Lark R M, Ander E L, Broadley M R
School of Biosciences, University of Nottingham, Sutton Bonington, Nottinghamshire LE12 5RD UK.
British Geological Survey Keyworth, Nottinghamshire NG12 5GG UK.
Eur J Soil Sci. 2019 Mar;70(2):361-377. doi: 10.1111/ejss.12743. Epub 2018 Nov 23.
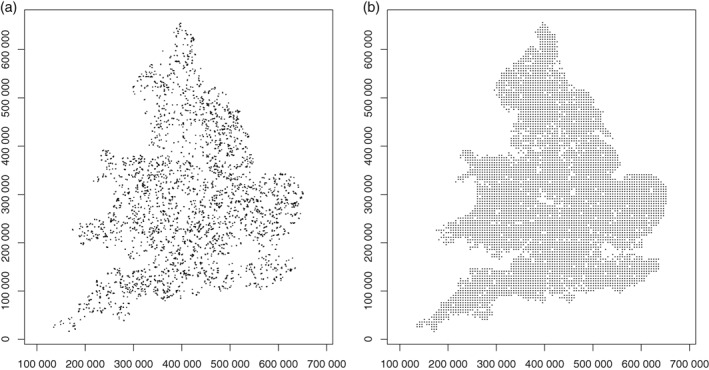
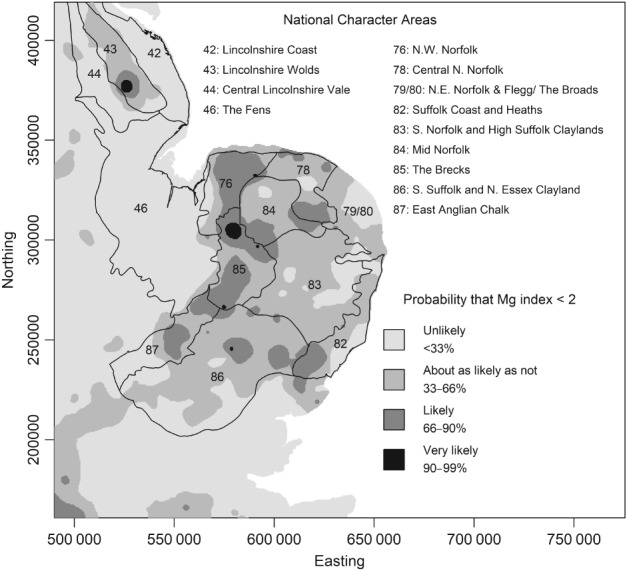
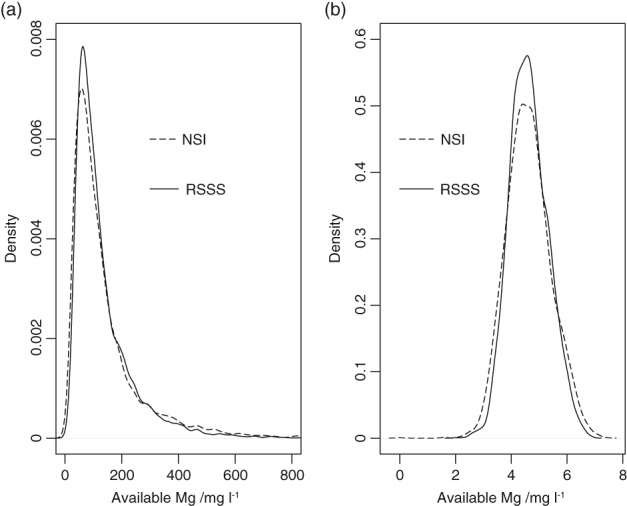
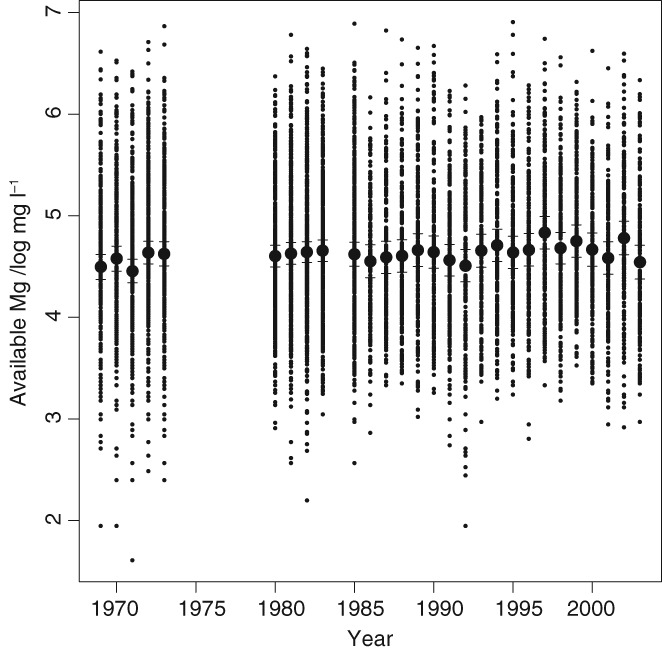
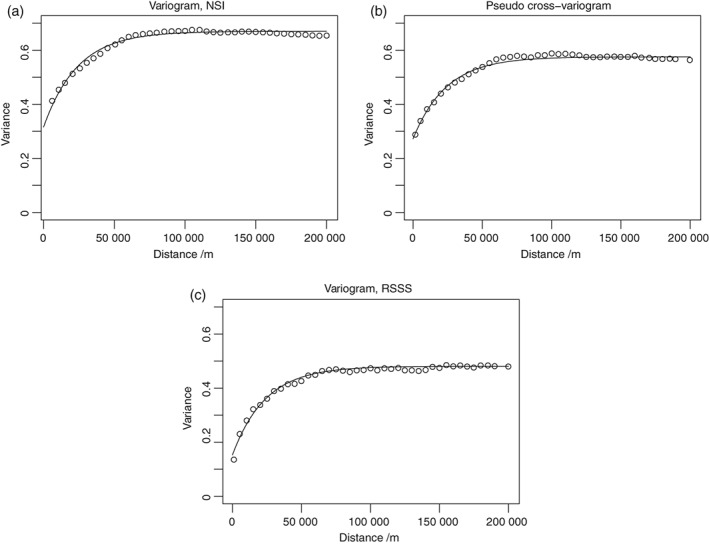
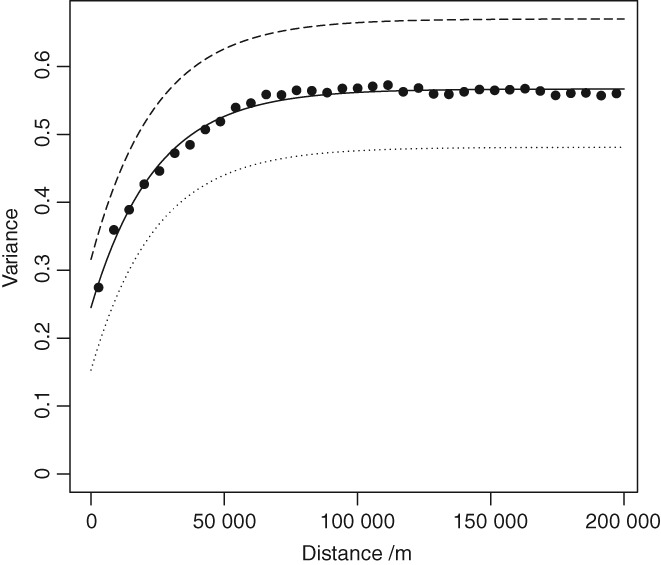
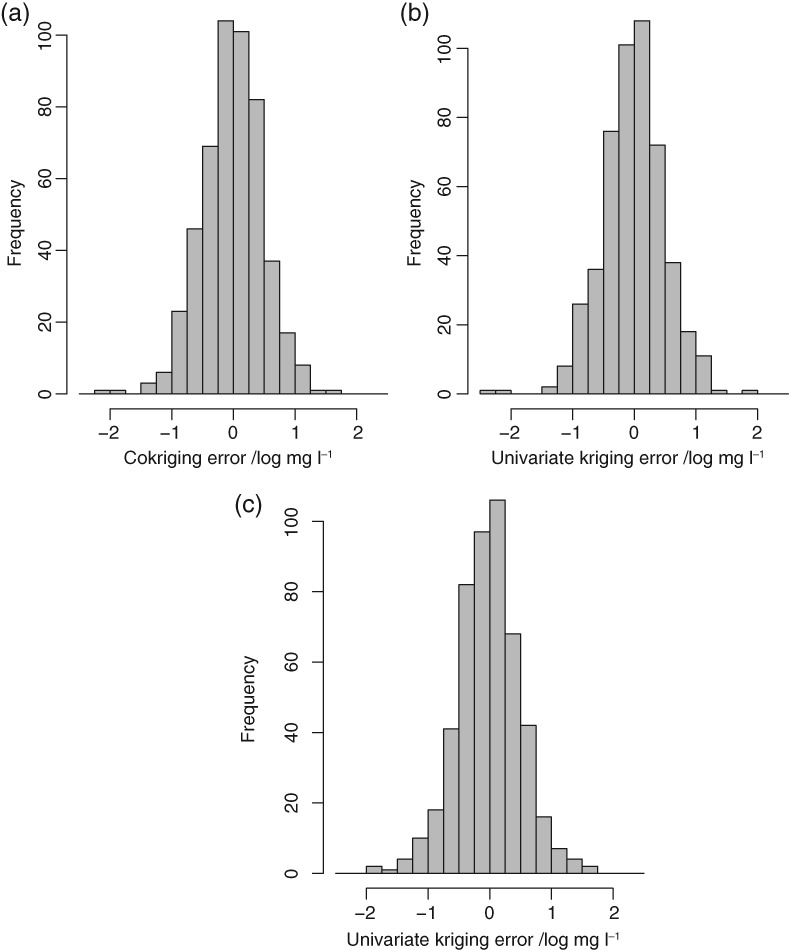
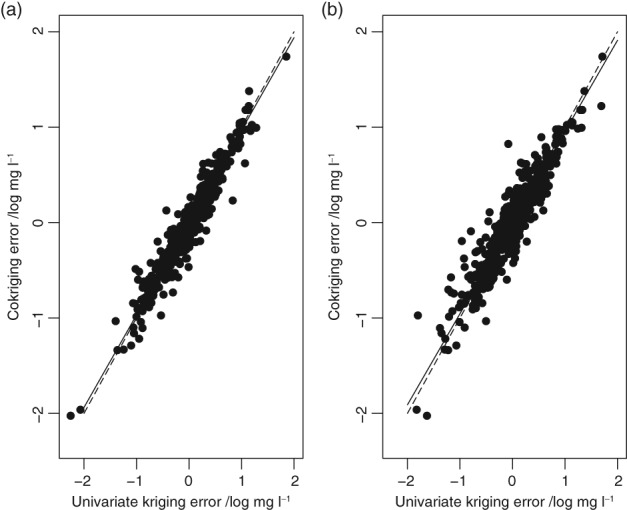
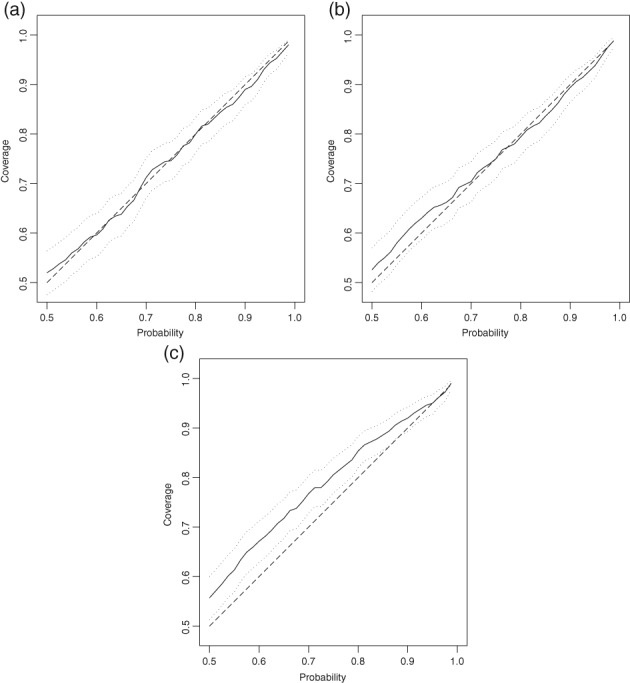
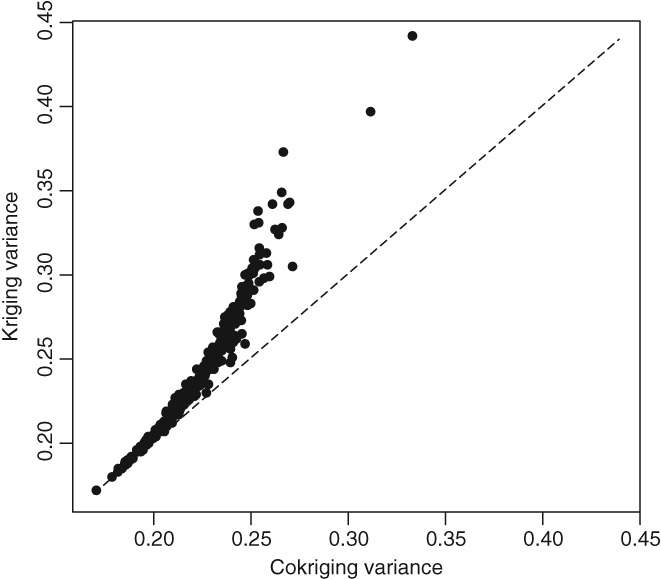
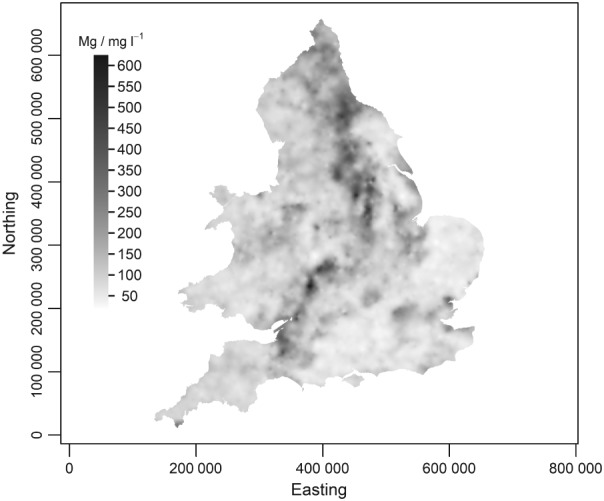
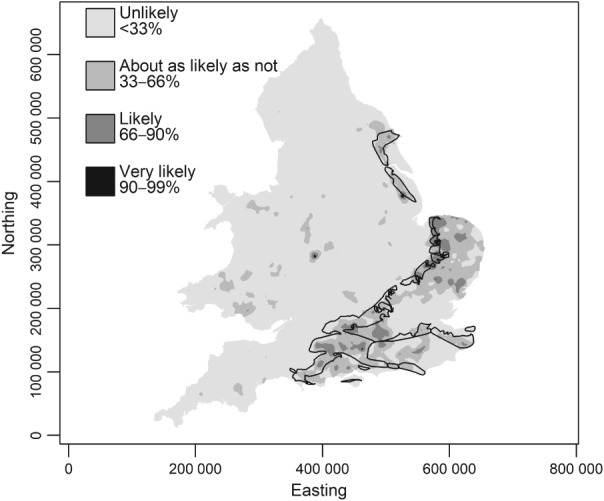
Given the costs of soil survey it is necessary to make the best use of available datasets, but data that differ with respect to some aspect of the sampling or analytical protocol cannot be combined simply. In this paper we consider a case where two datasets were available on the concentration of plant-available magnesium in the topsoil. The datasets were the Representative Soil Sampling Scheme (RSSS) and the National Soil Inventory (NSI) of England and Wales. The variable was measured over the same depth interval and with the same laboratory method, but the sample supports were different and so the datasets differ in their variance. We used a multivariate geostatistical model, the linear model of coregionalization (LMCR), to model the joint spatial distribution of the two datasets. The model allowed us to elucidate the effects of the sample support on the two datasets, and to show that there was a strong correlation between the underlying variables. The LMCR allowed us to make spatial predictions of the variable on the RSSS support by cokriging the RSSS data with the NSI data. We used cross-validation to test the validity of the LMCR and showed how incorporating the NSI data restricted the range of prediction error variances relative to univariate ordinary kriging predictions from the RSSS data alone. The standardized squared prediction errors were computed and the coverage of prediction intervals (i.e. the proportion of sites at which the prediction interval included the observed value of the variable). Both these statistics suggested that the prediction error variances were consistent for the cokriging predictions but not for the ordinary kriging predictions from the simple combination of the RSSS and NSI data, which might be proposed on the basis of their very similar mean values. The LMCR is therefore proposed as a general tool for the combined analysis of different datasets on soil properties.
Differences in sample support mean that two datasets on a soil property cannot be combined simply.We showed how a multivariate geostatistical model can be used to elucidate the relationships between two such datasets.The same model allows soil properties to be mapped jointly from such data.This offers a general basis for combining soil datasets from diverse sources.
鉴于土壤调查的成本,有必要充分利用现有的数据集,但在采样或分析方案的某些方面存在差异的数据不能简单地合并。在本文中,我们考虑了一个案例,其中有两个关于表土中植物可利用镁浓度的数据集。这两个数据集分别是英格兰和威尔士的代表性土壤采样方案(RSSS)和国家土壤清单(NSI)。该变量是在相同的深度区间内使用相同的实验室方法测量的,但样本支撑不同,因此数据集的方差也不同。我们使用了一个多元地质统计模型,即协同区域化线性模型(LMCR),来模拟这两个数据集的联合空间分布。该模型使我们能够阐明样本支撑对这两个数据集的影响,并表明潜在变量之间存在很强的相关性。通过将RSSS数据与NSI数据进行协同克里金法,LMCR使我们能够对RSSS支撑上的变量进行空间预测。我们使用交叉验证来测试LMCR的有效性,并展示了纳入NSI数据相对于仅使用RSSS数据的单变量普通克里金法预测如何限制预测误差方差的范围。计算了标准化平方预测误差和预测区间的覆盖率(即预测区间包含变量观测值的站点比例)。这两个统计数据都表明,协同克里金法预测的预测误差方差是一致的,但对于基于RSSS和NSI数据非常相似的平均值可能提出的简单组合的普通克里金法预测则不然。因此,LMCR被提议作为对不同土壤属性数据集进行综合分析的通用工具。
样本支撑的差异意味着关于土壤属性的两个数据集不能简单地合并。我们展示了如何使用多元地质统计模型来阐明两个这样的数据集之间的关系。相同的模型允许从这些数据中联合绘制土壤属性图。这为合并来自不同来源的土壤数据集提供了一个通用基础。