Physical Sciences Division, University of Washington Bothell, Bothell, Washington, United States of America.
PLoS One. 2019 Jul 11;14(7):e0219774. doi: 10.1371/journal.pone.0219774. eCollection 2019.
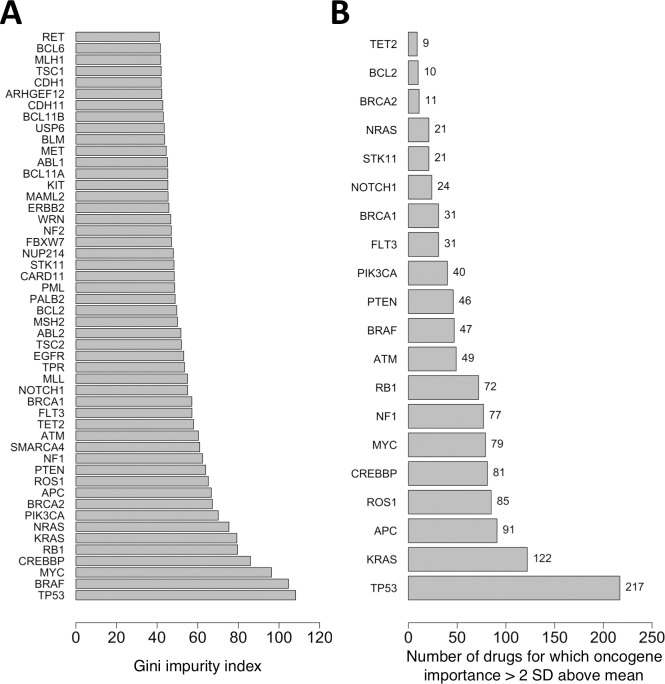
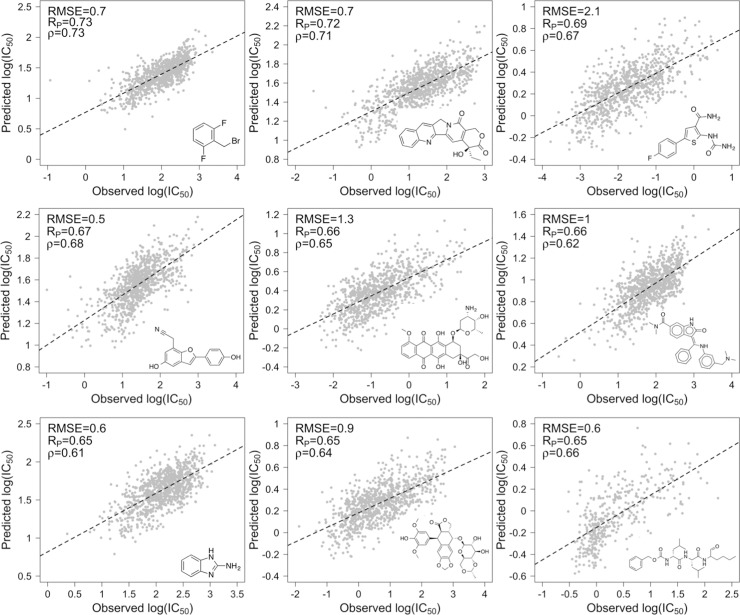
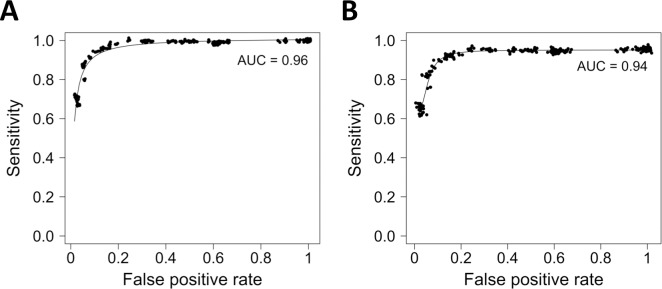
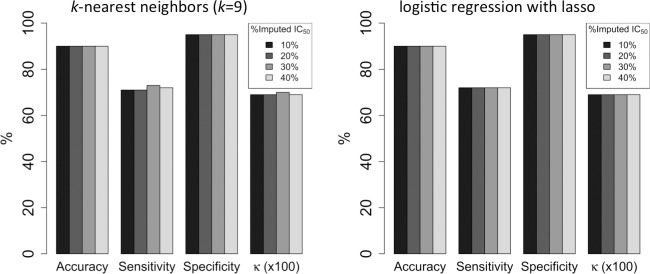
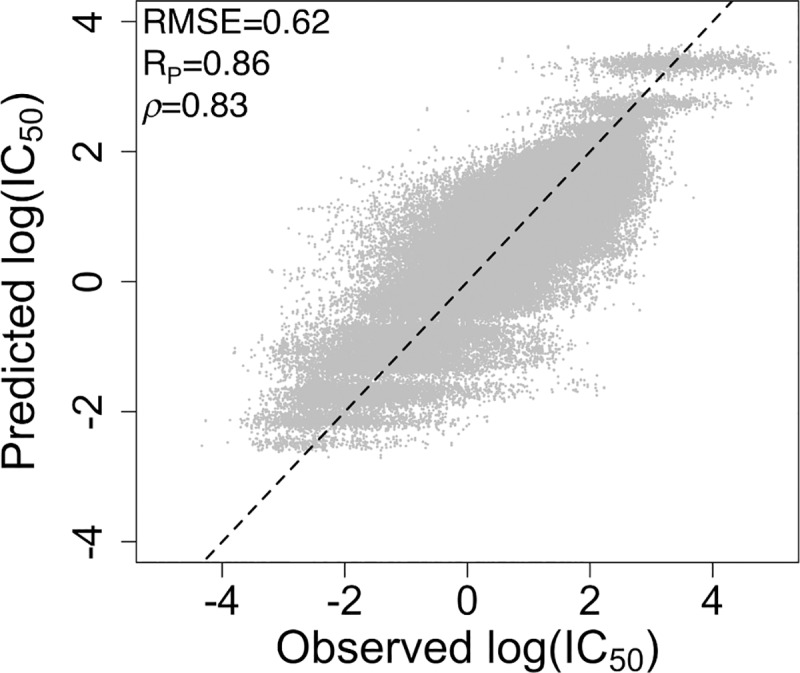
A key goal of precision medicine is predicting the best drug therapy for a specific patient from genomic information. In oncology, cancers that appear similar pathologically can vary greatly in how they respond to the same drug. Fortunately, data from high-throughput screening programs often reveal important relationships between genomic variability of cancer cells and their response to drugs. Nevertheless, many current computational methods to predict compound activity against cancer cells require large quantities of genomic, epigenomic, and additional cellular data to develop and to apply. Here we integrate recent screening data and machine learning to train classification models that predict the activity/inactivity of compounds against cancer cells based on the mutational status of only 145 oncogenes and a set of compound structural descriptors. Using IC50 values of 1 μM as activity cutoffs, our predictive models have sensitivities of 87%, specificities of 87%, and yield an area under the receiver operating characteristic curve equal to 0.94. We also develop regression models to predict log(IC50) values of compounds for cancer cells; the models achieve a Pearson correlation coefficient of 0.86 for cross-validation and up to 0.65-0.73 against blind test sets. Predictive performance remains strong when as few as 50 oncogenes are included. Finally, even when 40% of experimental IC50 values are missing from screening data, they can be imputed with sufficient reliability that classification accuracy is not diminished. The presented models are fast to generate and may serve as easily implemented screening tools for personalized oncology medicine, drug repurposing, and drug discovery.
精准医学的一个主要目标是根据基因组信息预测特定患者的最佳药物治疗方案。在肿瘤学中,病理上表现相似的癌症在对同一药物的反应上可能存在很大差异。幸运的是,高通量筛选计划的数据通常揭示了癌细胞的基因组变异与其对药物的反应之间的重要关系。然而,许多当前用于预测化合物对癌细胞活性的计算方法需要大量的基因组、表观基因组和其他细胞数据来开发和应用。在这里,我们整合了最近的筛选数据和机器学习来训练分类模型,这些模型仅基于 145 个癌基因的突变状态和一组化合物结构描述符来预测化合物对癌细胞的活性/非活性。使用 1 μM 的 IC50 值作为活性截止值,我们的预测模型具有 87%的灵敏度、87%的特异性和 0.94 的接收器工作特征曲线下面积。我们还开发了用于预测化合物对癌细胞的 log(IC50)值的回归模型;这些模型在交叉验证中达到了 0.86 的皮尔逊相关系数,在盲测试集上达到了 0.65-0.73。当包含的癌基因数量少至 50 个时,预测性能仍然很强。最后,即使筛选数据中缺失了 40%的实验 IC50 值,也可以通过足够的可靠性进行推断,而不会降低分类准确性。所提出的模型生成速度快,可作为个性化肿瘤学、药物再利用和药物发现的易于实现的筛选工具。