Bewicke-Copley Findlay, Arjun Kumar Emil, Palladino Giuseppe, Korfi Koorosh, Wang Jun
Centre for Cancer Genomics and Computational Biology, Barts Cancer Institute, Queen Mary University of London, Charterhouse Square, London EC1M 6BQ, UK.
Centre for Haemato-Oncology, Barts Cancer Institute, Queen Mary University of London, Charterhouse Square, London EC1M 6BQ, UK.
Comput Struct Biotechnol J. 2019 Nov 7;17:1348-1359. doi: 10.1016/j.csbj.2019.10.004. eCollection 2019.
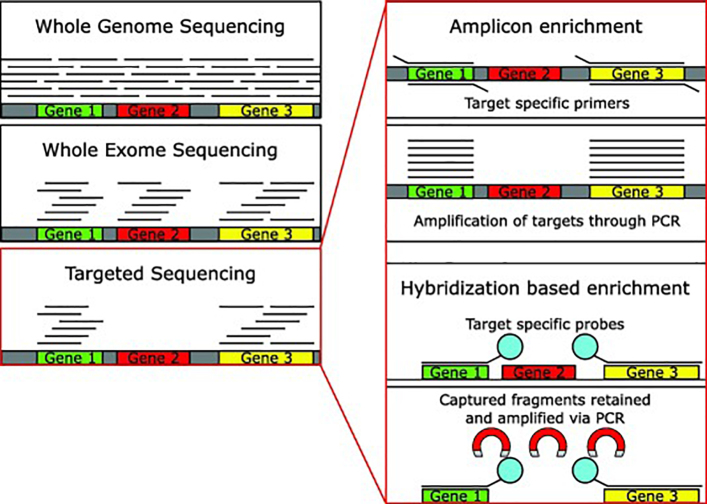
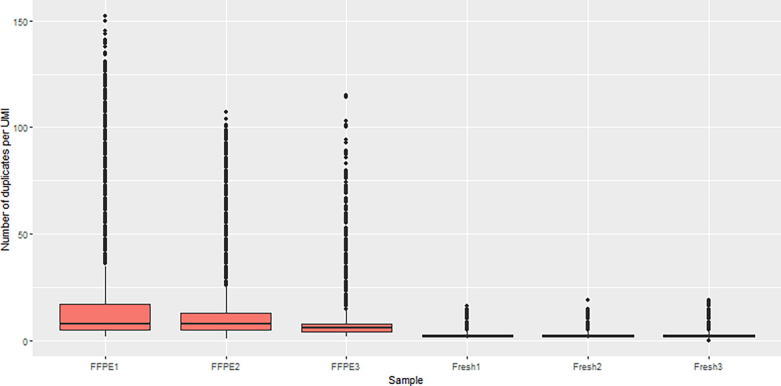
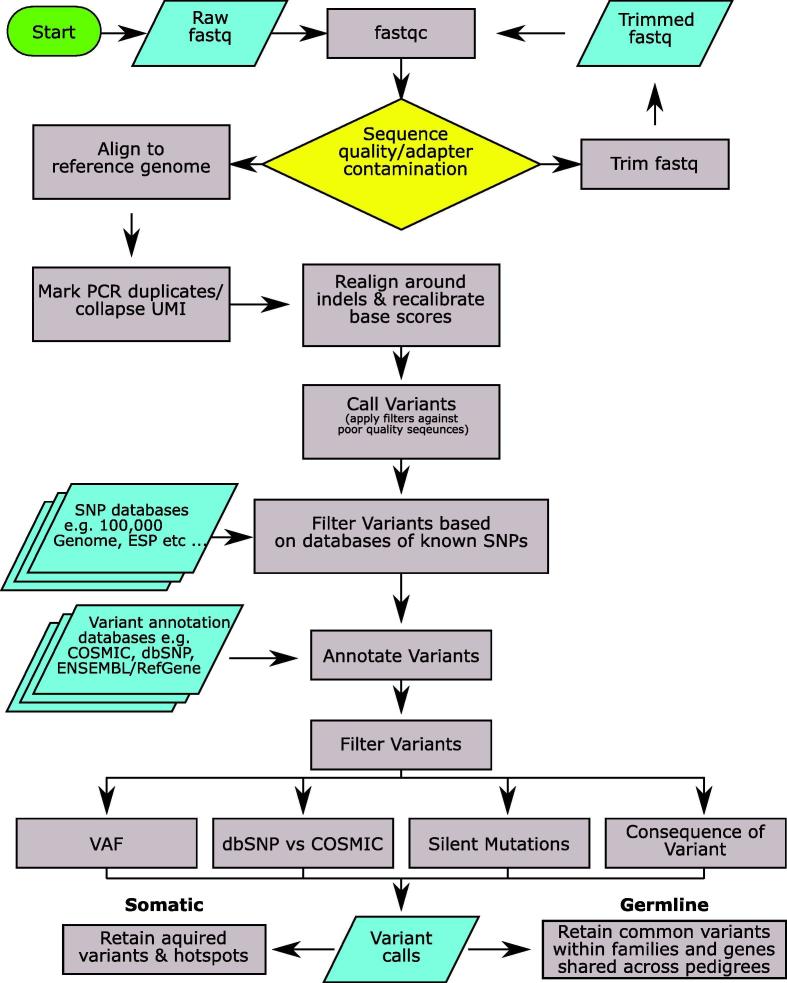
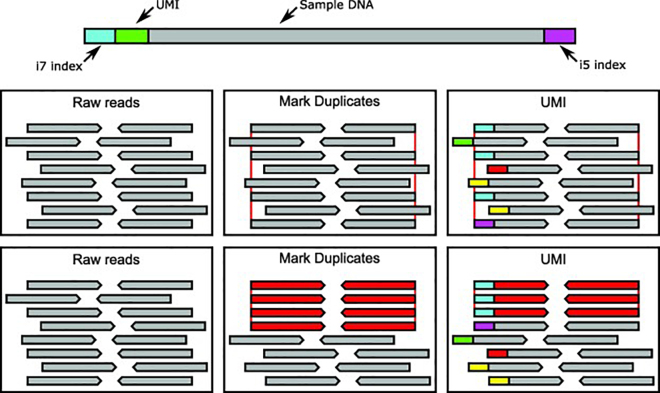
Next Generation Sequencing (NGS) has dramatically improved the flexibility and outcomes of cancer research and clinical trials, providing highly sensitive and accurate high-throughput platforms for large-scale genomic testing. In contrast to whole-genome (WGS) or whole-exome sequencing (WES), targeted genomic sequencing (TS) focuses on a panel of genes or targets known to have strong associations with pathogenesis of disease and/or clinical relevance, offering greater sequencing depth with reduced costs and data burden. This allows targeted sequencing to identify low frequency variants in targeted regions with high confidence, thus suitable for profiling low-quality and fragmented clinical DNA samples. As a result, TS has been widely used in clinical research and trials for patient stratification and the development of targeted therapeutics. However, its transition to routine clinical use has been slow. Many technical and analytical obstacles still remain and need to be discussed and addressed before large-scale and cross-centre implementation. Gold-standard and state-of-the-art procedures and pipelines are urgently needed to accelerate this transition. In this review we first present how TS is conducted in cancer research, including various target enrichment platforms, the construction of target panels, and selected research and clinical studies utilising TS to profile clinical samples. We then present a generalised analytical workflow for TS data discussing important parameters and filters in detail, aiming to provide the best practices of TS usage and analyses.
下一代测序(NGS)极大地提高了癌症研究和临床试验的灵活性及成果,为大规模基因组检测提供了高度灵敏且准确的高通量平台。与全基因组测序(WGS)或全外显子组测序(WES)不同,靶向基因组测序(TS)聚焦于一组已知与疾病发病机制和/或临床相关性有强关联的基因或靶点,能在降低成本和数据负担的同时提供更高的测序深度。这使得靶向测序能够高置信度地识别靶向区域中的低频变异,因而适用于分析低质量和片段化的临床DNA样本。因此,TS已广泛应用于临床研究和试验,用于患者分层及靶向治疗药物的开发。然而,其向常规临床应用的转变较为缓慢。在大规模和跨中心实施之前,许多技术和分析障碍仍然存在,需要进行讨论和解决。迫切需要金标准和最先进的程序及流程来加速这一转变。在本综述中,我们首先介绍TS在癌症研究中的实施方式,包括各种靶向富集平台、靶向panel的构建,以及利用TS分析临床样本的选定研究和临床研究。然后,我们介绍TS数据的通用分析流程,详细讨论重要参数和过滤条件,旨在提供TS使用和分析的最佳实践。