Bioinformatics, Department of Physics, Chemistry and Biology, Linköping University, Linköping, Sweden.
Department of Biology, Center For Genomics and Systems Biology, New York University, New York, NY, 10008, USA.
Nat Commun. 2020 Feb 12;11(1):856. doi: 10.1038/s41467-020-14666-6.
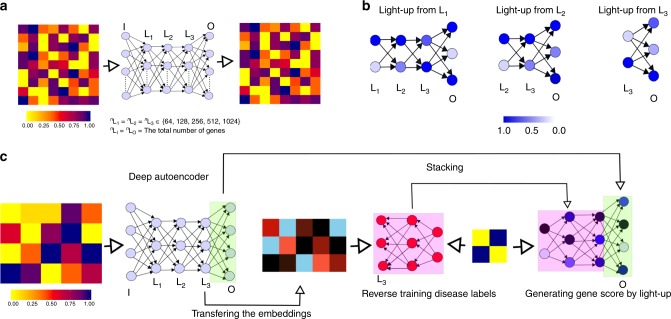
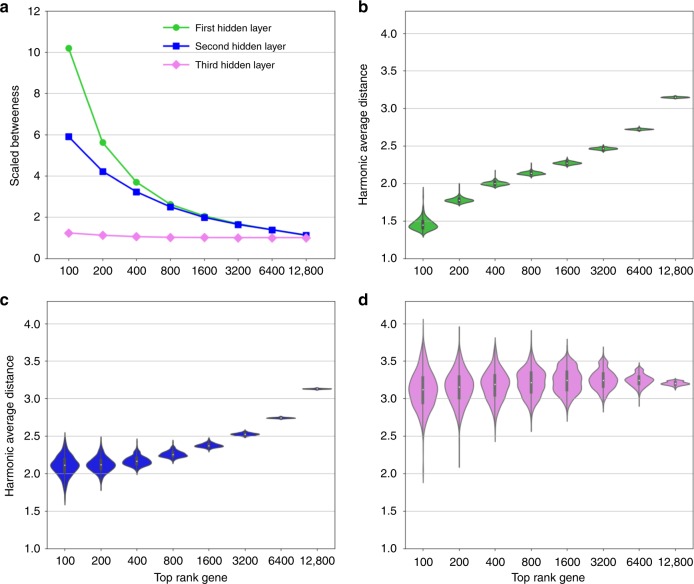
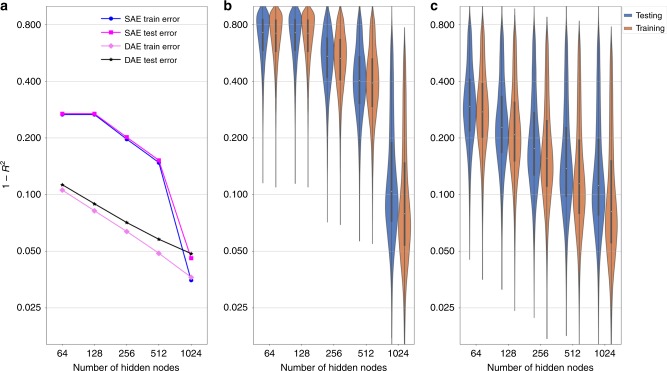
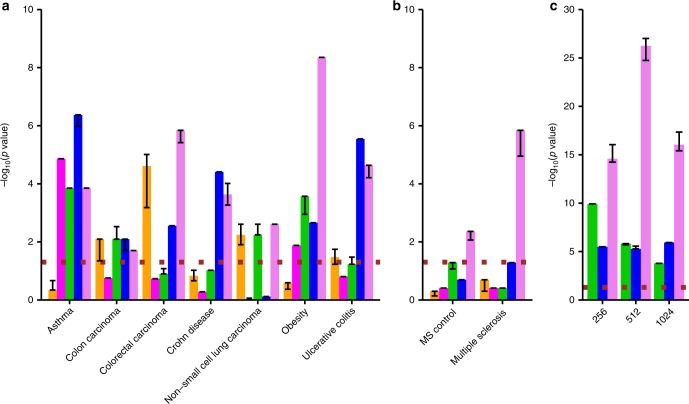
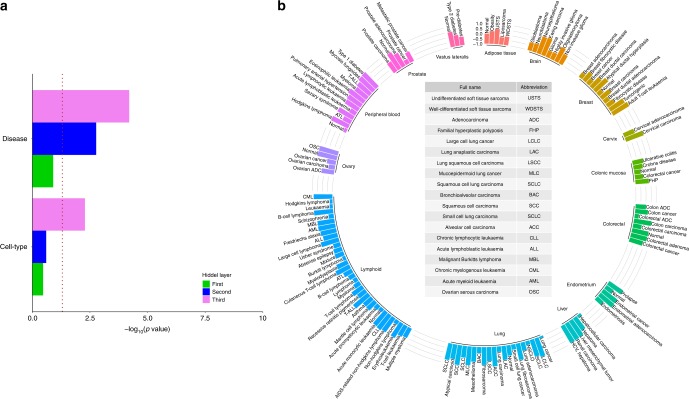
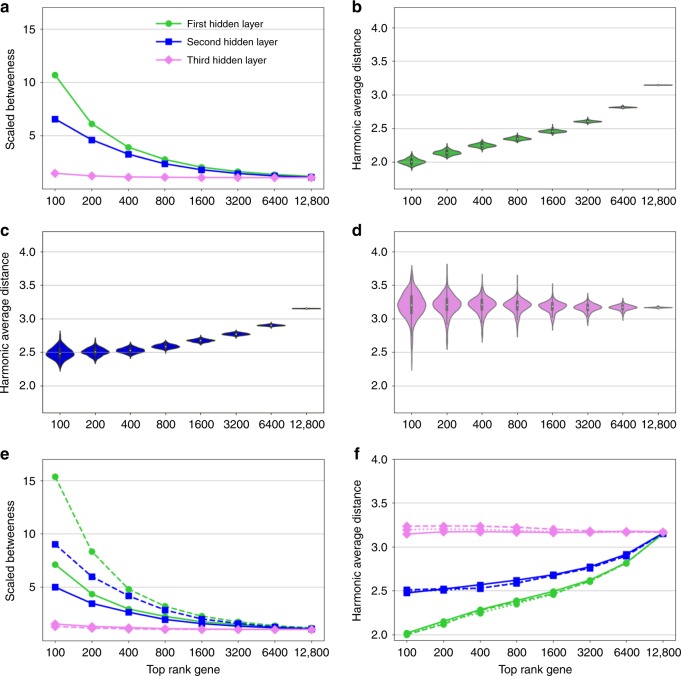
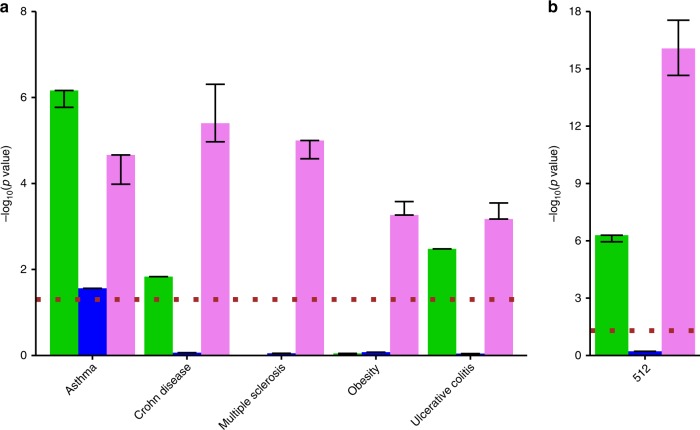
Disease modules in molecular interaction maps have been useful for characterizing diseases. Yet biological networks, that commonly define such modules are incomplete and biased toward some well-studied disease genes. Here we ask whether disease-relevant modules of genes can be discovered without prior knowledge of a biological network, instead training a deep autoencoder from large transcriptional data. We hypothesize that modules could be discovered within the autoencoder representations. We find a statistically significant enrichment of genome-wide association studies (GWAS) relevant genes in the last layer, and to a successively lesser degree in the middle and first layers respectively. In contrast, we find an opposite gradient where a modular protein-protein interaction signal is strongest in the first layer, but then vanishing smoothly deeper in the network. We conclude that a data-driven discovery approach is sufficient to discover groups of disease-related genes.
分子互作图谱中的疾病模块在疾病表征中具有重要作用。然而,这些通常用于定义模块的生物网络并不完整,并且偏向于一些研究较为充分的疾病基因。在此,我们提出一个问题,即在不依赖生物网络的先验知识的情况下,是否可以通过从大量转录组数据中训练深度自动编码器来发现与疾病相关的基因模块。我们假设可以在自动编码器的表示中发现模块。我们发现,全基因组关联研究(GWAS)相关基因在最后一层的富集程度具有统计学意义,而在中间层和第一层的富集程度依次降低。相比之下,我们发现了一个相反的梯度,其中模块化的蛋白质-蛋白质相互作用信号在第一层最强,但在网络的更深层次则逐渐平滑消失。我们得出结论,数据驱动的发现方法足以发现与疾病相关的基因群。