Curnow Elinor, Tilling Kate, Heron Jon E, Cornish Rosie P, Carpenter James R
Department of Population Health Sciences, Bristol Medical School, University of Bristol, Bristol, United Kingdom.
Medical Research Council Integrative Epidemiology Unit at the University of Bristol, University of Bristol, Bristol, United Kingdom.
Front Epidemiol. 2023 Sep 15;3:1237447. doi: 10.3389/fepid.2023.1237447.
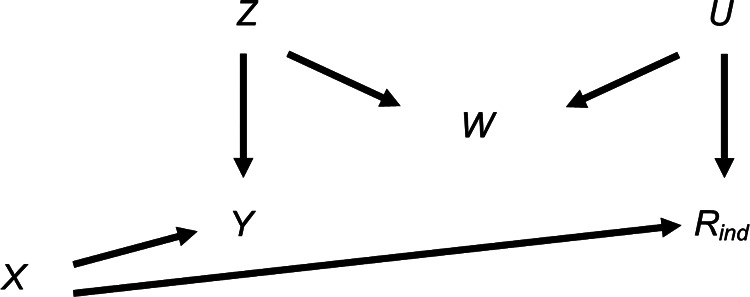
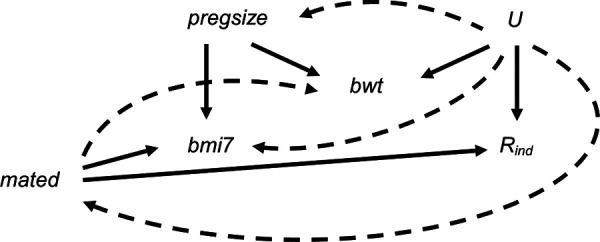
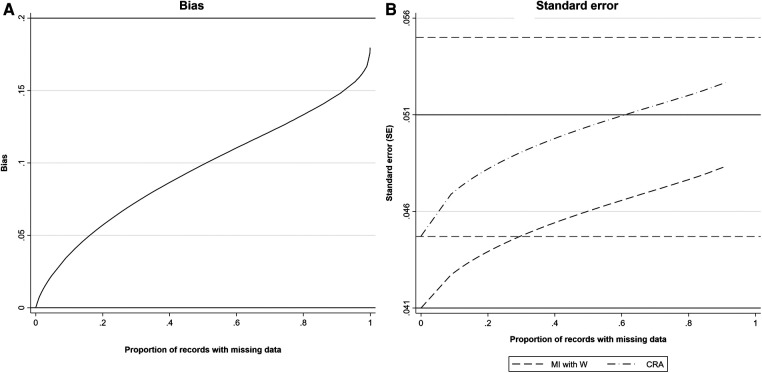
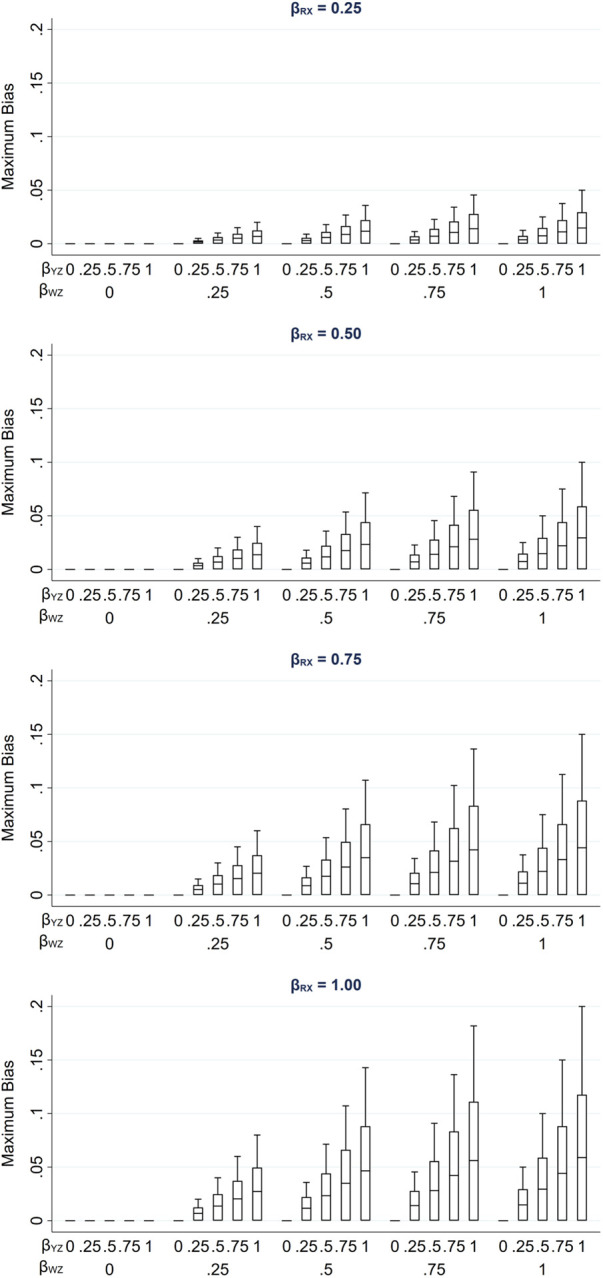
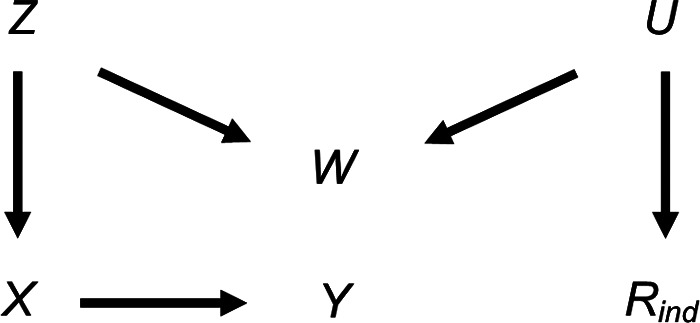
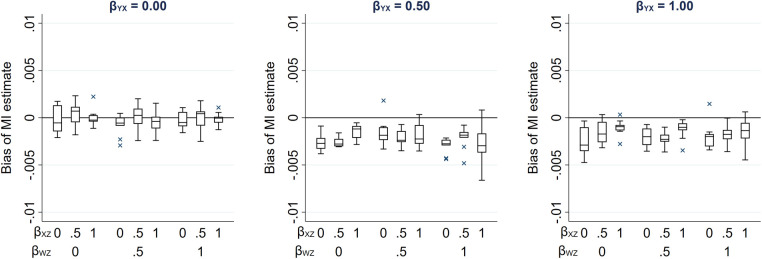
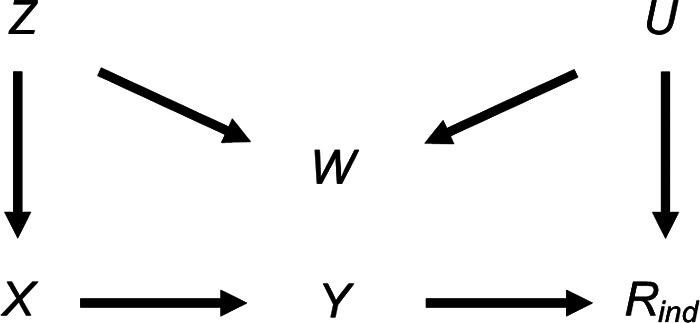
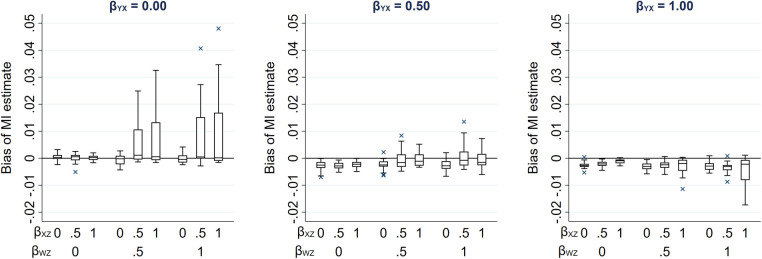
Epidemiological studies often have missing data, which are commonly handled by multiple imputation (MI). In MI, in addition to those required for the substantive analysis, imputation models often include other variables ("auxiliary variables"). Auxiliary variables that predict the partially observed variables can reduce the standard error (SE) of the MI estimator and, if they also predict the probability that data are missing, reduce bias due to data being missing not at random. However, guidance for choosing auxiliary variables is lacking. We examine the consequences of a poorly chosen auxiliary variable: if it shares a common cause with the partially observed variable and the probability that it is missing (i.e., it is a "collider"), its inclusion can induce bias in the MI estimator and may increase the SE. We quantify, both algebraically and by simulation, the magnitude of bias and SE when either the exposure or outcome is incomplete. When the substantive analysis outcome is partially observed, the bias can be substantial, relative to the magnitude of the exposure coefficient. In settings in which a complete records analysis is valid, the bias is smaller when the exposure is partially observed. However, bias can be larger if the outcome also causes missingness in the exposure. When using MI, it is important to examine, through a combination of data exploration and considering plausible casual diagrams and missingness mechanisms, whether potential auxiliary variables are colliders.
流行病学研究常常存在缺失数据,通常采用多重填补(MI)方法来处理。在多重填补中,除了实质性分析所需的变量外,填补模型通常还包括其他变量(“辅助变量”)。能够预测部分观测变量的辅助变量可以降低多重填补估计量的标准误差(SE),并且,如果它们还能预测数据缺失的概率,还可以减少因数据非随机缺失而导致的偏差。然而,目前缺乏关于选择辅助变量的指导。我们研究了选择不当的辅助变量所带来的后果:如果它与部分观测变量以及其自身缺失的概率有共同的原因(即它是一个“对撞机”),那么将其纳入可能会在多重填补估计量中引入偏差,并且可能会增加标准误差。我们通过代数方法和模拟,量化了暴露或结局不完全时偏差和标准误差的大小。当实质性分析的结局部分被观测到时,相对于暴露系数的大小,偏差可能会很大。在完整记录分析有效的情况下,当暴露部分被观测到时,偏差较小。然而,如果结局也导致暴露数据缺失,偏差可能会更大。在使用多重填补时,通过数据探索、考虑合理的因果图和缺失机制相结合的方式,检查潜在的辅助变量是否为对撞机是很重要的。