School of BioSciences, University of Melbourne, Parkville, Australia.
Statistical Consulting Centre, University of Melbourne, Parkville, Australia.
PLoS One. 2019 Apr 5;14(4):e0214671. doi: 10.1371/journal.pone.0214671. eCollection 2019.
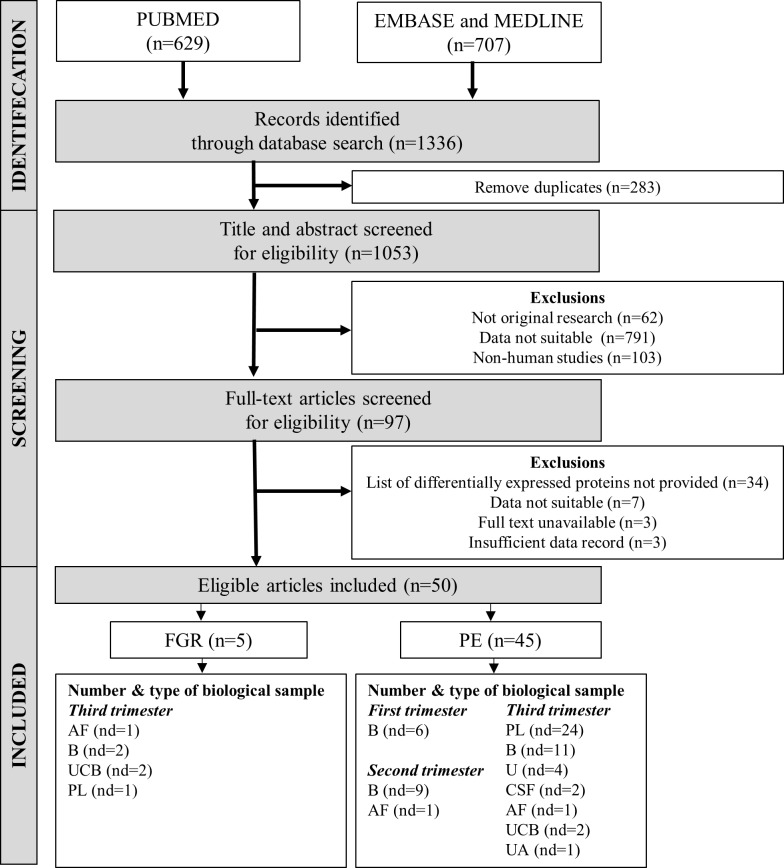
Preeclampsia (PE) is a leading cause of maternal and perinatal morbidity and mortality worldwide. Although predictive multiparametric screening is being developed, it is not applicable to nulliparous women, and is not applied to low-risk women. As PE is considered a heterogenous disorder, it is unlikely that any single multiparametric screening protocol containing a small group of biomarkers could have the required accuracy to predict all PE subgroups. Given the etiology of PE is complex and not fully understood, it begs the question, whether the search for biomarkers based on the predominant view of impaired placentation involving factors predominately implicated in angiogenesis and inflammation, has been too limiting. Here we highlight the enormous potential of state-of-the-art, high-throughput proteomics, to provide a comprehensive and unbiased approach to biomarker identification.
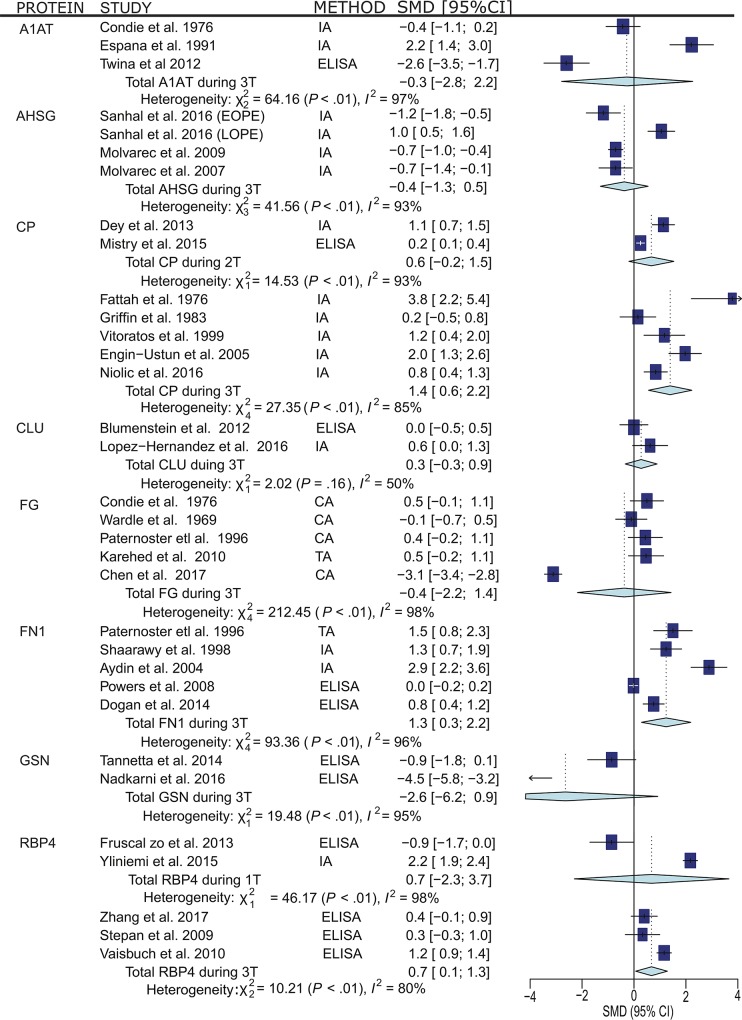
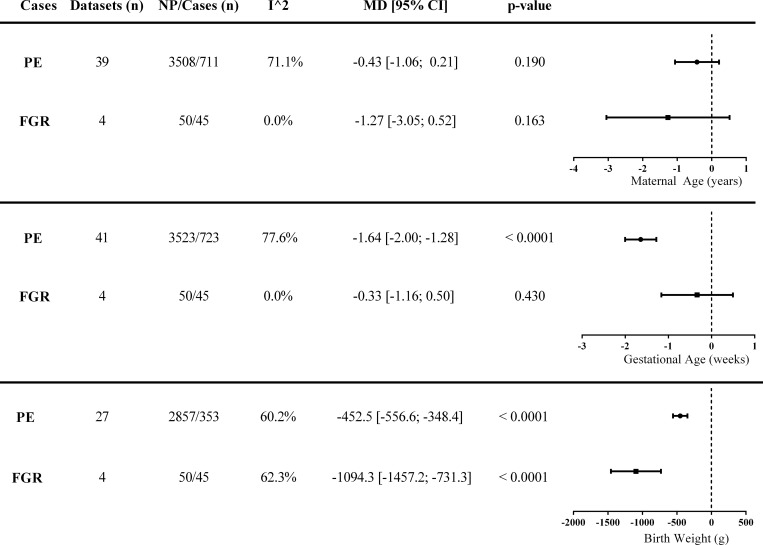
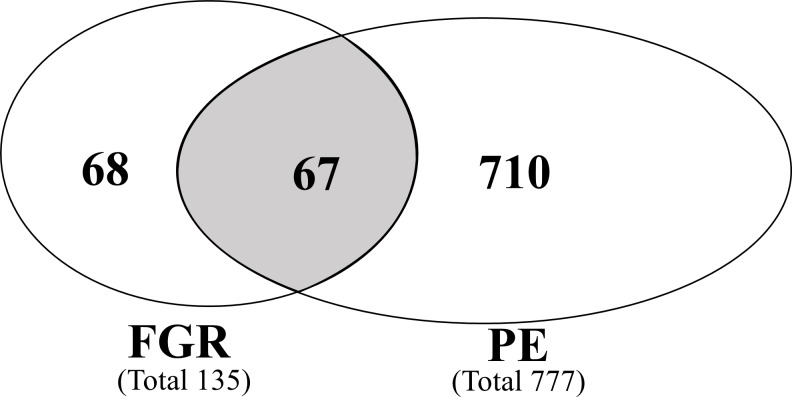
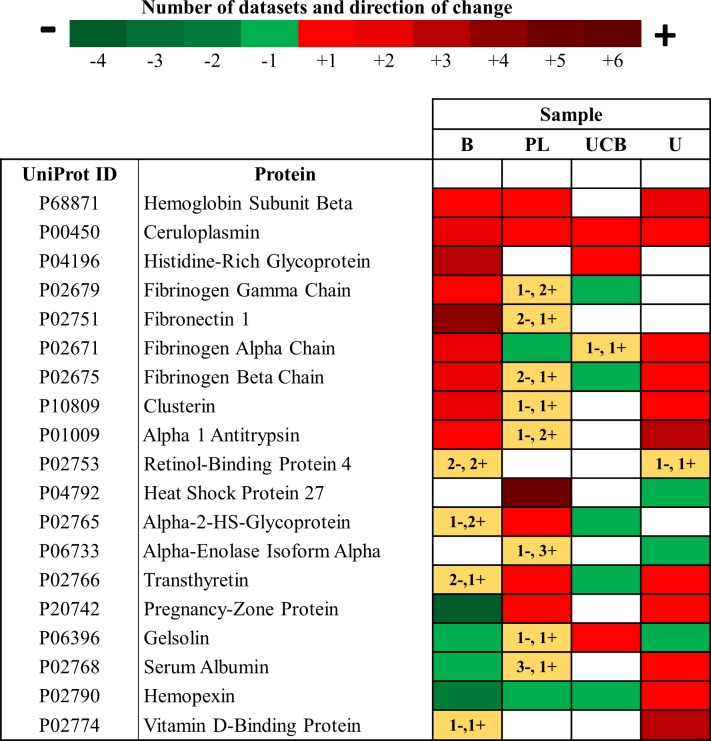
Our literature search identified 1336 articles; after review, 45 studies with proteomic data from PE women that were eligible for inclusion. From 710 proteins with altered abundance, we identified 13 common circulating proteins, some of which had not been previously considered as prospective biomarkers of PE. An additional search of the literature for original publications testing any of the 13 common proteins using non-proteomic techniques was also undertaken. Strikingly, 9 of these common proteins had been independently evaluated in PE studies as potential biomarkers.
This study highlights the potential of using high-throughput data sets, which are comprehensive and without bias, to identify a profile of proteins that may improve predictions of PE and understanding of its etiology. We bring to the attention of the medical and research communities that the strengths and advantages of using data from high-throughput studies for biomarker discovery would be increased dramatically, if first and second trimester samples were collected for proteomics, and if standardized guidelines for patient reporting and data collection were implemented.
子痫前期 (PE) 是全球孕产妇和围产期发病率和死亡率的主要原因。尽管正在开发预测性多参数筛查方法,但它不适用于初产妇,也不适用于低危妇女。由于 PE 被认为是一种异质性疾病,因此不太可能有任何包含少数生物标志物的单一多参数筛查方案具有预测所有 PE 亚组所需的准确性。鉴于 PE 的病因复杂且尚未完全了解,人们不禁要问,基于涉及主要与血管生成和炎症相关因素的受损胎盘的主要观点来寻找生物标志物,是否过于局限。在这里,我们强调了最先进的高通量蛋白质组学的巨大潜力,它为生物标志物的识别提供了一种全面而无偏倚的方法。
我们的文献检索确定了 1336 篇文章;经过审查,有 45 项研究符合纳入条件,这些研究有来自 PE 女性的蛋白质组学数据。在改变丰度的 710 种蛋白质中,我们确定了 13 种常见的循环蛋白,其中一些以前并未被认为是 PE 的前瞻性生物标志物。还对使用非蛋白质组学技术测试这 13 种常见蛋白中任何一种的原始出版物进行了文献检索。令人惊讶的是,其中 9 种常见蛋白已在 PE 研究中作为潜在的生物标志物进行了独立评估。
这项研究强调了使用高通量数据集的潜力,这些数据集全面且无偏倚,可以识别出可能改善 PE 预测和了解其病因的蛋白质谱。我们提请医学界和研究界注意,如果首先在第一和第二孕期采集蛋白质组学样本,并实施患者报告和数据收集的标准化指南,那么使用高通量研究数据进行生物标志物发现的优势和优势将大大增加。