Department of Computer Science and Engineering, the Chinese University of Hong Kong, Sha Tin, N.T., Hong Kong, China.
SDIVF R&D Centre, Hong Kong Science Park, Sha Tin, N.T., Hong Kong, China.
BMC Bioinformatics. 2019 Jul 29;20(1):408. doi: 10.1186/s12859-019-2910-6.
Understanding the phenotypic drug response on cancer cell lines plays a vital role in anti-cancer drug discovery and re-purposing. The Genomics of Drug Sensitivity in Cancer (GDSC) database provides open data for researchers in phenotypic screening to build and test their models. Previously, most research in these areas starts from the molecular fingerprints or physiochemical features of drugs, instead of their structures.
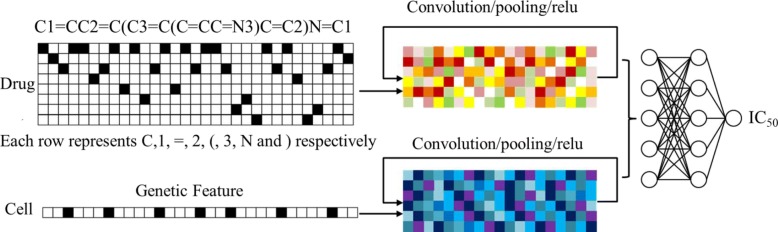
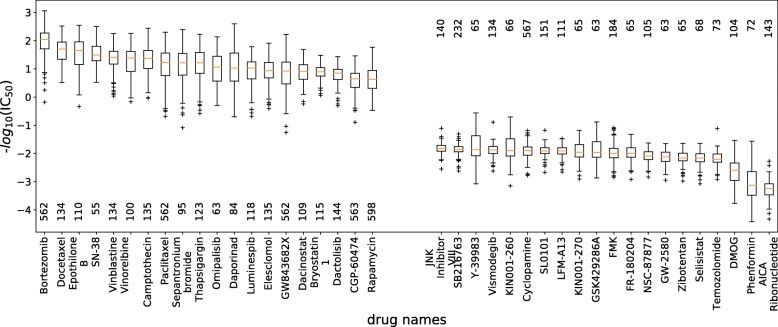
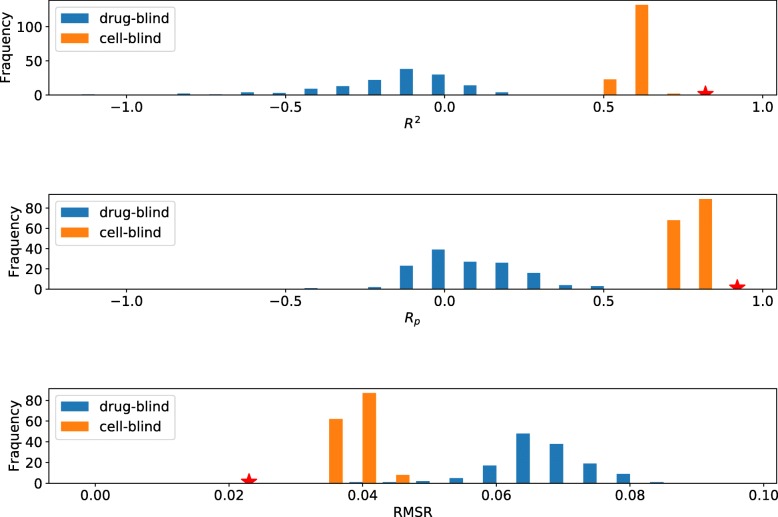
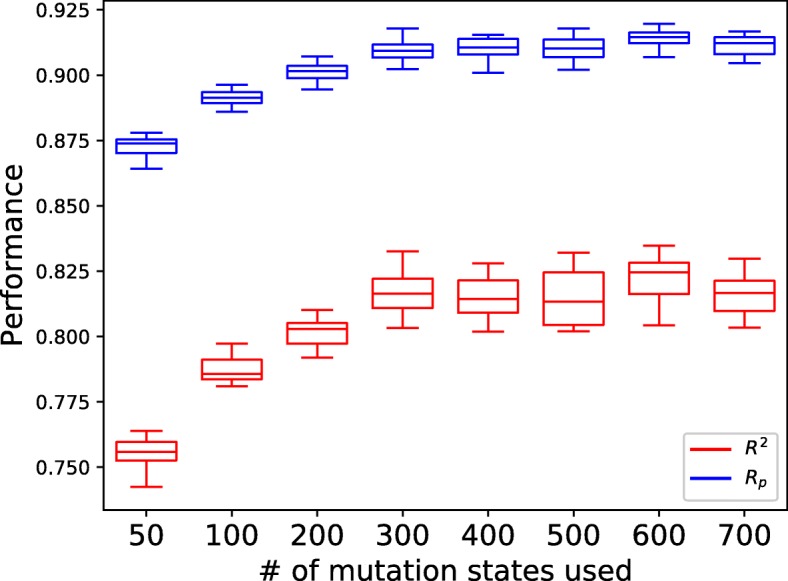
In this paper, a model called twin Convolutional Neural Network for drugs in SMILES format (tCNNS) is introduced for phenotypic screening. tCNNS uses a convolutional network to extract features for drugs from their simplified molecular input line entry specification (SMILES) format and uses another convolutional network to extract features for cancer cell lines from the genetic feature vectors respectively. After that, a fully connected network is used to predict the interaction between the drugs and the cancer cell lines. When the training set and the testing set are divided based on the interaction pairs between drugs and cell lines, tCNNS achieves 0.826, 0.831 for the mean and top quartile of the coefficient of determinant (R) respectively and 0.909, 0.912 for the mean and top quartile of the Pearson correlation (R) respectively, which are significantly better than those of the previous works (Ammad-Ud-Din et al., J Chem Inf Model 54:2347-9, 2014), (Haider et al., PLoS ONE 10:0144490, 2015), (Menden et al., PLoS ONE 8:61318, 2013). However, when the training set and the testing set are divided exclusively based on drugs or cell lines, the performance of tCNNS decreases significantly and R and R drop to barely above 0.
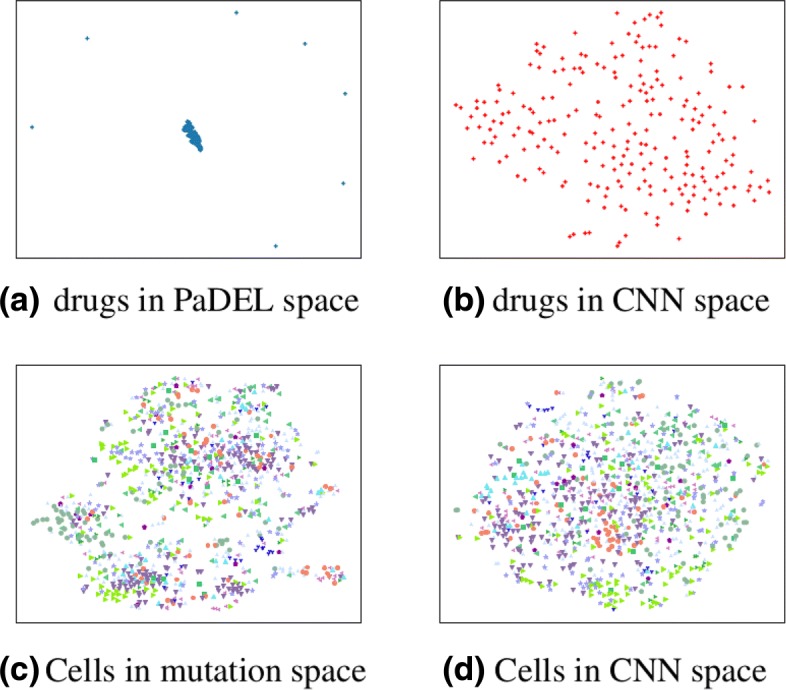
Our approach is able to predict the drug effects on cancer cell lines with high accuracy, and its performance remains stable with less but high-quality data, and with fewer features for the cancer cell lines. tCNNS can also solve the problem of outliers in other feature space. Besides achieving high scores in these statistical metrics, tCNNS also provides some insights into the phenotypic screening. However, the performance of tCNNS drops in the blind test.
了解癌细胞系的表型药物反应在抗癌药物发现和再利用中起着至关重要的作用。癌症药物敏感性基因组学(GDSC)数据库为表型筛选的研究人员提供了开放数据,以构建和测试他们的模型。以前,这些领域的大多数研究都是从药物的分子指纹或物理化学特征开始,而不是从它们的结构开始。
本文介绍了一种用于表型筛选的 SMILES 格式药物双卷积神经网络模型(tCNNS)。tCNNS 使用卷积网络从简化分子输入线条目规范(SMILES)格式中为药物提取特征,并使用另一个卷积网络从遗传特征向量中为癌细胞系提取特征。之后,使用全连接网络来预测药物与癌细胞系之间的相互作用。当根据药物和细胞系之间的相互作用对训练集和测试集进行划分时,tCNNS 分别在决定系数(R)的平均值和四分位距上达到 0.826、0.831,在皮尔逊相关系数(R)的平均值和四分位距上达到 0.909、0.912,显著优于之前的工作(Ammad-Ud-Din 等人,J Chem Inf Model 54:2347-9, 2014),(Haider 等人,PLoS ONE 10:0144490, 2015),(Menden 等人,PLoS ONE 8:61318, 2013)。然而,当仅根据药物或细胞系对训练集和测试集进行划分时,tCNNS 的性能会显著下降,R 和 R 降至略高于 0.
我们的方法能够以高精度预测癌细胞系的药物作用,并且在数据较少但质量较高、癌细胞系特征较少的情况下,性能仍然稳定。tCNNS 还可以解决其他特征空间中的异常值问题。除了在这些统计指标中取得高分外,tCNNS 还为表型筛选提供了一些见解。然而,tCNNS 在盲测中的性能有所下降。