Department of Psychology, University of Arizona, Tucson, AZ, USA.
Cognitive Science Program, University of Arizona, Tucson, AZ, USA.
Nat Commun. 2019 Nov 5;10(1):4646. doi: 10.1038/s41467-019-12552-4.
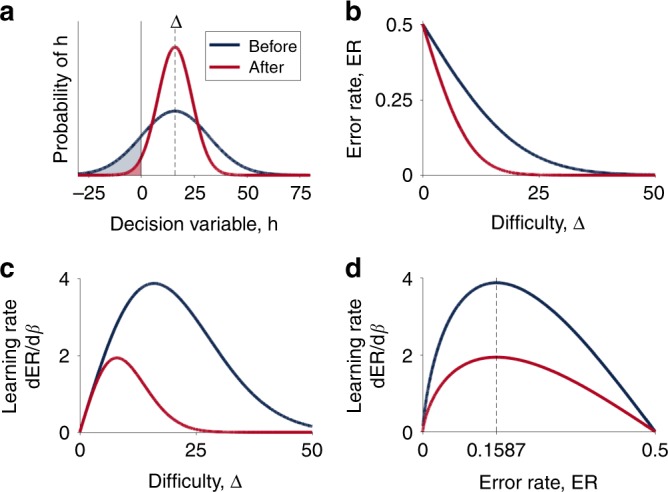
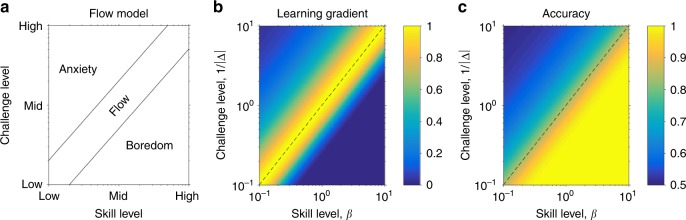
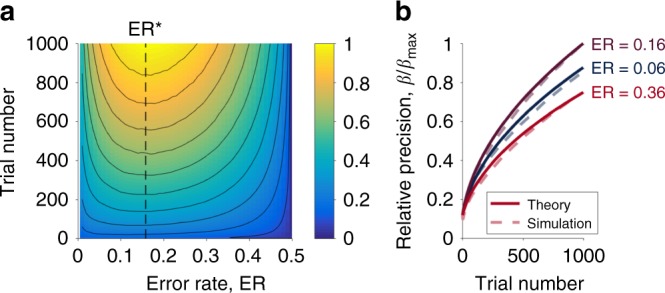
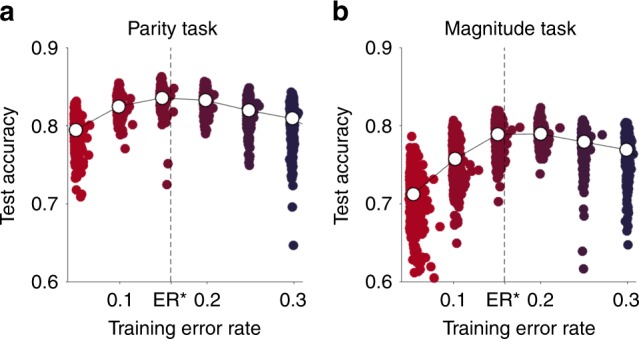
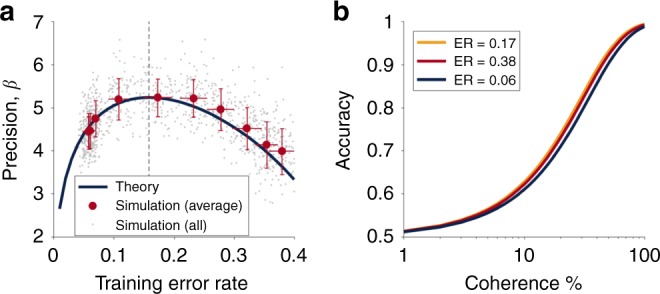
Researchers and educators have long wrestled with the question of how best to teach their clients be they humans, non-human animals or machines. Here, we examine the role of a single variable, the difficulty of training, on the rate of learning. In many situations we find that there is a sweet spot in which training is neither too easy nor too hard, and where learning progresses most quickly. We derive conditions for this sweet spot for a broad class of learning algorithms in the context of binary classification tasks. For all of these stochastic gradient-descent based learning algorithms, we find that the optimal error rate for training is around 15.87% or, conversely, that the optimal training accuracy is about 85%. We demonstrate the efficacy of this 'Eighty Five Percent Rule' for artificial neural networks used in AI and biologically plausible neural networks thought to describe animal learning.
研究人员和教育工作者长期以来一直在探讨如何最好地教授他们的客户——无论是人类、非人类动物还是机器。在这里,我们研究了一个单一变量,即训练的难度,对学习速度的影响。在许多情况下,我们发现存在一个最佳点,在这个点上,训练既不太容易也不太难,并且学习进展最快。我们为一类广泛的学习算法在二进制分类任务的背景下推导出了这个最佳点的条件。对于所有这些基于随机梯度下降的学习算法,我们发现训练的最佳误差率约为 15.87%,或者换句话说,最佳训练精度约为 85%。我们展示了这个“百分之八十五规则”对于人工智能中使用的人工神经网络和被认为描述动物学习的生物上合理的神经网络的有效性。