Gritta Milan, Pilehvar Mohammad Taher, Limsopatham Nut, Collier Nigel
Language Technology Lab (LTL), Department of Theoretical and Applied Linguistics (DTAL), University of Cambridge, 9 West Road, Cambridge, CB3 9DP UK.
Lang Resour Eval. 2018;52(2):603-623. doi: 10.1007/s10579-017-9385-8. Epub 2017 Mar 7.
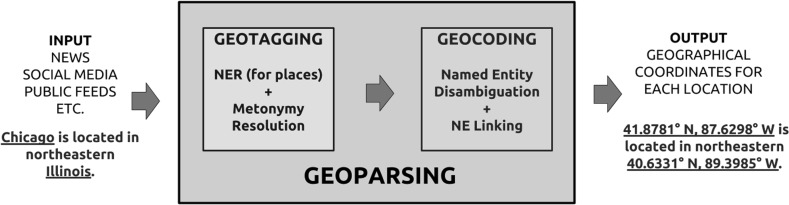
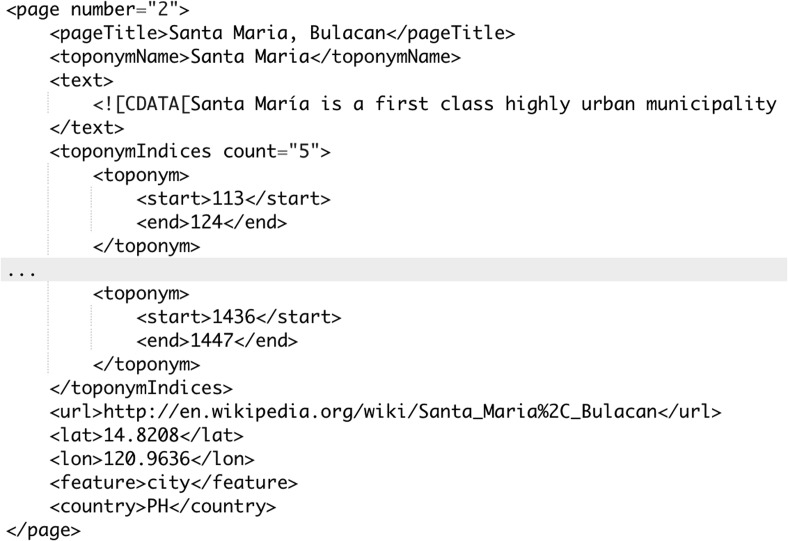
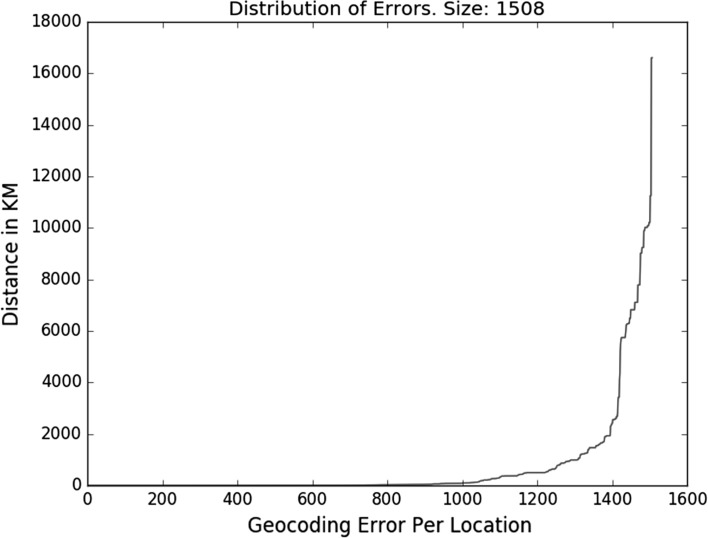
Geographical data can be obtained by converting place names from free-format text into geographical coordinates. The ability to geo-locate events in textual reports represents a valuable source of information in many real-world applications such as emergency responses, real-time social media geographical event analysis, understanding location instructions in auto-response systems and more. However, geoparsing is still widely regarded as a challenge because of domain language diversity, place name ambiguity, metonymic language and limited leveraging of context as we show in our analysis. Results to date, whilst promising, are on laboratory data and unlike in wider NLP are often not cross-compared. In this study, we evaluate and analyse the performance of a number of leading geoparsers on a number of corpora and highlight the challenges in detail. We also publish an automatically geotagged Wikipedia corpus to alleviate the dearth of (open source) corpora in this domain.
通过将自由格式文本中的地名转换为地理坐标,可以获取地理数据。在文本报告中对事件进行地理定位的能力在许多实际应用中都是宝贵的信息来源,如应急响应、实时社交媒体地理事件分析、理解自动回复系统中的位置指示等等。然而,正如我们在分析中所展示的,由于领域语言的多样性、地名的模糊性、转喻语言以及对上下文的利用有限,地理解析仍被广泛视为一项挑战。迄今为止的结果虽然很有前景,但都是基于实验室数据,而且与更广泛的自然语言处理不同,这些结果往往没有进行交叉比较。在本研究中,我们评估并分析了一些领先的地理解析器在多个语料库上的性能,并详细突出了其中的挑战。我们还发布了一个自动地理标记的维基百科语料库,以缓解该领域(开源)语料库的匮乏。