Department of Population Health Sciences, Bristol Medical School, University of Bristol, Bristol, UK.
Medical Research Council Integrative Epidemiology Unit at the University of Bristol, University of Bristol, Bristol, UK.
BMC Med Res Methodol. 2024 Oct 7;24(1):231. doi: 10.1186/s12874-024-02353-9.
Epidemiological and clinical studies often have missing data, frequently analysed using multiple imputation (MI). In general, MI estimates will be biased if data are missing not at random (MNAR). Bias due to data MNAR can be reduced by including other variables ("auxiliary variables") in imputation models, in addition to those required for the substantive analysis. Common advice is to take an inclusive approach to auxiliary variable selection (i.e. include all variables thought to be predictive of missingness and/or the missing values). There are no clear guidelines about the impact of this strategy when data may be MNAR.
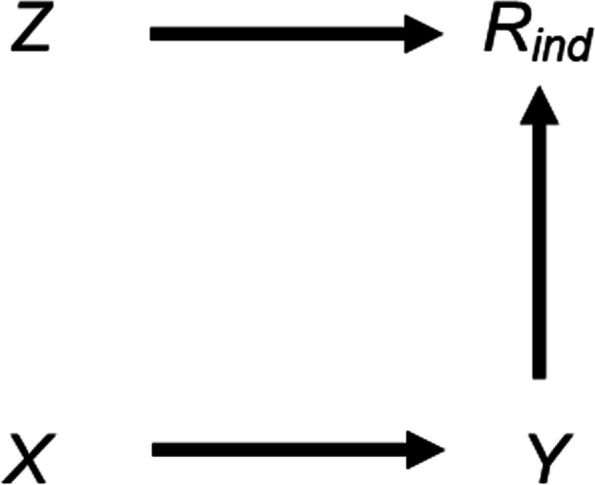
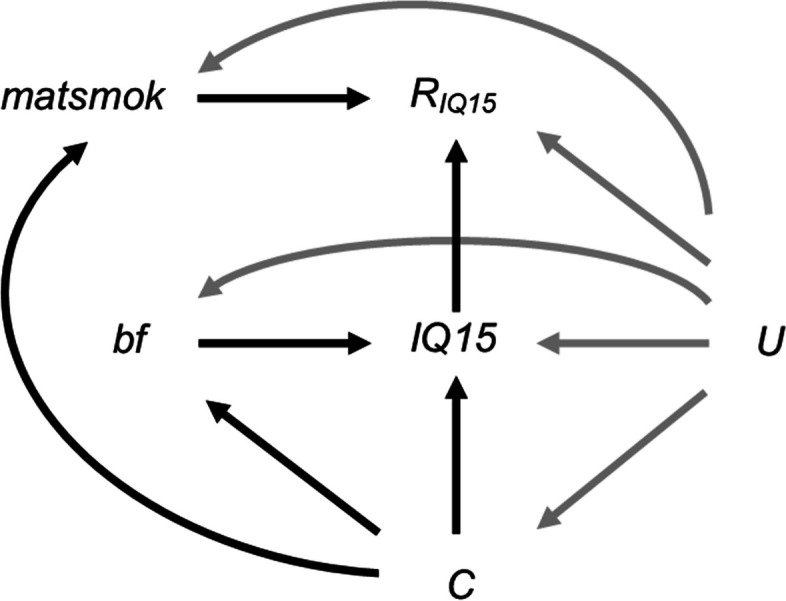
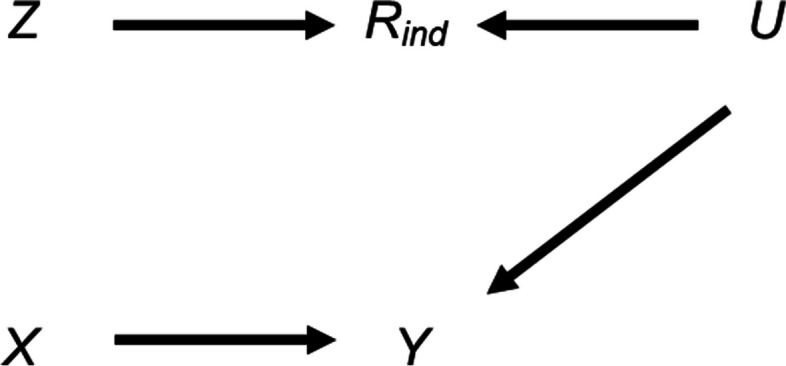
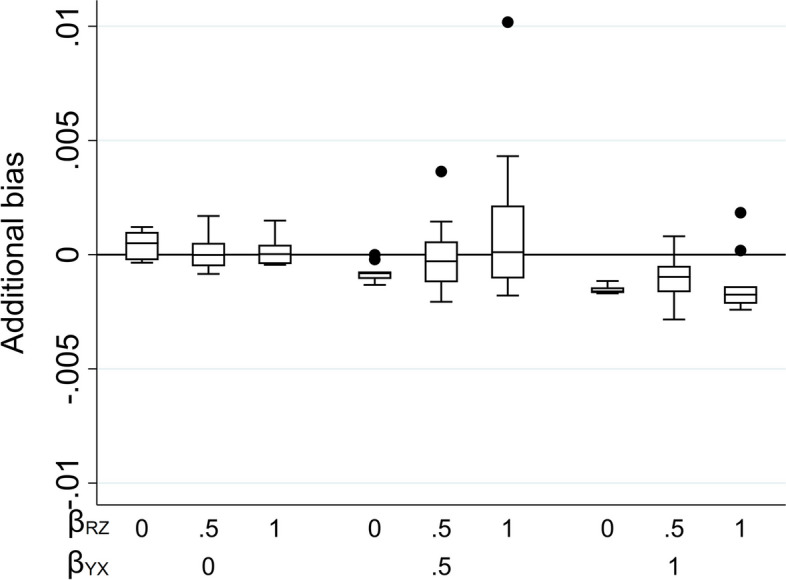
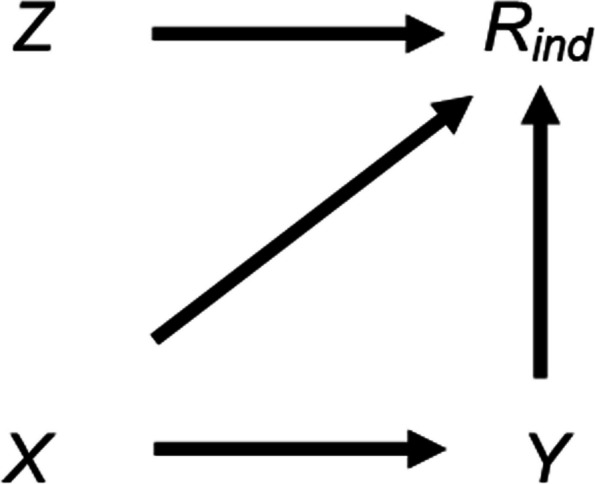
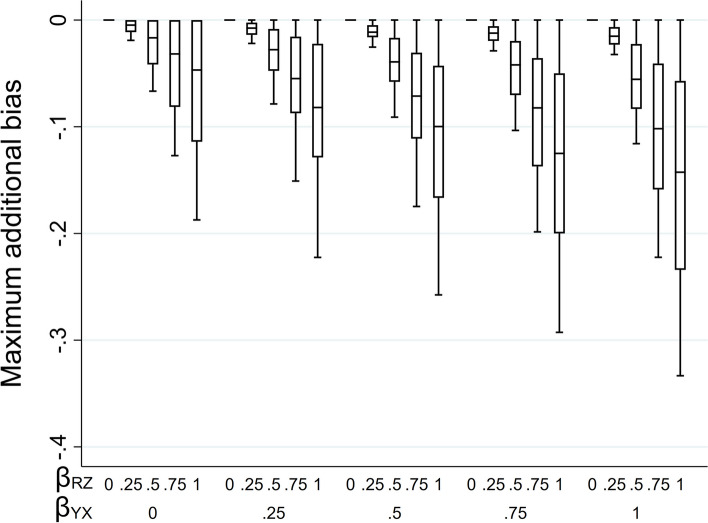
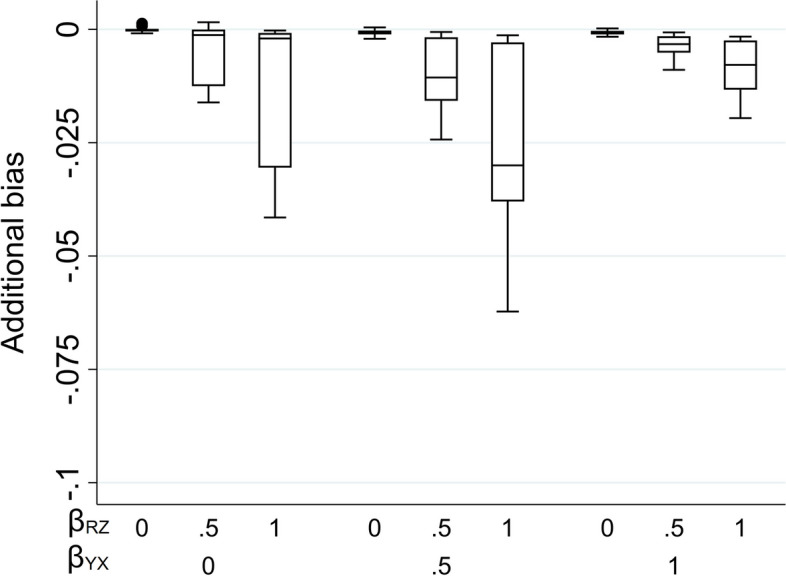
We explore the impact of including an auxiliary variable predictive of missingness but, in truth, unrelated to the partially observed variable, when data are MNAR. We quantify, algebraically and by simulation, the magnitude of the additional bias of the MI estimator for the exposure coefficient (fitting either a linear or logistic regression model), when the (continuous or binary) partially observed variable is either the analysis outcome or the exposure. Here, "additional bias" refers to the difference in magnitude of the MI estimator when the imputation model includes (i) the auxiliary variable and the other analysis model variables; (ii) just the other analysis model variables, noting that both will be biased due to data MNAR. We illustrate the extent of this additional bias by re-analysing data from a birth cohort study.
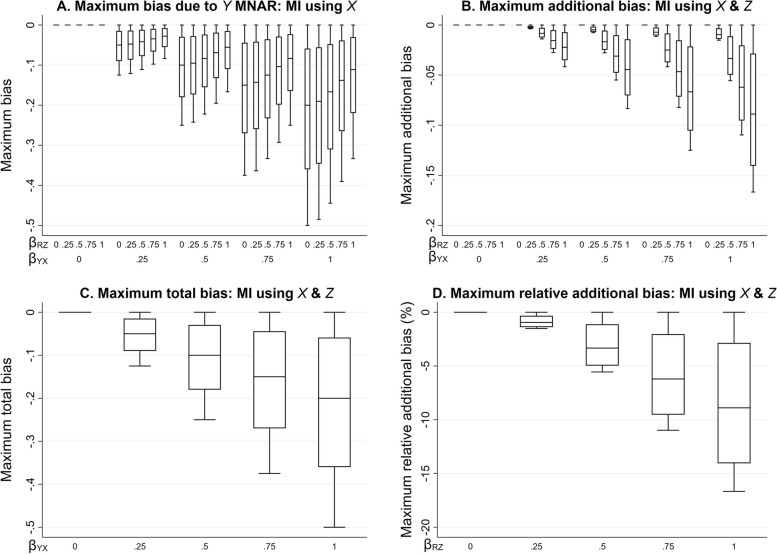
The additional bias can be relatively large when the outcome is partially observed and missingness is caused by the outcome itself, and even larger if missingness is caused by both the outcome and the exposure (when either the outcome or exposure is partially observed).
When using MI, the naïve and commonly used strategy of including all available auxiliary variables should be avoided. We recommend including the variables most predictive of the partially observed variable as auxiliary variables, where these can be identified through consideration of the plausible casual diagrams and missingness mechanisms, as well as data exploration (noting that associations with the partially observed variable in the complete records may be distorted due to selection bias).
流行病学和临床研究经常存在缺失数据,通常使用多重插补(MI)进行分析。一般来说,如果数据缺失不是随机的(MNAR),则 MI 估计值会存在偏差。通过在插补模型中除了包含实质性分析所需的变量之外,还包含其他变量(“辅助变量”),可以减少由于数据 MNAR 引起的偏差。通常的建议是采取包容性的辅助变量选择方法(即,包含所有被认为可预测缺失和/或缺失值的变量)。当数据可能 MNAR 时,关于这种策略的影响还没有明确的指导方针。
我们探讨了当数据 MNAR 时,包含一个可预测缺失但实际上与部分观察变量无关的辅助变量对暴露系数 MI 估计值的额外偏差的影响。我们通过代数和模拟的方式量化了当(连续或二值)部分观察变量是分析结果或暴露时,MI 估计器的额外偏差的大小,拟合线性或逻辑回归模型。在这里,“额外偏差”是指当插补模型包含(i)辅助变量和其他分析模型变量时,MI 估计器的幅度差异;(ii)仅其他分析模型变量,请注意,由于数据 MNAR,两者都会存在偏差。我们通过重新分析出生队列研究的数据来说明这种额外偏差的程度。
当结局部分观察且缺失由结局本身引起时,额外偏差可能相对较大,如果缺失由结局和暴露共同引起(当结局或暴露部分观察时),则额外偏差更大。
在使用 MI 时,应避免使用包括所有可用辅助变量的简单且常用的策略。我们建议将最能预测部分观察变量的变量作为辅助变量包含在内,这些变量可以通过考虑合理的因果图和缺失机制以及数据探索来确定(请注意,由于选择偏差,与完整记录中部分观察变量的关联可能会失真)。