Department of Chemistry, University of Florida, 214 Leigh Hall, Gainesville, FL, 32611, USA.
College of Engineering, University of Florida, 412 Newell Dr., Gainesville, FL, 32611, USA.
BMC Bioinformatics. 2019 Apr 29;20(1):217. doi: 10.1186/s12859-019-2803-8.
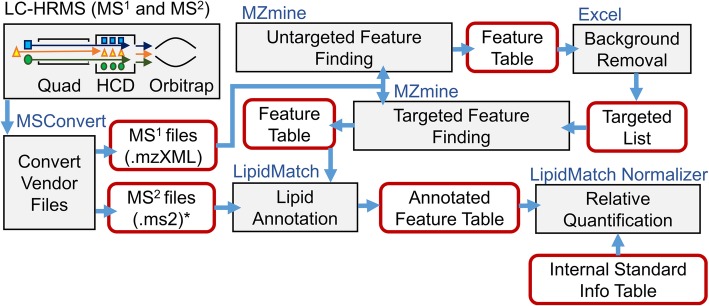
Lipidomics, the comprehensive measurement of lipids within a biological system or substrate, is an emerging field with significant potential for improving clinical diagnosis and our understanding of health and disease. While lipids diverse biological roles contribute to their clinical utility, the diversity of lipid structure and concentrations prove to make lipidomics analytically challenging. Without internal standards to match each lipid species, researchers often apply individual internal standards to a broad range of related lipids. To aid in standardizing and automating this relative quantitation process, we developed LipidMatch Normalizer (LMN) http://secim.ufl.edu/secim-tools/ which can be used in most open source lipidomics workflows.
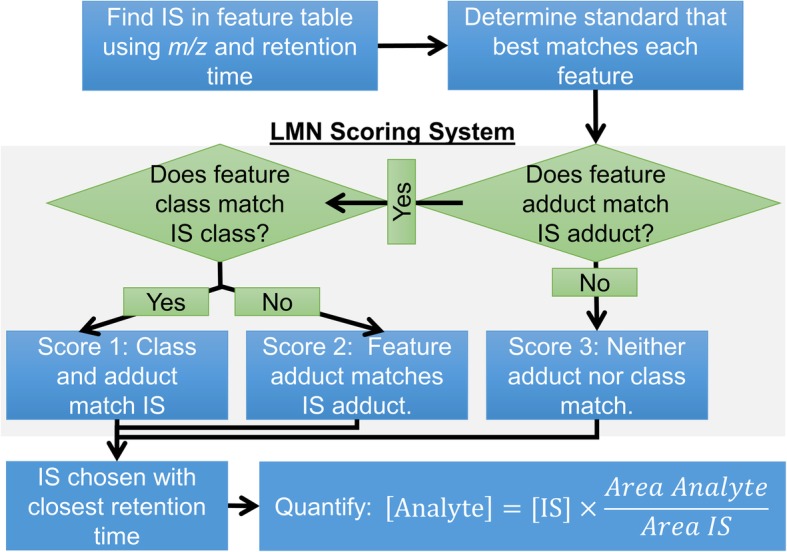
LMN uses a ranking system (1-3) to assign lipid standards to target analytes. A ranking of 1 signifies that both the lipid class and adduct of the internal standard and target analyte match, while a ranking of 3 signifies that neither the adduct or class match. If multiple internal standards are provided for a lipid class, standards with the closest retention time to the target analyte will be chosen. The user can also signify which lipid classes an internal standard represents, for example indicating that ether-linked phosphatidylcholine can be semi-quantified using phosphatidylcholine. LMN is designed to work with any lipid identification software and feature finding software, and in this study is used to quantify lipids in NIST SRM 1950 human plasma annotated using LipidMatch and MZmine.
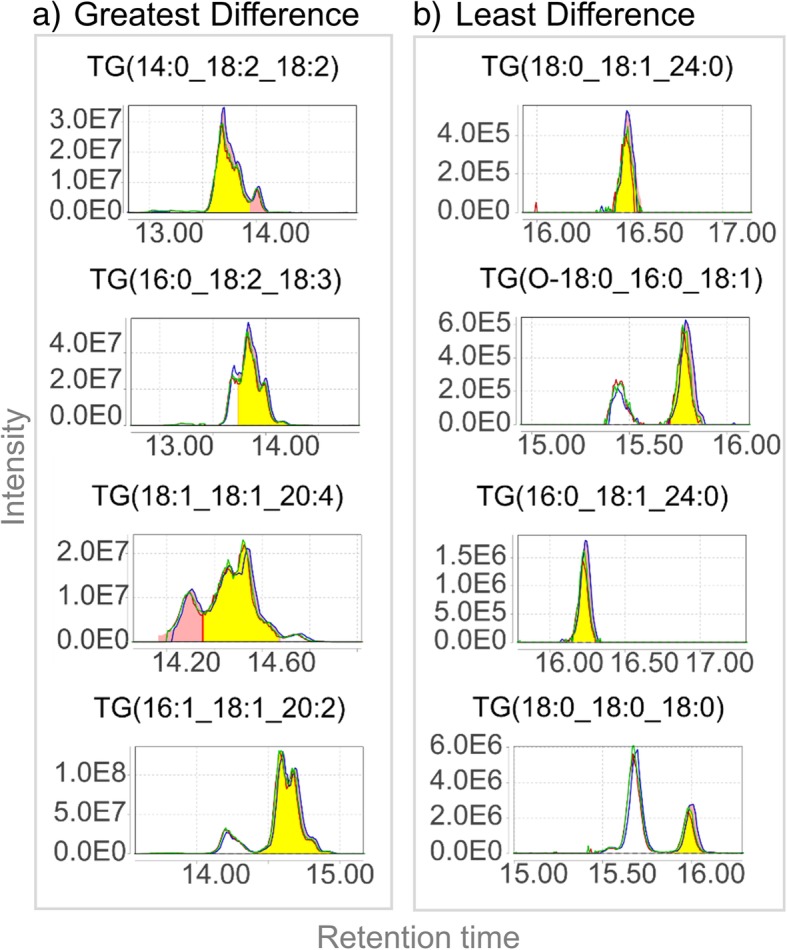
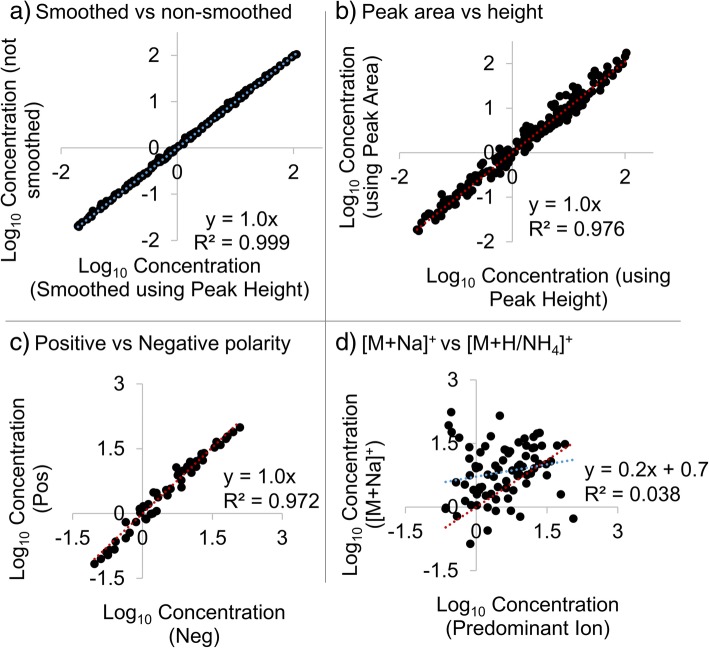
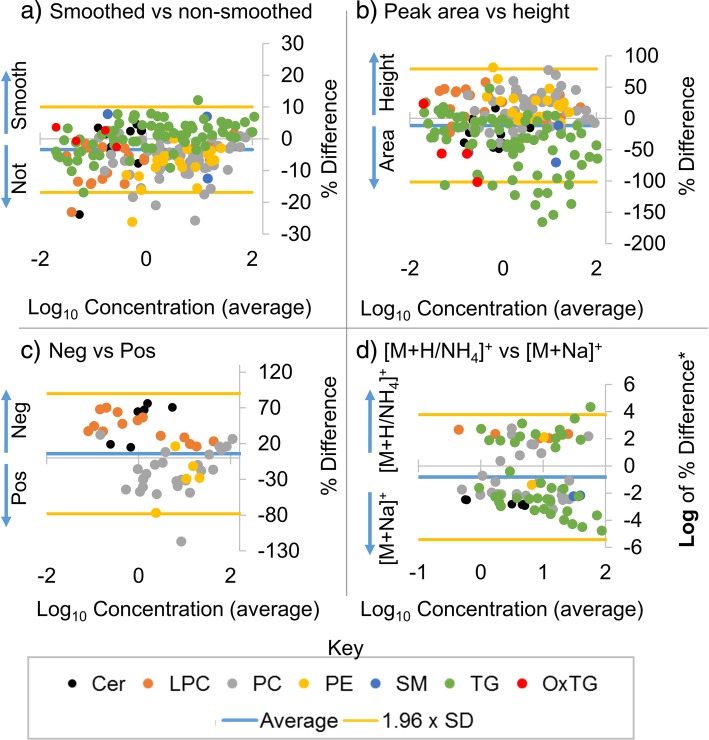
LMN can be integrated into an open source workflow which completes all data processing steps including feature finding, annotation, and quantification for LC-MS/MS studies. Using LMN we determined that in certain cases the use of peak height versus peak area, certain adducts, and negative versus positive polarity data can have major effects on the final concentration obtained.
脂质组学是对生物系统或基质内的脂质进行全面测量的新兴领域,具有显著提高临床诊断水平和增进对健康与疾病认识的潜力。脂质在生物中具有多种作用,这也使其具有临床应用价值,但脂质结构和浓度的多样性使得脂质组学的分析具有挑战性。由于没有与每种脂质相匹配的内标物,研究人员通常会将单个内标物应用于广泛的相关脂质。为了帮助标准化和自动化这个相对定量过程,我们开发了 LipidMatch Normalizer(LMN)http://secim.ufl.edu/secim-tools/,它可以在大多数开源脂质组学工作流程中使用。
LMN 使用排名系统(1-3)将脂质标准物分配给目标分析物。排名为 1 表示内标物和目标分析物的脂质类别和加合物都匹配,而排名为 3 表示既没有加合物也没有类别匹配。如果为一个脂质类别提供了多个内标物,则会选择与目标分析物最接近保留时间的内标物。用户还可以指定内标物代表的脂质类别,例如指示醚键连接的磷脂酰胆碱可以使用磷脂酰胆碱进行半定量。LMN 旨在与任何脂质鉴定软件和特征发现软件配合使用,在本研究中,它用于使用 LipidMatch 和 MZmine 对 NIST SRM 1950 人血浆进行注释并进行 LC-MS/MS 研究的定量。
LMN 可以集成到开源工作流程中,该流程完成所有数据处理步骤,包括特征发现、注释和 LC-MS/MS 研究的定量。使用 LMN,我们确定在某些情况下,使用峰高而不是峰面积、某些加合物以及正负极性数据可能会对最终获得的浓度产生重大影响。