Wegrzyn Jill L, Staton Margaret A, Street Nathaniel R, Main Dorrie, Grau Emily, Herndon Nic, Buehler Sean, Falk Taylor, Zaman Sumaira, Ramnath Risharde, Richter Peter, Sun Lang, Condon Bradford, Almsaeed Abdullah, Chen Ming, Mannapperuma Chanaka, Jung Sook, Ficklin Stephen
Department of Ecology and Evolutionary Biology, University of Connecticut, Storrs, CT, United States.
Department of Entomology and Plant Pathology, University of Tennessee, Knoxville, Knoxville, TN, United States.
Front Plant Sci. 2019 Jun 25;10:813. doi: 10.3389/fpls.2019.00813. eCollection 2019.
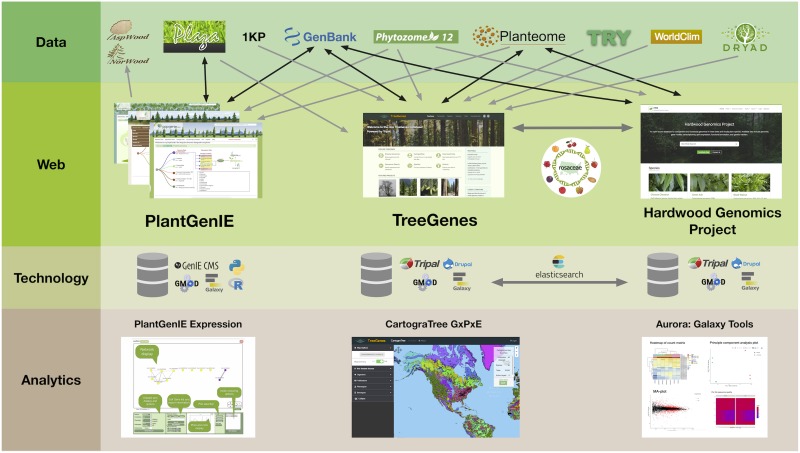
Despite tremendous advancements in high throughput sequencing, the vast majority of tree genomes, and in particular, forest trees, remain elusive. Although primary databases store genetic resources for just over 2,000 forest tree species, these are largely focused on sequence storage, basic genome assemblies, and functional assignment through existing pipelines. The tree databases reviewed here serve as secondary repositories for community data. They vary in their focal species, the data they curate, and the analytics provided, but they are united in moving toward a goal of centralizing both data access and analysis. They provide frameworks to view and update annotations for complex genomes, interrogate systems level expression profiles, curate data for comparative genomics, and perform real-time analysis with genotype and phenotype data. The organism databases of today are no longer simply catalogs or containers of genetic information. These repositories represent integrated cyberinfrastructure that support cross-site queries and analysis in web-based environments. These resources are striving to integrate across diverse experimental designs, sequence types, and related measures through ontologies, community standards, and web services. Efficient, simple, and robust platforms that enhance the data generated by the research community, contribute to improving forest health and productivity.
尽管高通量测序技术取得了巨大进展,但绝大多数树木基因组,尤其是森林树木的基因组,仍然难以捉摸。虽然主要数据库仅存储了2000多种森林树种的遗传资源,但这些资源主要集中于序列存储、基本基因组组装以及通过现有流程进行功能分配。这里所综述的树木数据库作为社区数据的二级存储库。它们在重点关注的物种、所管理的数据以及提供的分析方法上各有不同,但都朝着集中数据访问和分析这一目标发展。它们提供了框架,用于查看和更新复杂基因组的注释、探究系统水平的表达谱、整理比较基因组学数据以及利用基因型和表型数据进行实时分析。如今的生物数据库不再仅仅是遗传信息的目录或容器。这些存储库代表了集成的网络基础设施,支持在基于网络的环境中进行跨站点查询和分析。这些资源正努力通过本体论、社区标准和网络服务,整合各种不同的实验设计、序列类型及相关度量。高效、简单且强大的平台能够增强研究社区生成的数据,有助于改善森林健康状况和提高生产力。