Ortell Katherine K, Switonski Pawel M, Delaney Joe Ryan
Department of Biochemistry and Molecular Biology, Medical University of South Carolina, Charleston, SC 29425, USA.
Departments of Neurology, Duke University School of Medicine, Durham, NC 27710, USA.
J Biol Methods. 2019 Sep 3;6(3):e118. doi: 10.14440/jbm.2019.299. eCollection 2019.
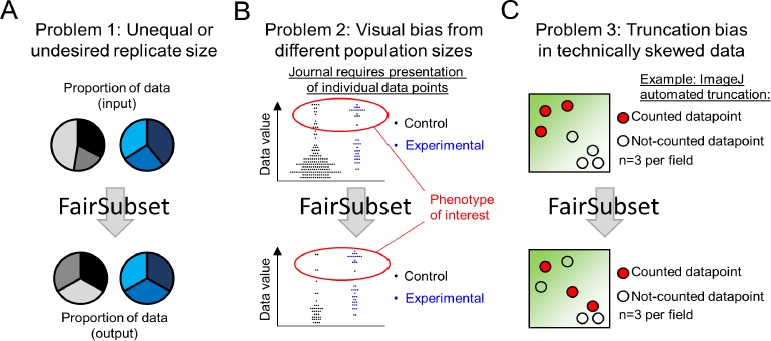
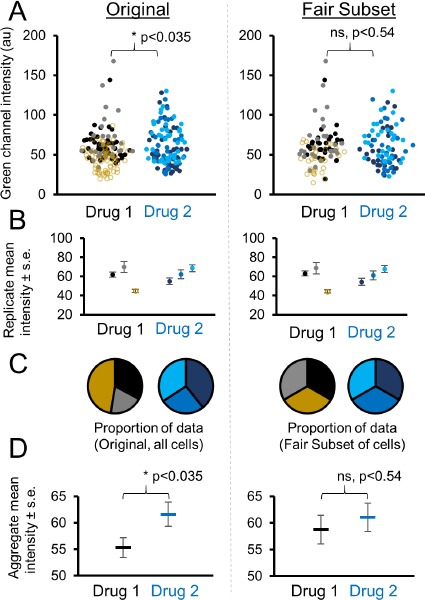
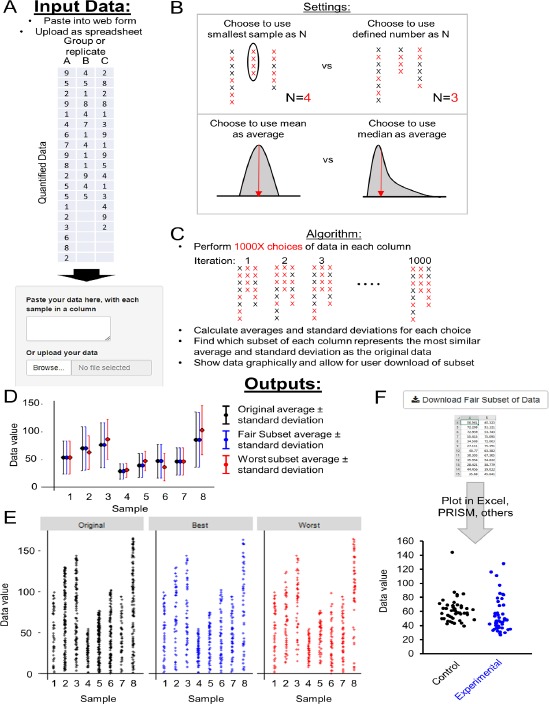
High-impact journals are promoting transparency of data. Modern scientific methods can be automated and produce disparate samples sizes. In many cases, it is desirable to retain identical or pre-defined sample sizes between replicates or groups. However, choosing which subset of originally acquired data that best matches the entirety of the data set without introducing bias is not trivial. Here, we released a free online tool, FairSubset, and its constituent Shiny App R code to subset data in an unbiased fashion. Subsets were set at the same N across samples and retained representative average and standard deviation information. The method can be used for quantitation of entire fields of view or other replicates without biasing the data pool toward large N samples. We showed examples of the tool's use with fluorescence data and DNA-damage related Comet tail quantitation. This FairSubset tool and the method to retain distribution information at the single-datum level may be considered for standardized use in fair publishing practices.
高影响力期刊正在推动数据的透明度。现代科学方法可以自动化并产生不同的样本量。在许多情况下,希望在重复实验或组之间保持相同或预先定义的样本量。然而,在不引入偏差的情况下选择最初获取的数据中最能匹配整个数据集的子集并非易事。在这里,我们发布了一个免费的在线工具FairSubset及其组成的Shiny App R代码,以无偏差的方式对数据进行子集化。子集在不同样本间设置为相同的N,并保留代表性的平均值和标准差信息。该方法可用于定量整个视野或其他重复实验,而不会使数据池偏向大N样本。我们展示了该工具用于荧光数据和DNA损伤相关彗星尾定量的示例。这种FairSubset工具以及在单数据水平保留分布信息的方法可考虑用于公平出版实践中的标准化使用。