Kim Mina, Shin Soo-Yong, Kang Mira, Yi Byoung-Kee, Chang Dong Kyung
Department of Digital Health, Samsung Advanced Institute for Health Sciences & Technology, Sungkyunkwan University, Seoul, Republic of Korea.
Health Information and Strategy Center, Samsung Medical Center, Seoul, Republic of Korea.
JMIR Med Inform. 2019 Aug 29;7(3):e14083. doi: 10.2196/14083.
Data standardization is essential in electronic health records (EHRs) for both clinical practice and retrospective research. However, it is still not easy to standardize EHR data because of nonidentical duplicates, typographical errors, or inconsistencies. To overcome this drawback, standardization efforts have been undertaken for collecting data in a standardized format as well as for curating the stored data in EHRs. To perform clinical big data research, the stored data in EHR should be standardized, starting from laboratory results, given their importance. However, most of the previous efforts have been based on labor-intensive manual methods.
We aimed to develop an automatic standardization method for eliminating the noises of categorical laboratory data, grouping, and mapping of cleaned data using standard terminology.
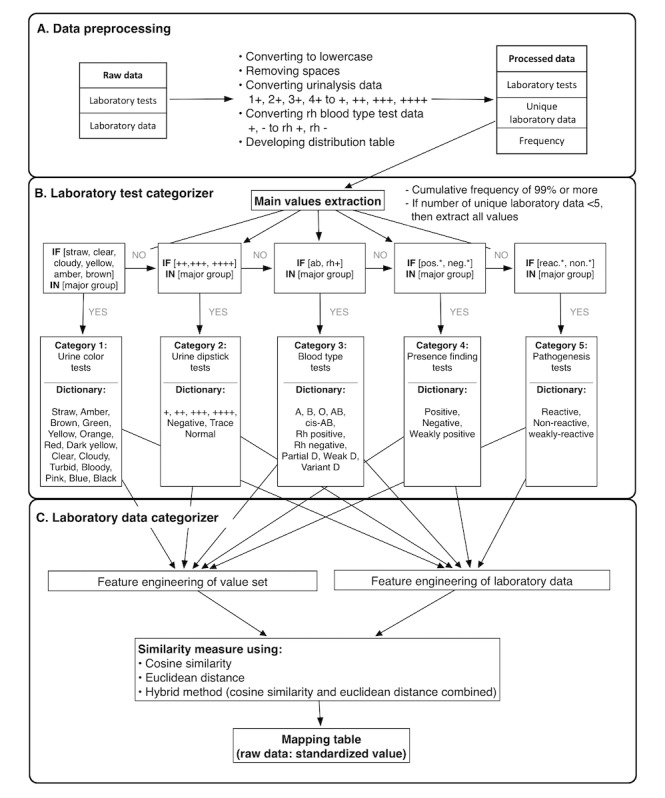
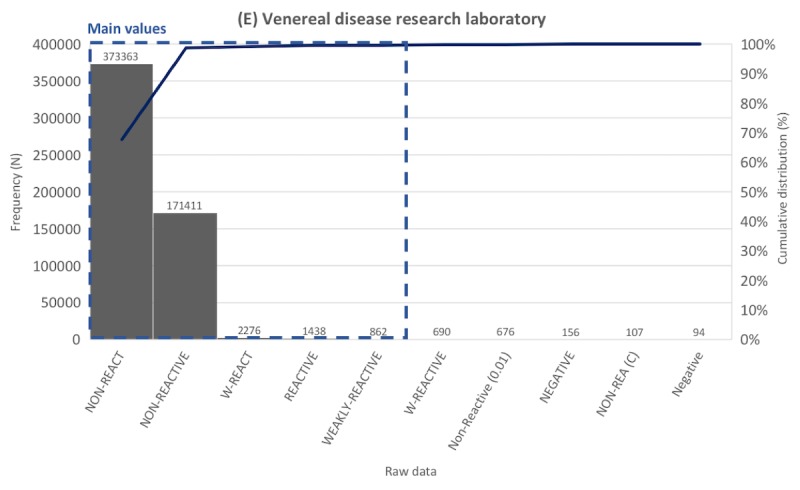
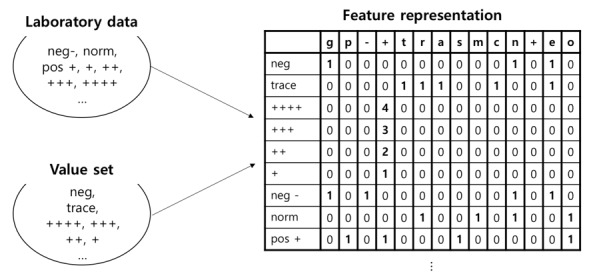
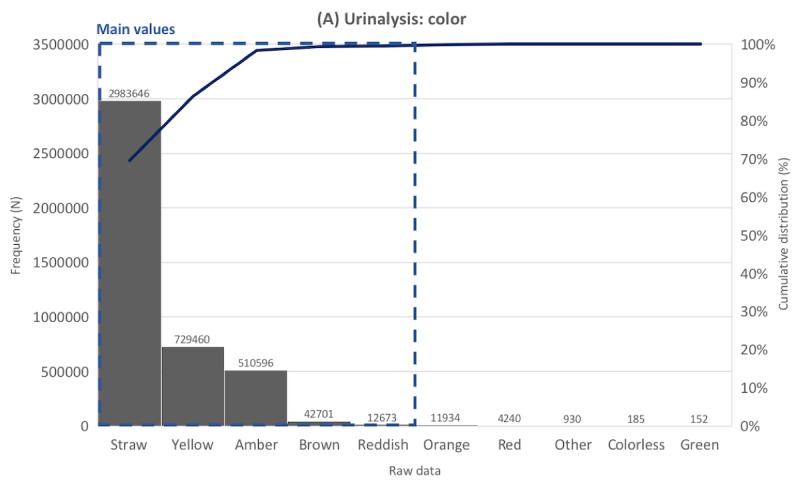
We developed a method called standardization algorithm for laboratory test-categorical result (SALT-C) that can process categorical laboratory data, such as pos +, 250 4+ (urinalysis results), and reddish (urinalysis color results). SALT-C consists of five steps. First, it applies data cleaning rules to categorical laboratory data. Second, it categorizes the cleaned data into 5 predefined groups (urine color, urine dipstick, blood type, presence-finding, and pathogenesis tests). Third, all data in each group are vectorized. Fourth, similarity is calculated between the vectors of data and those of each value in the predefined value sets. Finally, the value closest to the data is assigned.
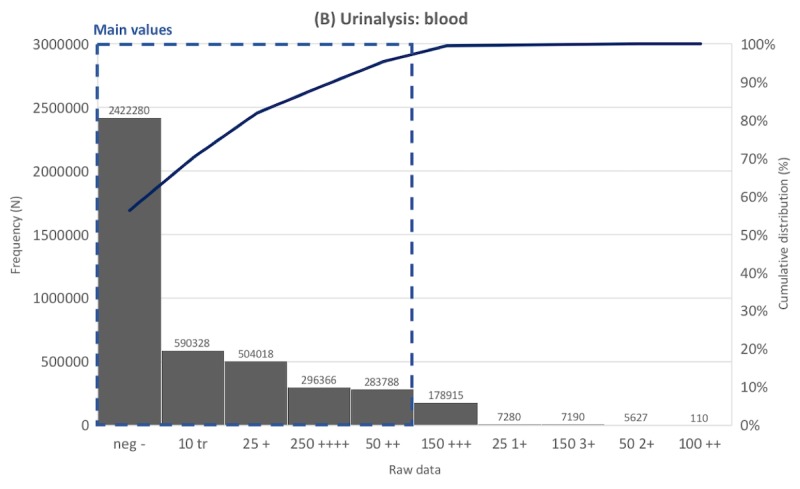
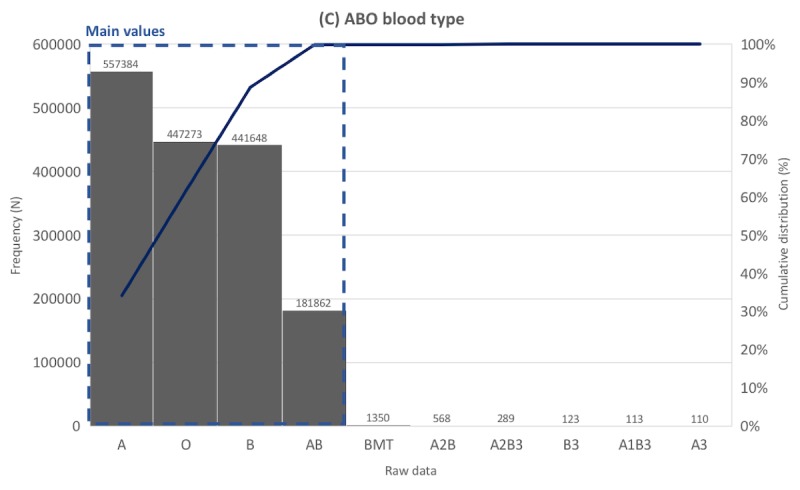
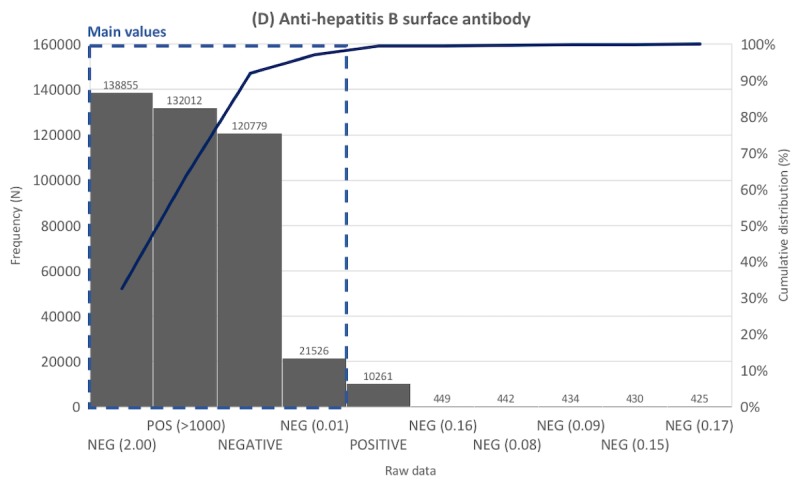
The performance of SALT-C was validated using 59,213,696 data points (167,938 unique values) generated over 23 years from a tertiary hospital. Apart from the data whose original meaning could not be interpreted correctly (eg, ** and _^), SALT-C mapped unique raw data to the correct reference value for each group with accuracy of 97.6% (123/126; urine color tests), 97.5% (198/203; (urine dipstick tests), 95% (53/56; blood type tests), 99.68% (162,291/162,805; presence-finding tests), and 99.61% (4643/4661; pathogenesis tests).
The proposed SALT-C successfully standardized the categorical laboratory test results with high reliability. SALT-C can be beneficial for clinical big data research by reducing laborious manual standardization efforts.
数据标准化在电子健康记录(EHR)中对于临床实践和回顾性研究都至关重要。然而,由于存在非完全相同的重复数据、排版错误或不一致性,对EHR数据进行标准化仍然并非易事。为克服这一缺点,已经开展了标准化工作,以标准化格式收集数据,并对EHR中存储的数据进行整理。为了进行临床大数据研究,鉴于实验室检查结果的重要性,EHR中存储的数据应从实验室检查结果开始进行标准化。然而,之前的大多数工作都是基于劳动密集型的手工方法。
我们旨在开发一种自动标准化方法,以消除分类实验室数据中的噪声,使用标准术语对清理后的数据进行分组和映射。
我们开发了一种称为实验室检查分类结果标准化算法(SALT-C)的方法,该方法可以处理分类实验室数据,如阳性+、250 4+(尿液分析结果)和微红(尿液颜色结果)。SALT-C由五个步骤组成。首先,它将数据清理规则应用于分类实验室数据。其次,它将清理后的数据分类为5个预定义组(尿液颜色、尿液试纸、血型、发现结果和发病机制检查)。第三,对每个组中的所有数据进行向量化。第四,计算数据向量与预定义值集中每个值的向量之间的相似度。最后,为数据分配最接近的值。
使用一家三级医院23年来生成的59,213,696个数据点(167,938个唯一值)对SALT-C的性能进行了验证。除了那些原始含义无法正确解释的数据(如**和_^)外,SALT-C将唯一的原始数据准确映射到每个组的正确参考值,尿液颜色检查的准确率为97.6%(123/126),尿液试纸检查为97.5%(198/203),血型检查为95%(53/56),发现结果检查为99.68%(162,291/162,805),发病机制检查为99.61%(4643/4661)。
所提出的SALT-C成功地以高可靠性对分类实验室检查结果进行了标准化。SALT-C通过减少费力的手工标准化工作,可能对临床大数据研究有益。