Division of Gastroenterology and Division of Biomedical Informatics, Department of Medicine, University of California San Diego, La Jolla, California, USA.
Clin Transl Gastroenterol. 2019 Mar;10(3):e00018. doi: 10.14309/ctg.0000000000000018.
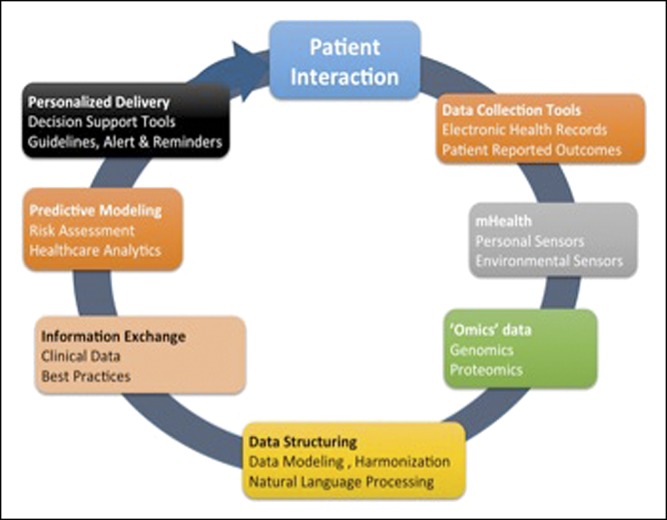
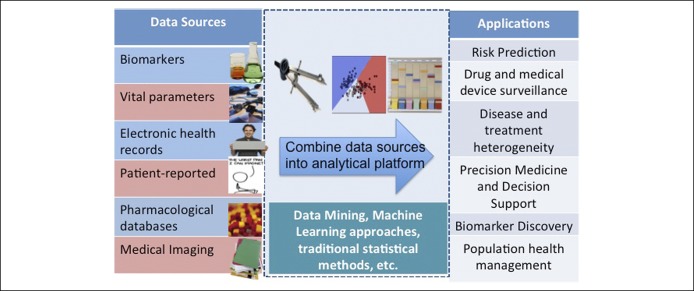
As the complexity of biomedical data increases, so do the opportunities to leverage them to advance science and clinical care. Electronic health records form a rich but complex source of large amounts of data gathered during routine clinical care. Through the use of codified and free-text concepts identified using clinical informatics tools such as natural language processing, disease phenotyping can be performed with a high degree of accuracy. Technologies such as genome sequencing, gene expression profiling, proteomic and metabolomic analyses, and electronic devices and wearables are generating large amounts of data from various populations, cell types, and disorders (big data). However, to make these data useable for the next step of biomarker discovery, precision medicine, and clinical practice, it is imperative to harmonize and integrate these diverse data sources. In this article, we introduce important building blocks for precision medicine, including common data models, text mining and natural language processing, privacy-preserved record linkage, machine learning for predictive modeling, and health information exchange.
随着生物医学数据的复杂性不断增加,利用这些数据来推动科学和临床护理的机会也越来越多。电子健康记录是一种丰富但复杂的数据源,其中包含了在常规临床护理过程中收集的大量数据。通过使用临床信息学工具(如自然语言处理)识别编码和非文本概念,可以以高度的准确性进行疾病表型分析。基因组测序、基因表达谱分析、蛋白质组学和代谢组学分析以及电子设备和可穿戴设备等技术正在从各种人群、细胞类型和疾病(大数据)中生成大量数据。然而,要使这些数据可用于下一步的生物标志物发现、精准医学和临床实践,就必须协调和整合这些多样化的数据源。在本文中,我们介绍了精准医学的重要组成部分,包括常见的数据模型、文本挖掘和自然语言处理、隐私保护的记录链接、用于预测建模的机器学习以及健康信息交换。