Metha Jeremy A, Brian Maddison L, Oberrauch Sara, Barnes Samuel A, Featherby Travis J, Bossaerts Peter, Murawski Carsten, Hoyer Daniel, Jacobson Laura H
Sleep and Cognition, The Florey Institute of Neuroscience and Mental Health, Parkville, VIC, Australia.
Translational Neuroscience, Department of Pharmacology and Therapeutics, School of Biomedical Sciences, Faculty of Medicine, Dentistry and Health Sciences, The University of Melbourne, Parkville, VIC, Australia.
Front Behav Neurosci. 2020 Jan 9;13:270. doi: 10.3389/fnbeh.2019.00270. eCollection 2019.
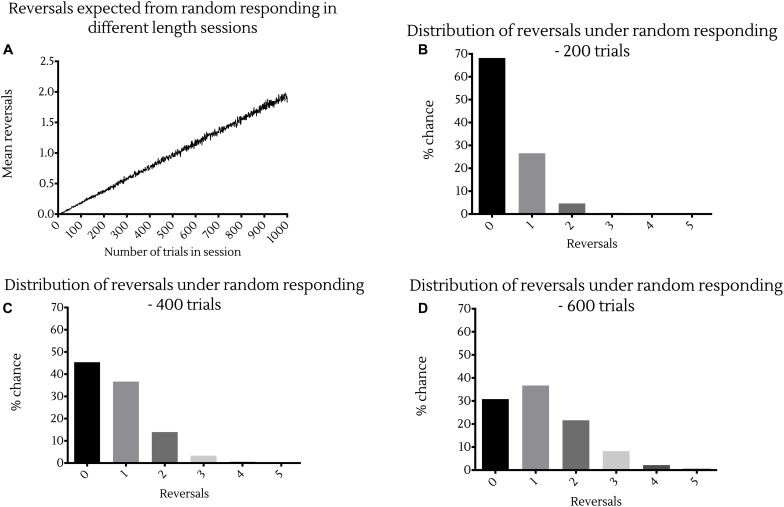
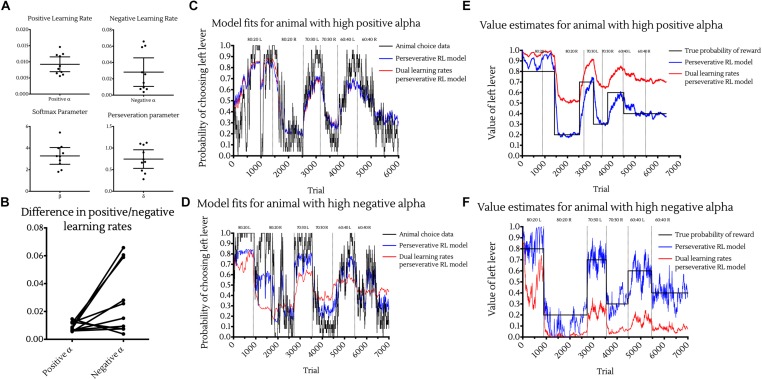
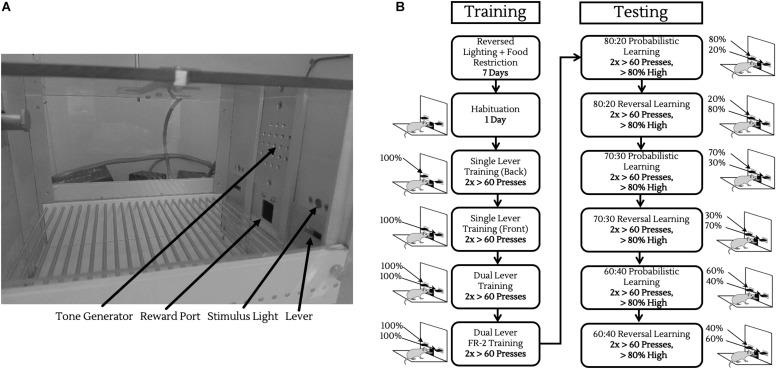
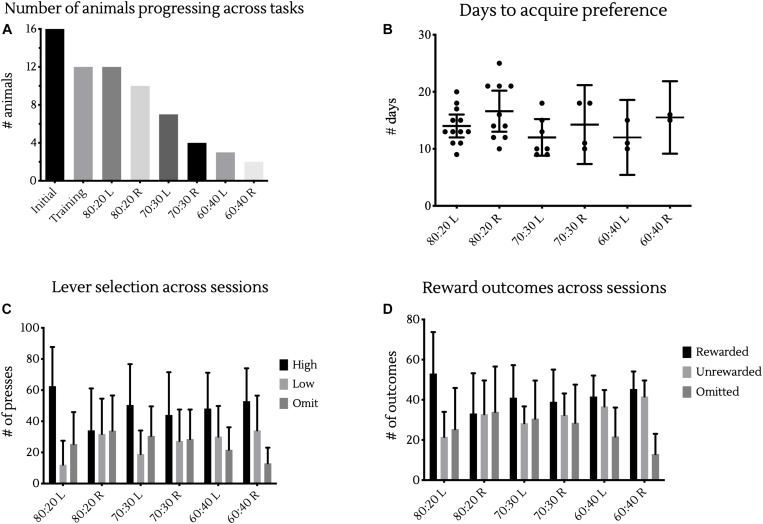
The exploration/exploitation tradeoff - pursuing a known reward vs. sampling from lesser known options in the hope of finding a better payoff - is a fundamental aspect of learning and decision making. In humans, this has been studied using multi-armed bandit tasks. The same processes have also been studied using simplified probabilistic reversal learning (PRL) tasks with binary choices. Our investigations suggest that protocols previously used to explore PRL in mice may prove beyond their cognitive capacities, with animals performing at a no-better-than-chance level. We sought a novel probabilistic learning task to improve behavioral responding in mice, whilst allowing the investigation of the exploration/exploitation tradeoff in decision making. To achieve this, we developed a two-lever operant chamber task with levers corresponding to different probabilities (high/low) of receiving a saccharin reward, reversing the reward contingencies associated with levers once animals reached a threshold of 80% responding at the high rewarding lever. We found that, unlike in existing PRL tasks, mice are able to learn and behave near optimally with 80% high/20% low reward probabilities. Altering the reward contingencies towards equality showed that some mice displayed preference for the high rewarding lever with probabilities as close as 60% high/40% low. Additionally, we show that animal choice behavior can be effectively modelled using reinforcement learning (RL) models incorporating learning rates for positive and negative prediction error, a perseveration parameter, and a noise parameter. This new decision task, coupled with RL analyses, advances access to investigate the neuroscience of the exploration/exploitation tradeoff in decision making.
探索/利用权衡——追求已知奖励与从不太知名的选项中进行抽样以期望获得更好的回报——是学习和决策的一个基本方面。在人类中,这已通过多臂赌博任务进行研究。同样的过程也使用具有二元选择的简化概率反转学习(PRL)任务进行了研究。我们的研究表明,先前用于在小鼠中探索PRL的方案可能超出了它们的认知能力,动物的表现仅处于随机水平。我们寻求一种新颖的概率学习任务来改善小鼠的行为反应,同时允许对决策中的探索/利用权衡进行研究。为了实现这一点,我们开发了一种双杠杆操作性条件反射箱任务,其中杠杆对应于获得糖精奖励的不同概率(高/低),一旦动物在高奖励杠杆上的反应达到80%的阈值,就反转与杠杆相关的奖励偶然性。我们发现,与现有的PRL任务不同,小鼠能够在80%高/20%低奖励概率的情况下近乎最优地学习和表现。将奖励偶然性改变为相等表明,一些小鼠在高奖励杠杆的概率低至60%高/40%低时仍表现出偏好。此外,我们表明,使用包含正、负预测误差的学习率、坚持参数和噪声参数的强化学习(RL)模型可以有效地模拟动物的选择行为。这个新的决策任务,再加上RL分析,为研究决策中探索/利用权衡的神经科学提供了便利。