Pruksawan Sirawit, Lambard Guillaume, Samitsu Sadaki, Sodeyama Keitaro, Naito Masanobu
Data-driven Polymer Design Group, Research and Services Division of Materials Data and Integrated System (MaDIS), National Institute for Materials Science (NIMS), Tsukuba, Japan.
Program in Materials Science and Engineering, Graduate School of Pure and Applied Sciences, University of Tsukuba, Tsukuba, Japan.
Sci Technol Adv Mater. 2019 Oct 2;20(1):1010-1021. doi: 10.1080/14686996.2019.1673670. eCollection 2019.
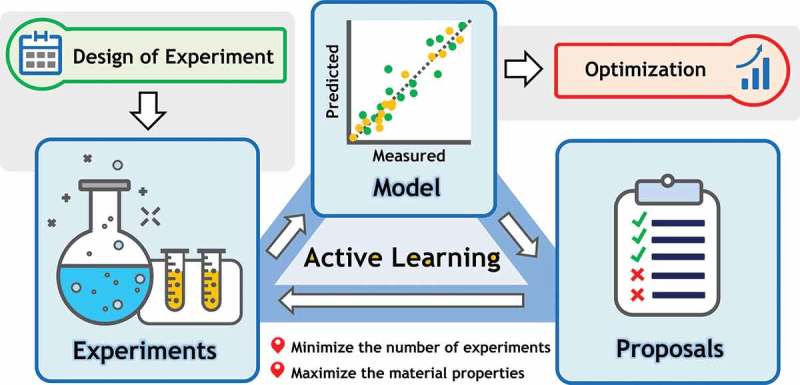
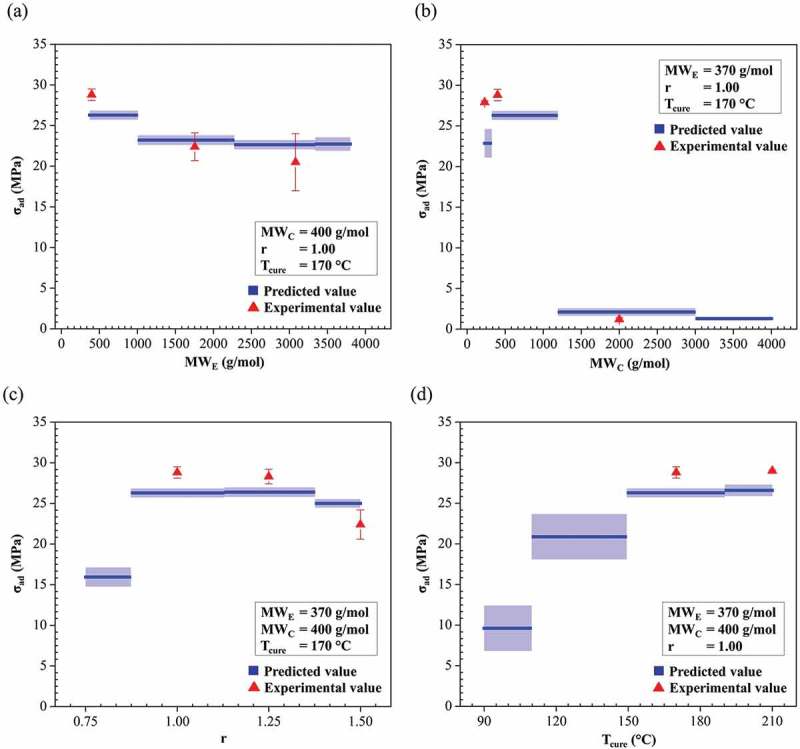
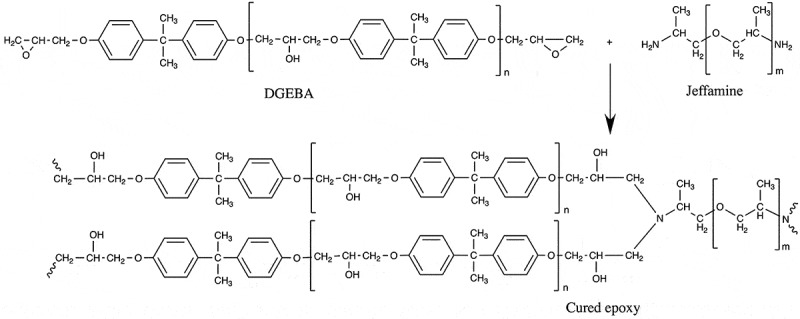
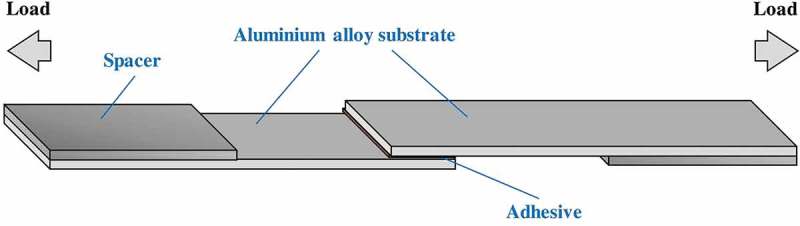
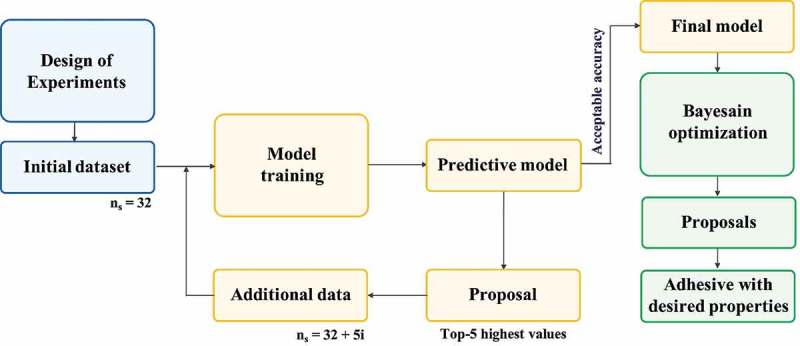
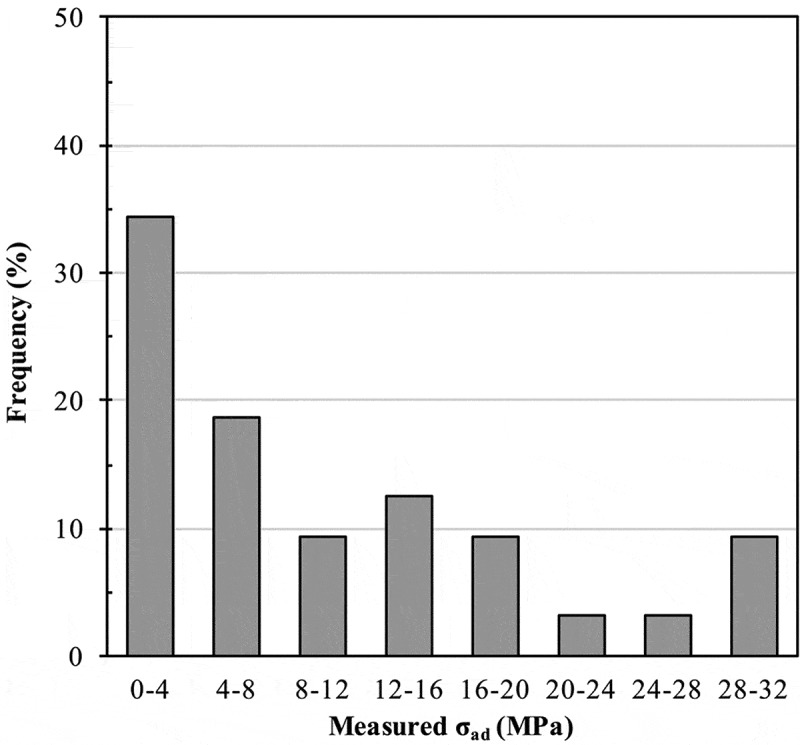
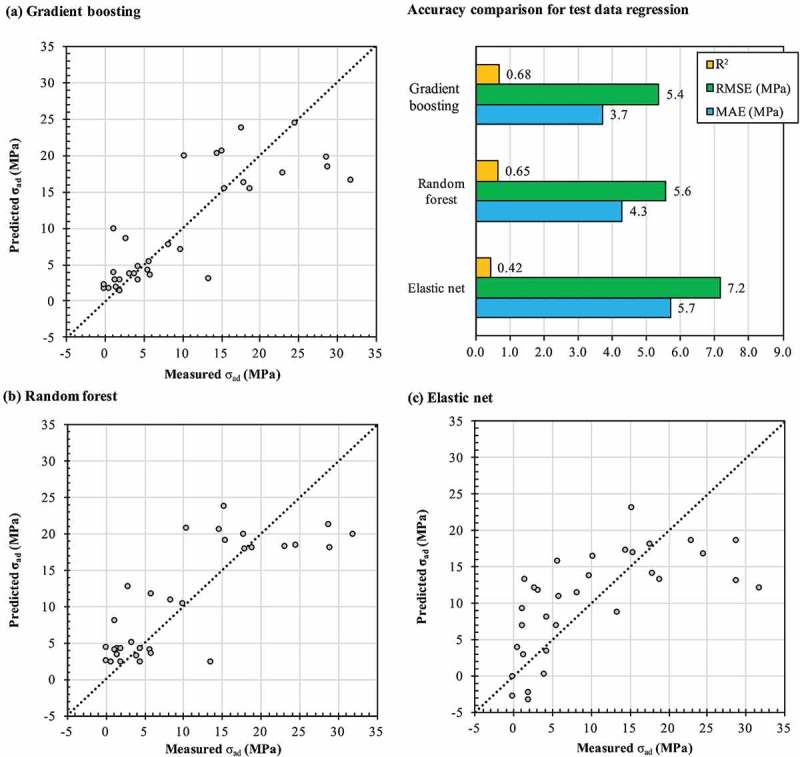
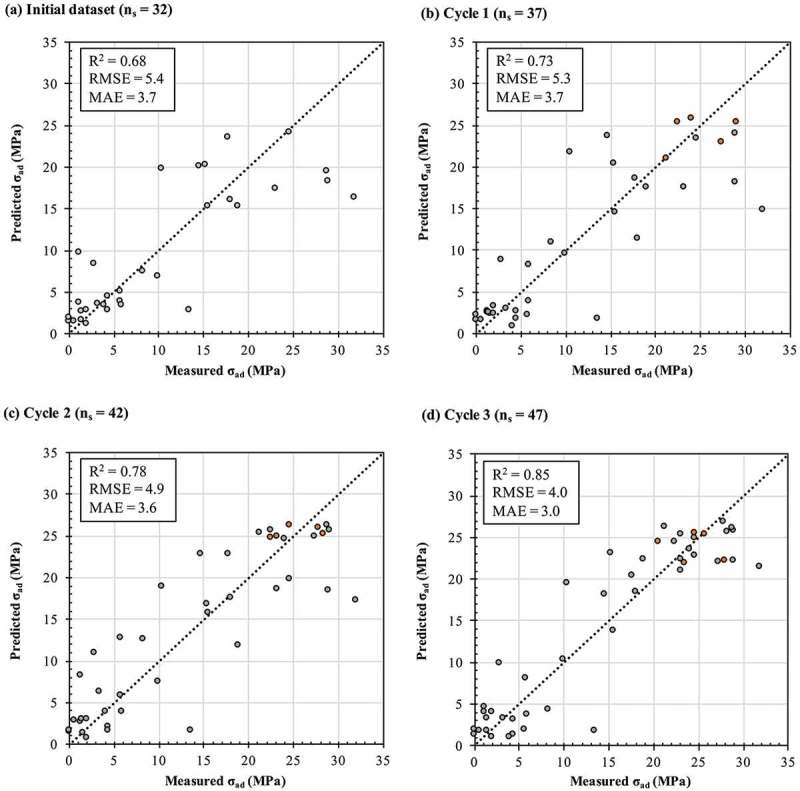
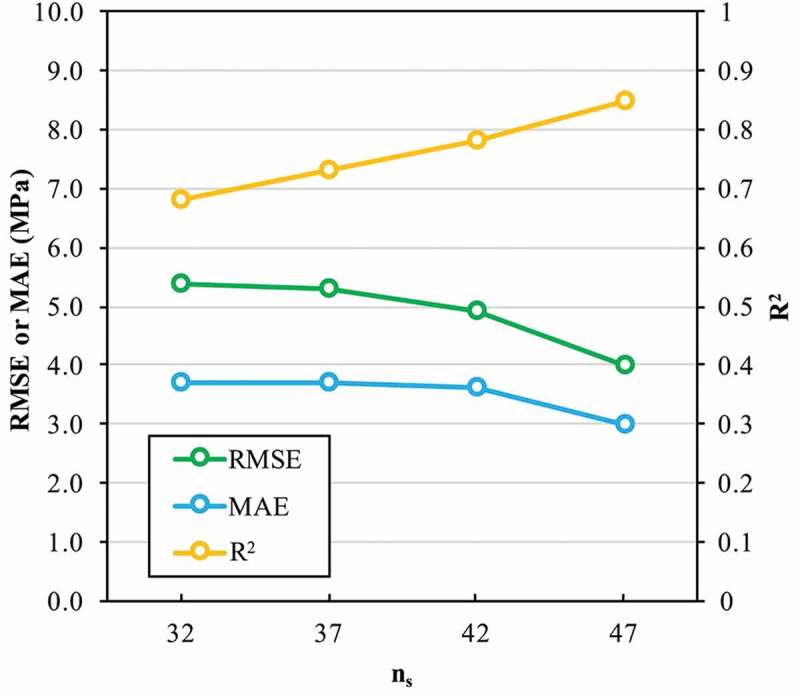
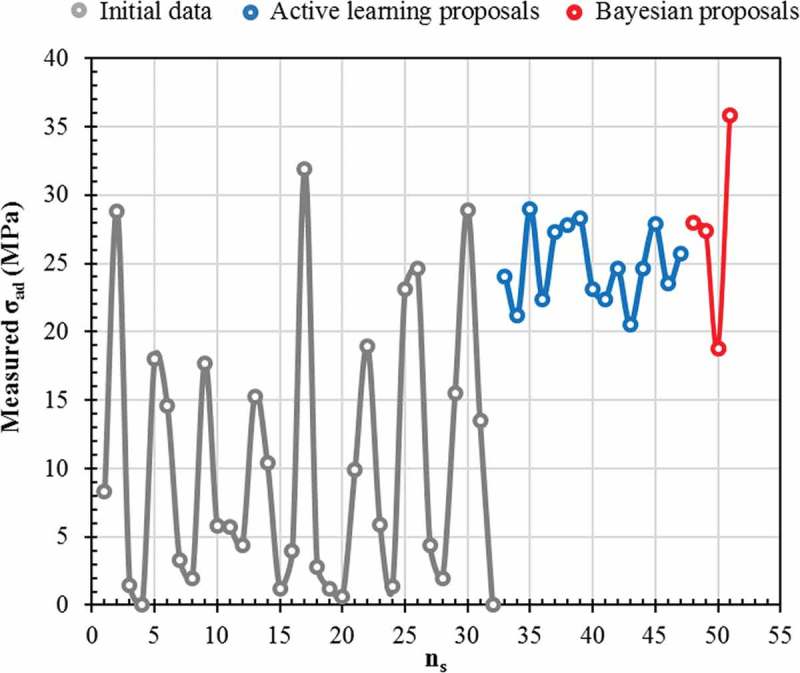
Machine learning is emerging as a powerful tool for the discovery of novel high-performance functional materials. However, experimental datasets in the polymer-science field are typically limited and they are expensive to build. Their size (< 100 samples) limits the development of chemical intuition from experimentalists, as it constrains the use of machine-learning algorithms for extracting relevant information. We tackle this issue to predict and optimize adhesive materials by combining laboratory experimental design, an active learning pipeline and Bayesian optimization. We start from an initial dataset of 32 adhesive samples that were prepared from various molecular-weight bisphenol A-based epoxy resins and polyetheramine curing agents, mixing ratios and curing temperatures, and our data-driven method allows us to propose an optimal preparation of an adhesive material with a very high adhesive joint strength measured at 35.8 ± 1.1 MPa after three active learning cycles (five proposed preparations per cycle). A Gradient boosting machine learning model was used for the successive prediction of the adhesive joint strength in the active learning pipeline, and the model achieved a respectable accuracy with a coefficient of determination, root mean square error and mean absolute error of 0.85, 4.0 MPa and 3.0 MPa, respectively. This study demonstrates the important impact of active learning to accelerate the design and development of tailored highly functional materials from very small datasets.
机器学习正成为发现新型高性能功能材料的强大工具。然而,聚合物科学领域的实验数据集通常有限,而且构建成本高昂。其规模(<100个样本)限制了实验人员化学直觉的发展,因为这限制了使用机器学习算法来提取相关信息。我们通过结合实验室实验设计、主动学习流程和贝叶斯优化来解决这个问题,以预测和优化粘合剂材料。我们从由各种分子量的双酚A基环氧树脂和聚醚胺固化剂、混合比例和固化温度制备的32个粘合剂样本的初始数据集开始,我们的数据驱动方法使我们能够在三个主动学习周期(每个周期提出五种制备方法)后,提出一种具有非常高的粘合强度的粘合剂材料的最佳制备方法,在35.8±1.1MPa下测量。在主动学习流程中,使用梯度提升机器学习模型对粘合强度进行连续预测,该模型取得了可观的准确率,决定系数、均方根误差和平均绝对误差分别为0.85、4.0MPa和3.0MPa。这项研究证明了主动学习对从非常小的数据集中加速定制的高功能材料的设计和开发的重要影响。