Institute of Cognitive Neuroscience, University College London, London, United Kingdom.
Research Department of Clinical, Educational and Health Psychology, University College London, London, United Kingdom.
Elife. 2023 Nov 14;12:RP87720. doi: 10.7554/eLife.87720.
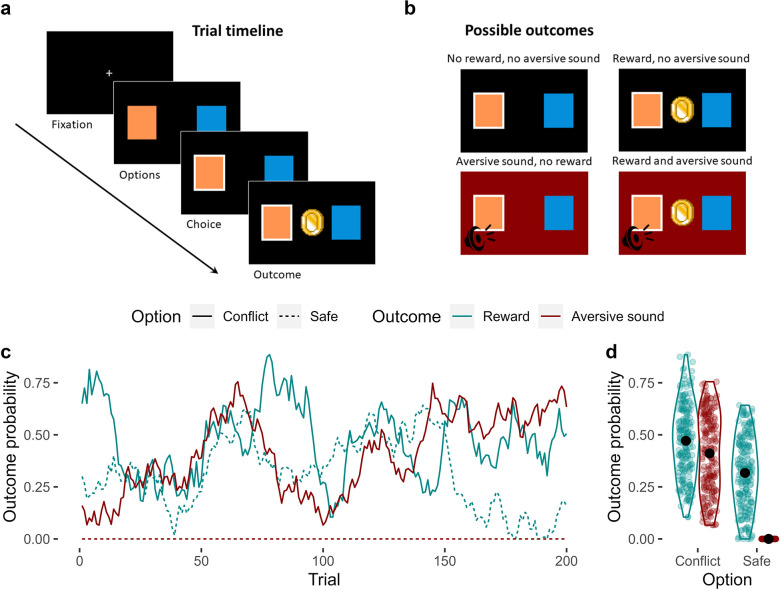
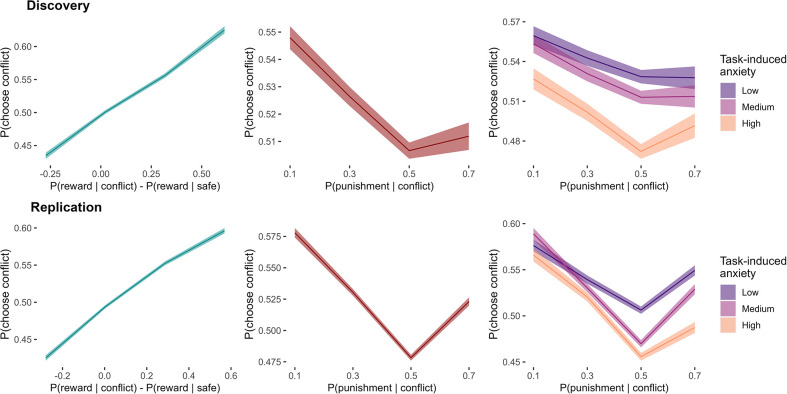
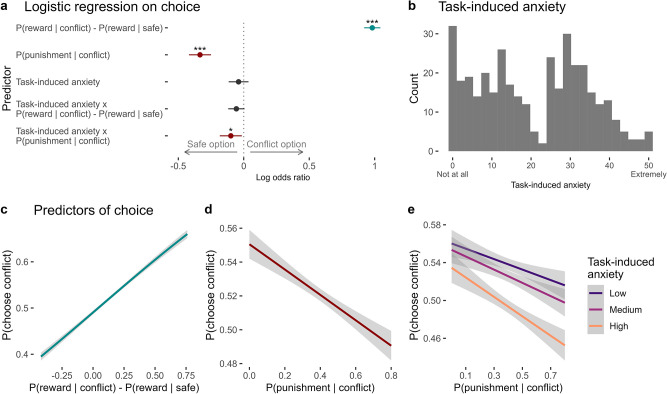
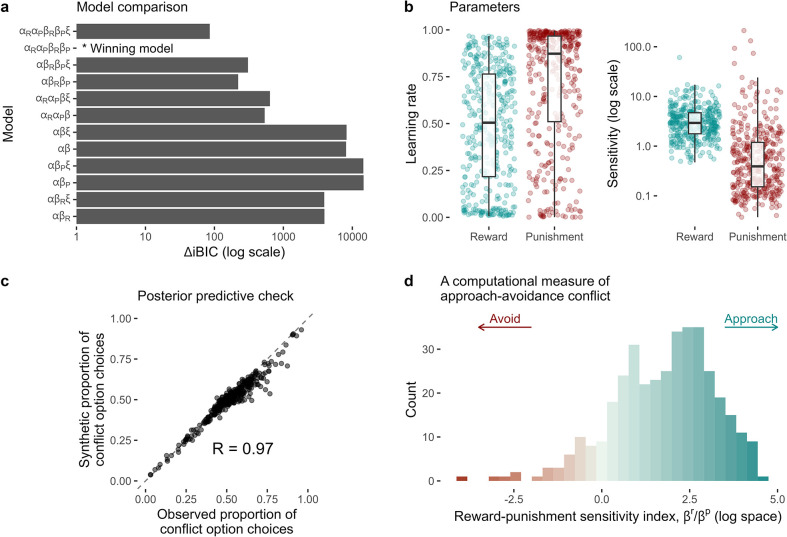
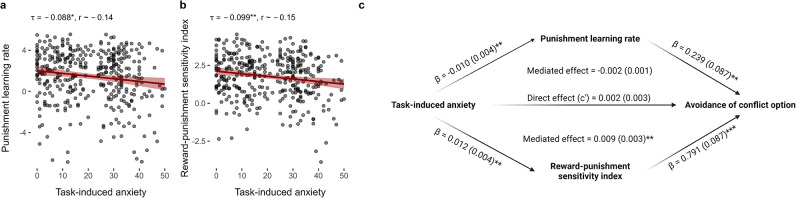
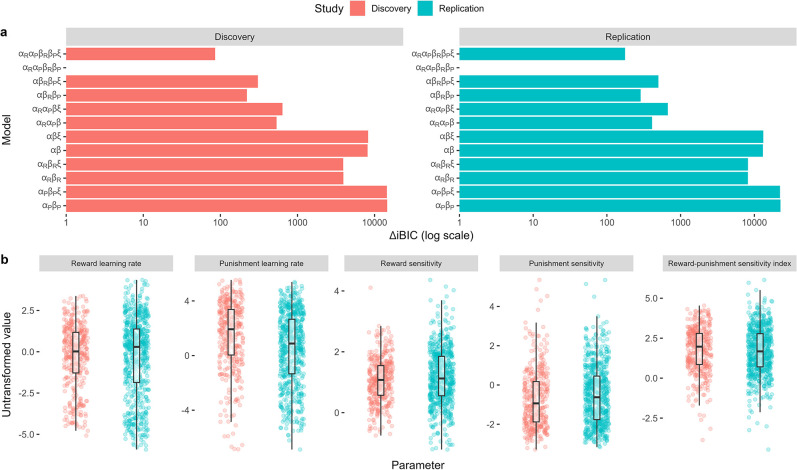
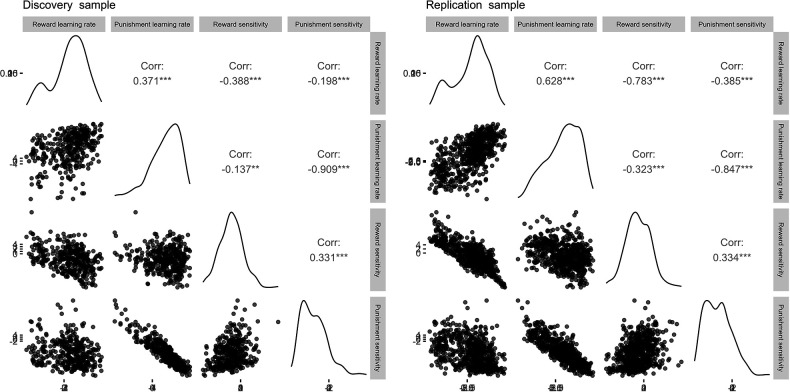
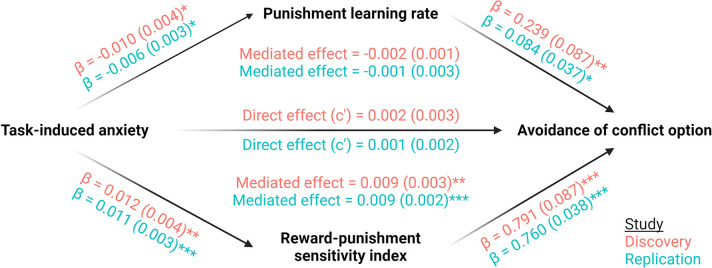
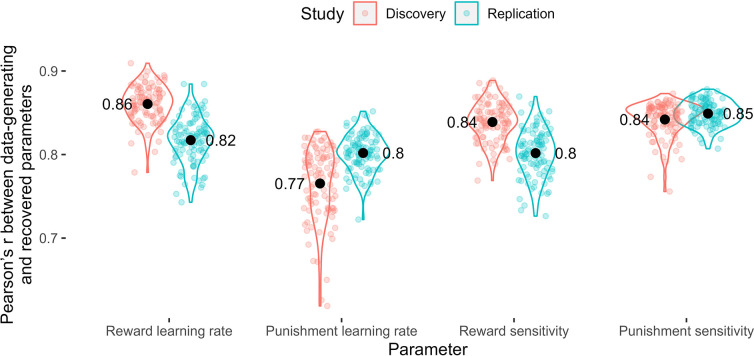
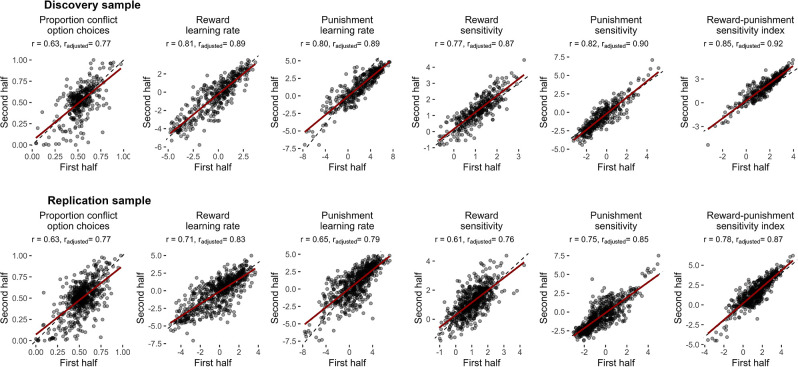
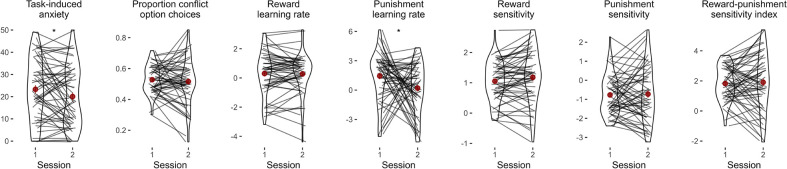
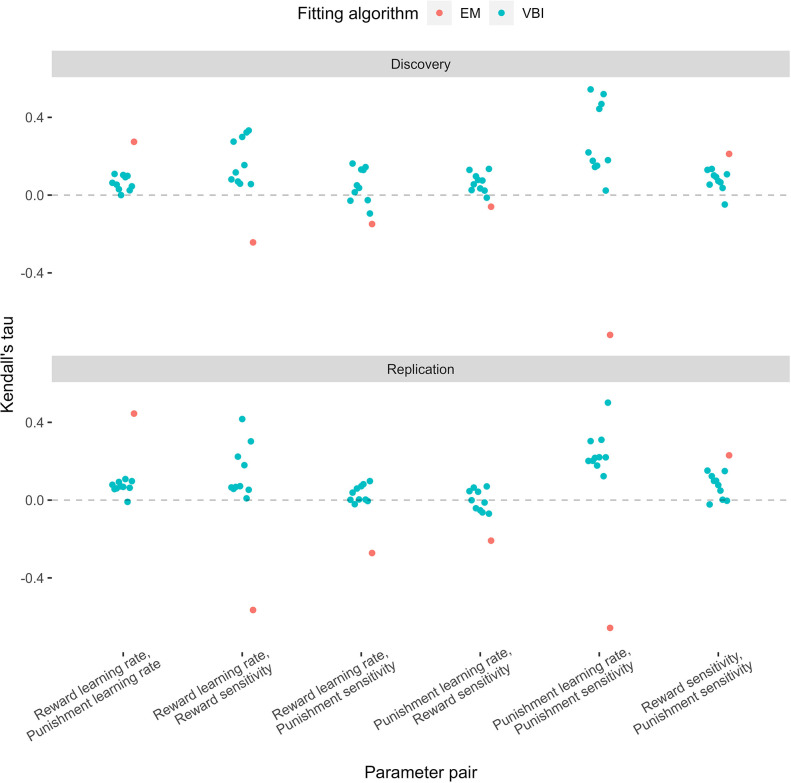
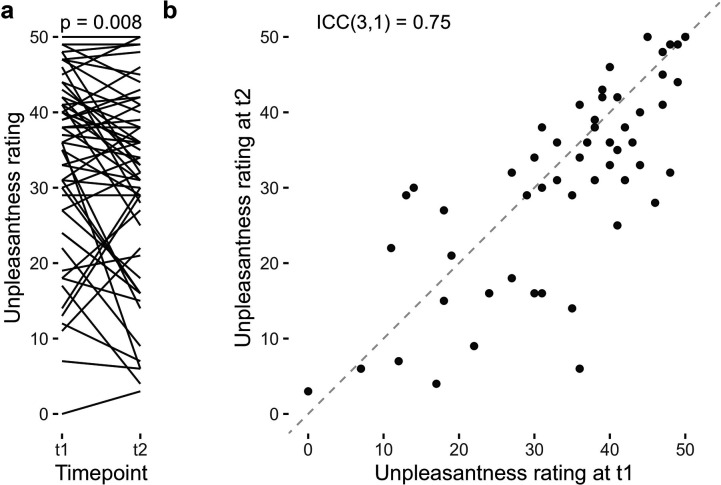
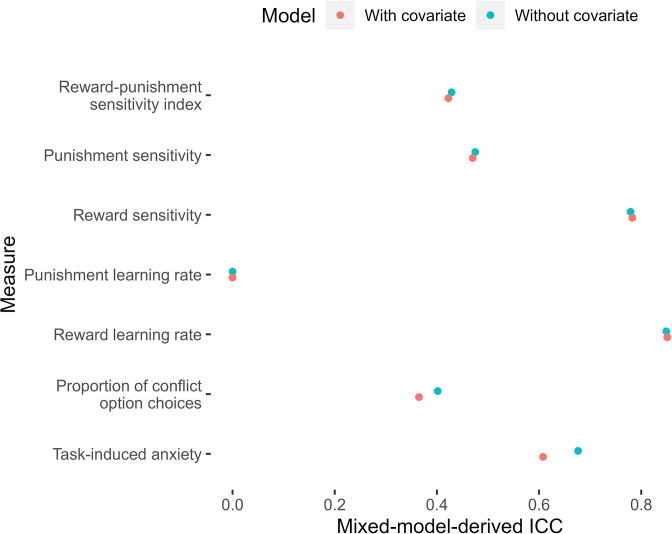
Although avoidance is a prevalent feature of anxiety-related psychopathology, differences in the measurement of avoidance between humans and non-human animals hinder our progress in its theoretical understanding and treatment. To address this, we developed a novel translational measure of anxiety-related avoidance in the form of an approach-avoidance reinforcement learning task, by adapting a paradigm from the non-human animal literature to study the same cognitive processes in human participants. We used computational modelling to probe the putative cognitive mechanisms underlying approach-avoidance behaviour in this task and investigated how they relate to subjective task-induced anxiety. In a large online study (n = 372), participants who experienced greater task-induced anxiety avoided choices associated with punishment, even when this resulted in lower overall reward. Computational modelling revealed that this effect was explained by greater individual sensitivities to punishment relative to rewards. We replicated these findings in an independent sample (n = 627) and we also found fair-to-excellent reliability of measures of task performance in a sub-sample retested 1 week later (n = 57). Our findings demonstrate the potential of approach-avoidance reinforcement learning tasks as translational and computational models of anxiety-related avoidance. Future studies should assess the predictive validity of this approach in clinical samples and experimental manipulations of anxiety.
虽然回避是与焦虑相关的精神病理学的一个普遍特征,但人类和非人类动物之间回避测量的差异阻碍了我们对其理论理解和治疗的进展。为了解决这个问题,我们开发了一种新的焦虑相关回避的翻译测量方法,以一种接近回避强化学习任务的形式,通过从非人类动物文献中改编一个范例来研究人类参与者中相同的认知过程。我们使用计算建模来探测该任务中接近回避行为的潜在认知机制,并研究它们与主观任务引起的焦虑之间的关系。在一项大型在线研究(n=372)中,与惩罚相关的回避选择与经历更大的任务引起的焦虑有关,即使这导致了更低的总体奖励。计算建模表明,这种效应是由相对于奖励而言更大的个体对惩罚的敏感性来解释的。我们在一个独立的样本(n=627)中复制了这些发现,并且我们还发现了在一周后重新测试的子样本中任务表现的测量值具有良好到优秀的可靠性(n=57)。我们的研究结果表明,接近回避强化学习任务具有作为焦虑相关回避的转化和计算模型的潜力。未来的研究应该评估这种方法在临床样本和焦虑的实验操作中的预测有效性。