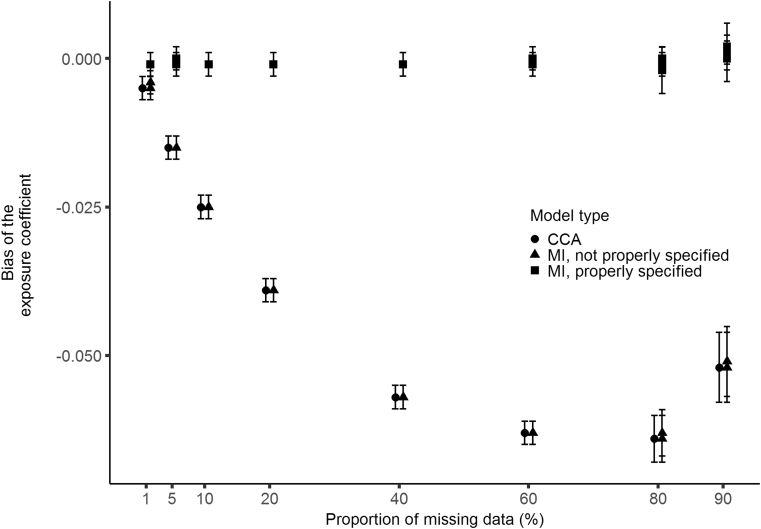
We provide evidence that for MAR data, valid MI reduces bias even when the proportion of missingness is large. We advise researchers to use FMI to guide choice of auxiliary variables for efficiency gain in imputation analyses, and that sensitivity analyses including different imputation models may be needed if the number of complete cases is small.
当大量数据缺失时,研究人员关注应使用多重插补(MI)还是完全案例分析。本研究旨在为从大量缺失数据中得出结论提供指导。
通过模拟,我们研究了缺失数据的比例、缺失信息量(FMI)和辅助变量的可用性如何影响 MI 的性能。结局数据完全随机缺失或随机缺失(MAR)。
只要有足够的辅助信息可用;MI 在偏差方面是有益的,在效率方面从未有害。具有相似 FMI 值但缺失数据比例不同的模型,其效应估计的精度也相似。在不存在偏差的情况下,FMI 比缺失数据的比例更能指导使用 MI 获得效率增益。
我们提供的证据表明,对于 MAR 数据,有效的 MI 即使在缺失率较大的情况下也能减少偏差。我们建议研究人员使用 FMI 来指导辅助变量的选择,以提高插补分析的效率增益,并且如果完整案例数较少,则可能需要包括不同插补模型的敏感性分析。