College of Computer Science and Information Technology, King Faisal University, Al-Ahsa, 31982, Saudi Arabia.
Center for Artificial Intelligence and RObotics (CAIRO), Faculty of Science, Aswan University, Aswan, 81528, Egypt.
Sci Rep. 2019 Dec 13;9(1):19038. doi: 10.1038/s41598-019-55320-6.
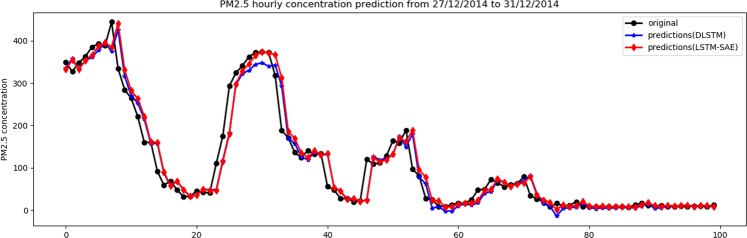
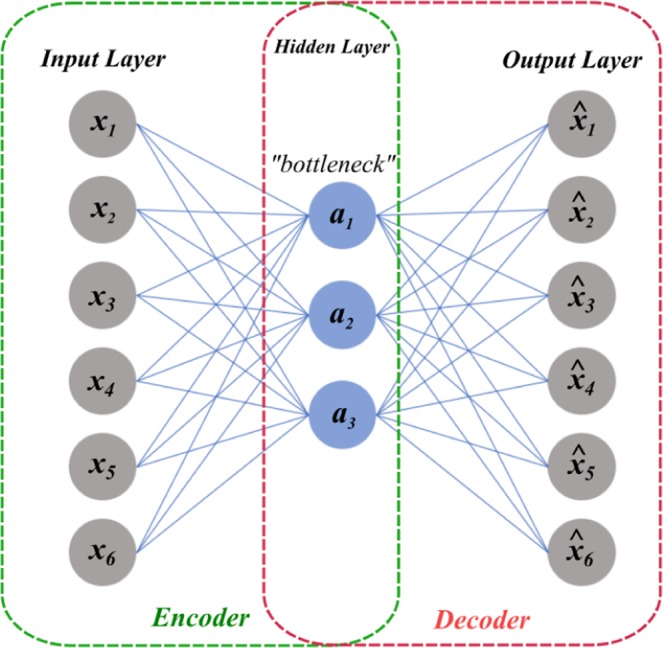
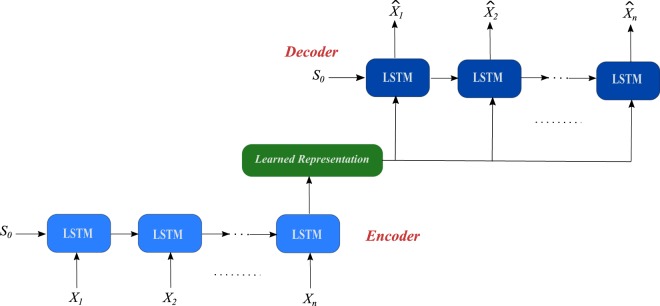
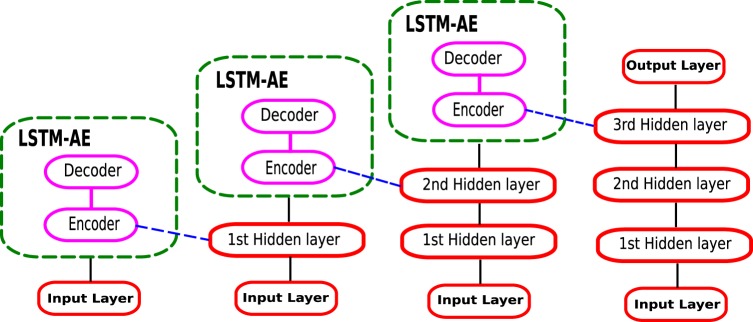
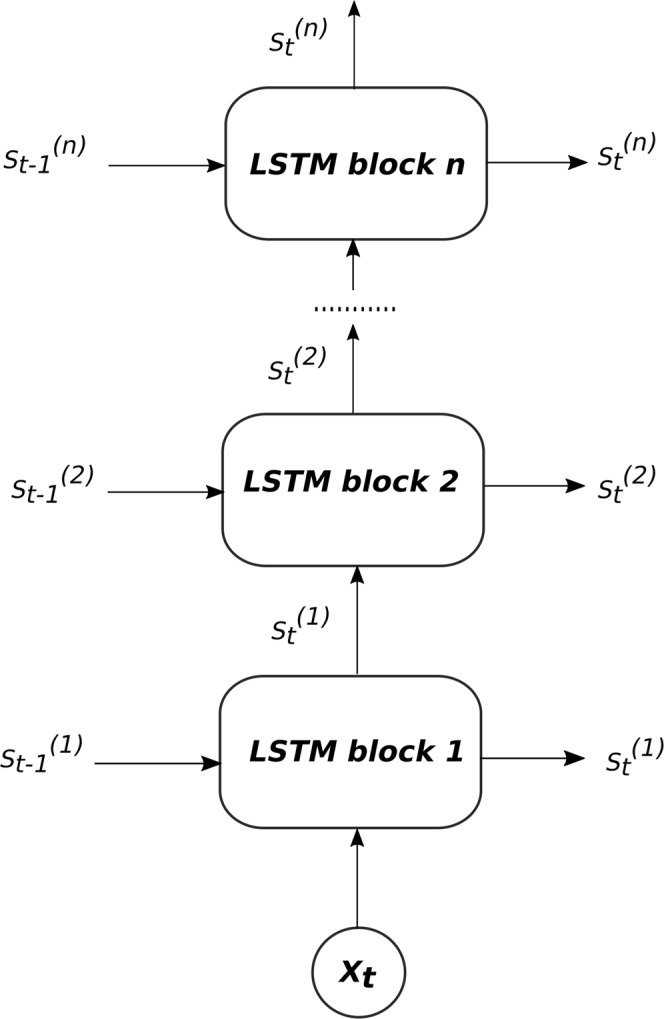
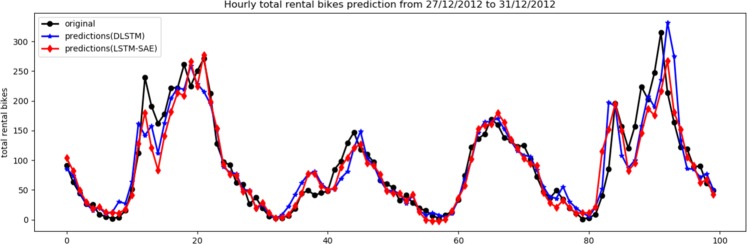
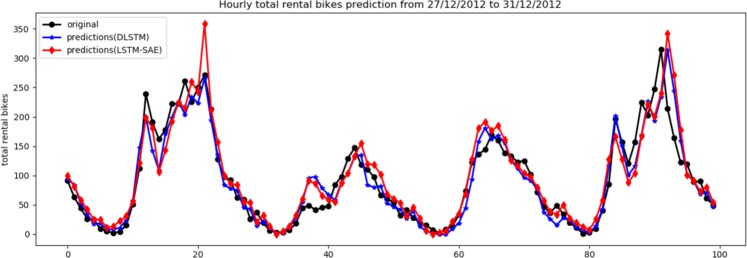
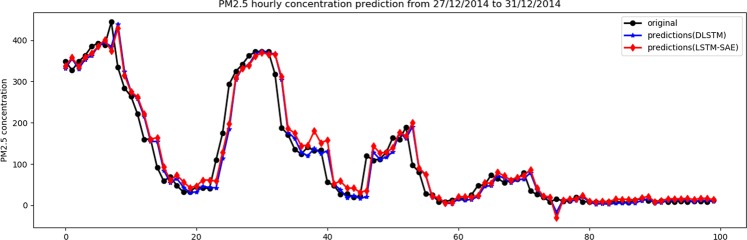
Currently, most real-world time series datasets are multivariate and are rich in dynamical information of the underlying system. Such datasets are attracting much attention; therefore, the need for accurate modelling of such high-dimensional datasets is increasing. Recently, the deep architecture of the recurrent neural network (RNN) and its variant long short-term memory (LSTM) have been proven to be more accurate than traditional statistical methods in modelling time series data. Despite the reported advantages of the deep LSTM model, its performance in modelling multivariate time series (MTS) data has not been satisfactory, particularly when attempting to process highly non-linear and long-interval MTS datasets. The reason is that the supervised learning approach initializes the neurons randomly in such recurrent networks, disabling the neurons that ultimately must properly learn the latent features of the correlated variables included in the MTS dataset. In this paper, we propose a pre-trained LSTM-based stacked autoencoder (LSTM-SAE) approach in an unsupervised learning fashion to replace the random weight initialization strategy adopted in deep LSTM recurrent networks. For evaluation purposes, two different case studies that include real-world datasets are investigated, where the performance of the proposed approach compares favourably with the deep LSTM approach. In addition, the proposed approach outperforms several reference models investigating the same case studies. Overall, the experimental results clearly show that the unsupervised pre-training approach improves the performance of deep LSTM and leads to better and faster convergence than other models.
目前,大多数真实世界的时间序列数据集都是多元的,并且包含了底层系统的丰富动态信息。这些数据集引起了广泛关注,因此,对这种高维数据集进行准确建模的需求正在增加。最近,递归神经网络(RNN)的深度架构及其变体长短期记忆(LSTM)已被证明在对时间序列数据进行建模方面比传统统计方法更准确。尽管深度 LSTM 模型具有报道的优势,但它在对多元时间序列(MTS)数据进行建模方面的性能并不令人满意,特别是在尝试处理高度非线性和长间隔 MTS 数据集时。原因是监督学习方法在这种递归网络中随机初始化神经元,从而使神经元无法最终正确学习 MTS 数据集中包含的相关变量的潜在特征。在本文中,我们提出了一种基于预训练 LSTM 的堆叠自动编码器(LSTM-SAE)方法,以无监督学习的方式替代深度 LSTM 递归网络中采用的随机权重初始化策略。为了评估目的,研究了两个包含真实数据集的不同案例研究,其中所提出方法的性能与深度 LSTM 方法相比具有优势。此外,所提出的方法优于调查相同案例研究的几个参考模型。总体而言,实验结果清楚地表明,无监督预训练方法可以提高深度 LSTM 的性能,并导致比其他模型更快更好的收敛。