Yadav Dhyan Chandra, Pal Saurabh
VBS Purvanchal University, Jaunpur, U.P., India. Email:
Asian Pac J Cancer Prev. 2019 Apr 29;20(4):1275-1281. doi: 10.31557/APJCP.2019.20.4.1275.
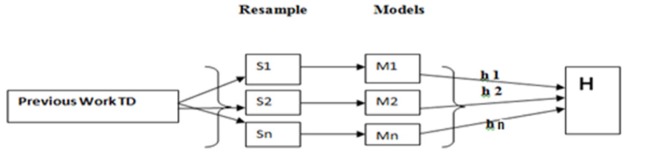
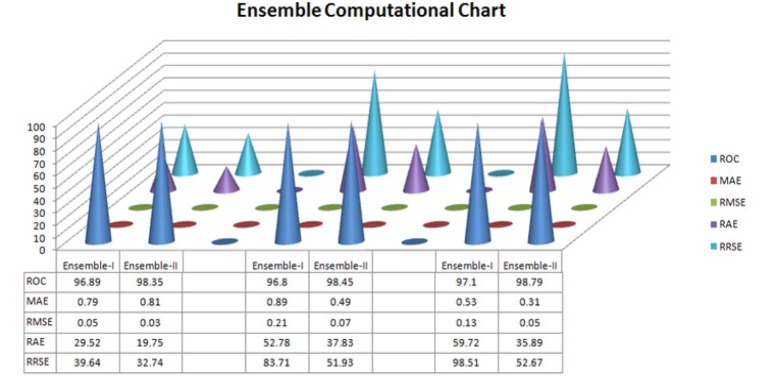
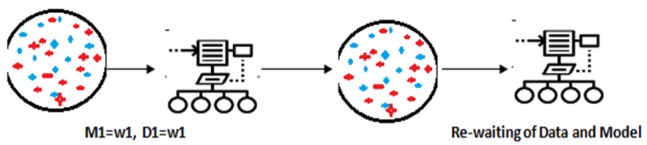
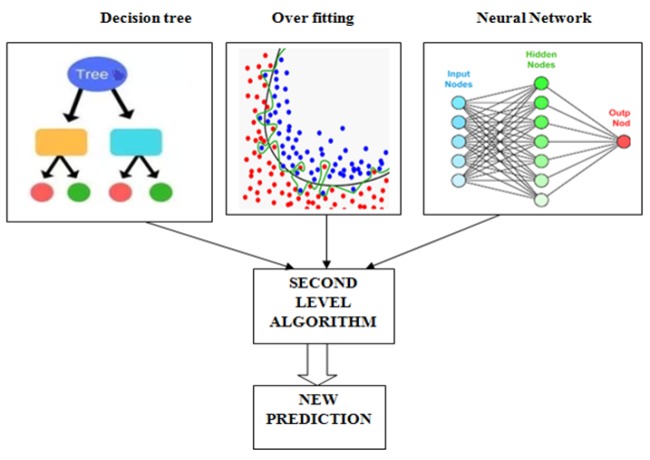
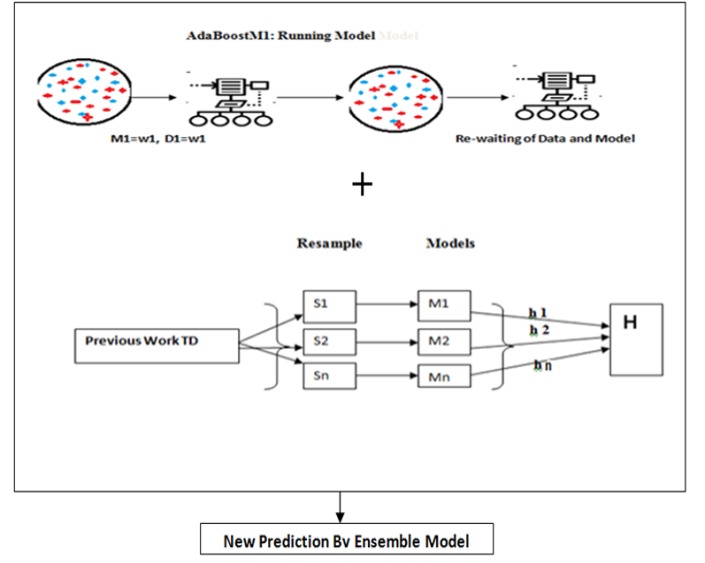
Objective: The main objective of this paper is to easily identify thyroid symptom for treatment. Methods: In this paper two main techniques are proposed for mining the hidden pattern in the dataset. Ensemble-I and Ensemble- II both are machine learning techniques. Ensemble-I generated from decision tree, over fitting and neural network and Ensemble-II generated from combinations of Bagging and Boosting techniques. Finally proposed experiment is conducted by Ensemble-I vs. Ensemble-II. Results: In the entire experimental setup find an ensemble –II generated model is the higher compare to other ensemble-I model. In each experiment observe and compare the value of all the performance of ROC, MAE, RMSE, RAE and RRSE. Stacking (ensemble-I) ensemble model estimate the weights for input with output model by thyroid dataset. After the measurement find out the results ROC=(98.80), MAE= (0.89), 6RMSE=(0.21), RAE= (52.78), RRSE=(83.71)and in the ensemble-II observe thyroid dataset and measure all performance of the model ROC=(98.79), MAE= (0.31), RMSE=(0.05) and RAE= (35.89) and RRSE=(52.67). Finally concluded that (Bagging+ Boosting) ensemble-II model is the best compare to other.
本文的主要目的是轻松识别甲状腺症状以便进行治疗。方法:本文提出了两种主要技术来挖掘数据集中的隐藏模式。集成-I和集成-II都是机器学习技术。集成-I由决策树、过拟合和神经网络生成,集成-II由装袋和提升技术的组合生成。最后由集成-I与集成-II进行所提出的实验。结果:在整个实验设置中发现,与其他集成-I模型相比,集成-II生成的模型性能更高。在每个实验中观察并比较所有性能指标(ROC、MAE、RMSE、RAE和RRSE)的值。堆叠(集成-I)集成模型通过甲状腺数据集估计输入与输出模型的权重。测量后得出结果:ROC=(98.80),MAE=(0.89),RMSE=(0.21),RAE=(52.78),RRSE=(83.71);在集成-II中观察甲状腺数据集并测量模型的所有性能,ROC=(98.79),MAE=(0.31),RMSE=(0.05),RAE=(35.89),RRSE=(52.67)。最后得出结论,(装袋+提升)集成-II模型比其他模型更好。