Guhaniyogi Rajarshi, Banerjee Sudipto
Universisty of California, Santa Cruz.
Universisty of California, Los Angeles.
Technometrics. 2018;60(4):430-444. doi: 10.1080/00401706.2018.1437474. Epub 2018 Jun 6.
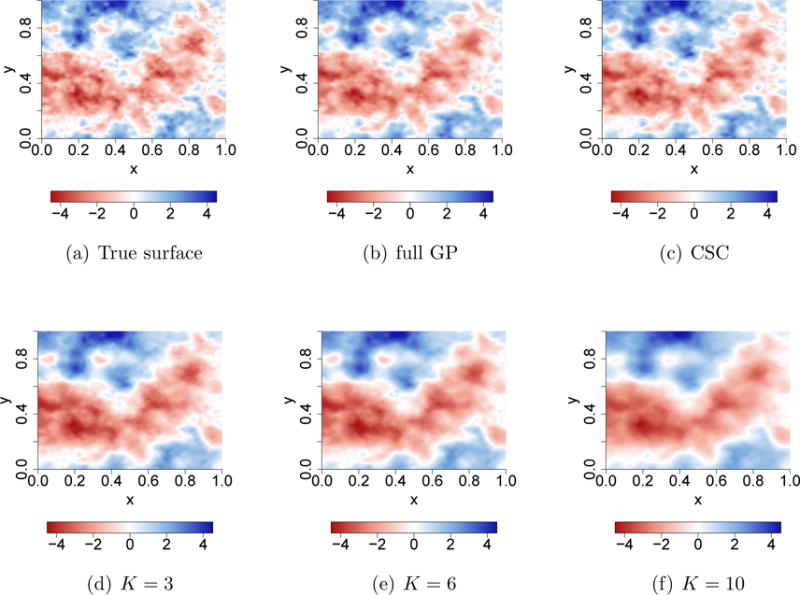
Spatial process models for analyzing geostatistical data entail computations that become prohibitive as the number of spatial locations becomes large. There is a burgeoning literature on approaches for analyzing large spatial datasets. In this article, we propose a divide-and-conquer strategy within the Bayesian paradigm. We partition the data into subsets, analyze each subset using a Bayesian spatial process model and then obtain approximate posterior inference for the entire dataset by combining the individual posterior distributions from each subset. Importantly, as often desired in spatial analysis, we offer full posterior predictive inference at arbitrary locations for the outcome as well as the residual spatial surface after accounting for spatially oriented predictors. We call this approach "Spatial Meta-Kriging" (SMK). We do not need to store the entire data in one processor, and this leads to superior scalability. We demonstrate SMK with various spatial regression models including Gaussian processes and tapered Gaussian processes. The approach is intuitive, easy to implement, and is supported by theoretical results presented in the supplementary material available online. Empirical illustrations are provided using different simulation experiments and a geostatistical analysis of Pacific Ocean sea surface temperature data.
用于分析地理统计数据的空间过程模型所涉及的计算,会随着空间位置数量的增加而变得难以承受。关于分析大型空间数据集的方法,有大量不断涌现的文献。在本文中,我们在贝叶斯范式内提出了一种分而治之的策略。我们将数据划分为子集,使用贝叶斯空间过程模型分析每个子集,然后通过组合每个子集的个体后验分布来获得整个数据集的近似后验推断。重要的是,正如空间分析中经常期望的那样,在考虑空间定向预测变量后,我们为任意位置的结果以及残差空间表面提供完整的后验预测推断。我们将这种方法称为“空间元克里金法”(SMK)。我们无需将整个数据存储在一个处理器中,这带来了卓越的可扩展性。我们用包括高斯过程和渐缩高斯过程在内的各种空间回归模型展示了SMK。该方法直观、易于实现,并得到了在线补充材料中给出的理论结果的支持。使用不同的模拟实验和对太平洋海表温度数据的地理统计分析提供了实证说明。