Yang Sen, Wang Yan, Zhang Shuangquan, Hu Xuemei, Ma Qin, Tian Yuan
Key Laboratory of Symbol Computation and Knowledge Engineering of Ministry of Education, and College of Computer Science and Technology, Jilin University, Changchun, China.
School of Artificial Intelligence, Jilin University, Changchun, China.
Front Genet. 2020 Feb 28;11:90. doi: 10.3389/fgene.2020.00090. eCollection 2020.
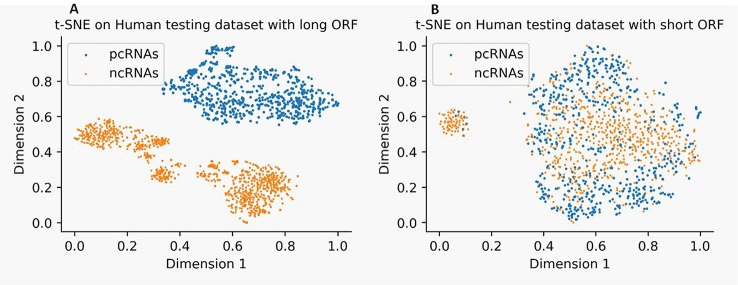
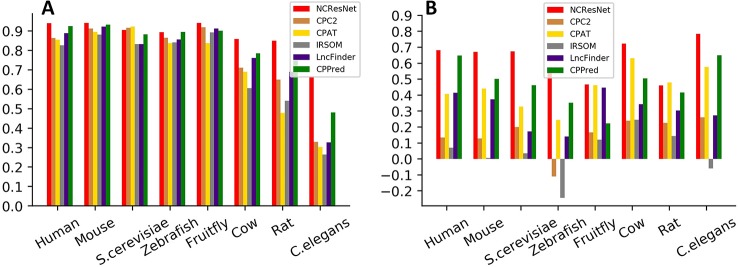
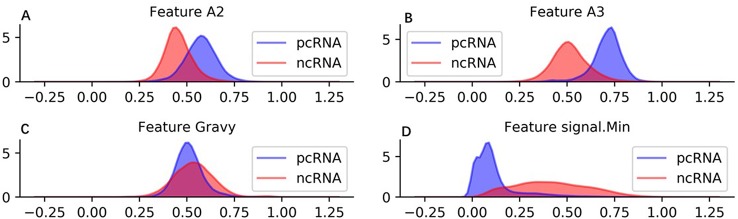
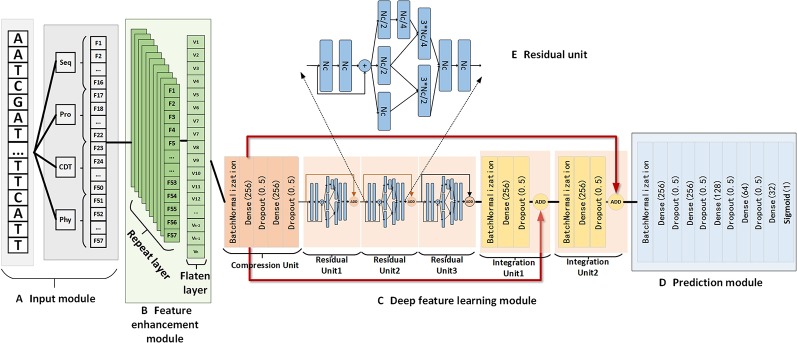
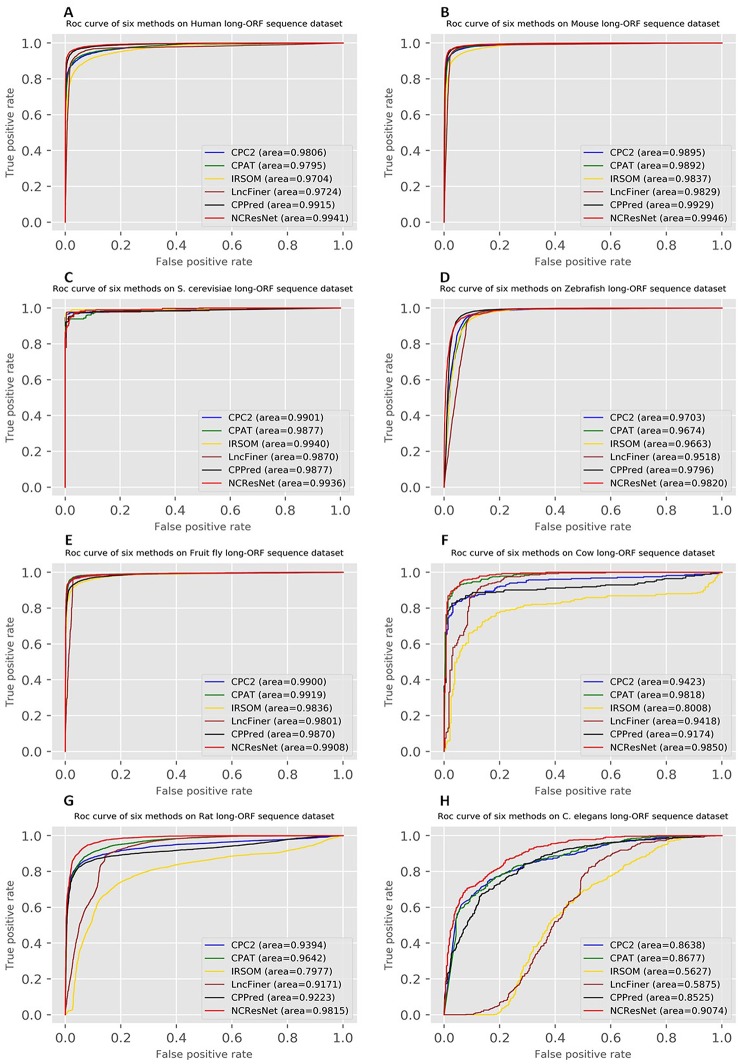
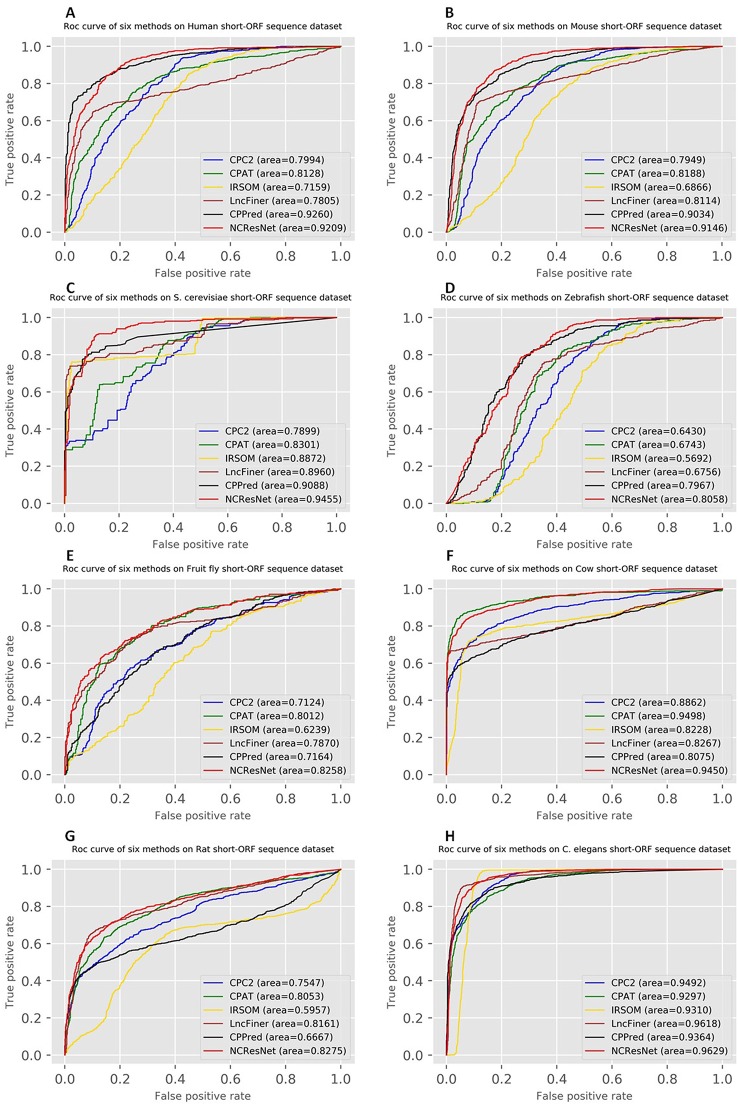
Noncoding RNA (ncRNA) is a kind of RNA that plays an important role in many biological processes, diseases, and cancers, while cannot translate into proteins. With the development of next-generation sequence technology, thousands of novel RNAs with long open reading frames (ORFs, longest ORF length > 303 nt) and short ORFs (longest ORF length ≤ 303 nt) have been discovered in a short time. How to identify ncRNAs more precisely from novel unannotated RNAs is an important step for RNA functional analysis, RNA regulation, . However, most previous methods only utilize the information of sequence features. Meanwhile, most of them have focused on long-ORF RNA sequences, but not adapted to short-ORF RNA sequences. In this paper, we propose a new reliable method called NCResNet. NCResNet employs 57 hybrid features of four categories as inputs, including sequence, protein, RNA structure, and RNA physicochemical properties, and introduces feature enhancement and deep feature learning policies in a neural net model to adapt to this problem. The experiments on benchmark datasets of 8 species shows NCResNet has higher accuracy and higher Matthews correlation coefficient (MCC) compared with other state-of-the-art methods. Particularly, on four short-ORF RNA sequence datasets, specifically mouse, , zebrafish, and cow, NCResNet achieves greater than 10 and 15% improvements over other state-of-the-art methods in terms of accuracy and MCC. Meanwhile, for long-ORF RNA sequence datasets, NCResNet also has better accuracy and MCC than other state-of-the-art methods on most test datasets. Codes and data are available at https://github.com/abcair/NCResNet.
非编码RNA(ncRNA)是一类RNA,它在许多生物过程、疾病和癌症中发挥着重要作用,但不能翻译成蛋白质。随着下一代测序技术的发展,在短时间内发现了数千种具有长开放阅读框(ORF,最长ORF长度>303 nt)和短开放阅读框(最长ORF长度≤303 nt)的新型RNA。如何从新的未注释RNA中更精确地识别ncRNA是RNA功能分析、RNA调控的重要一步。然而,以前的大多数方法只利用序列特征信息。同时,它们中的大多数都集中在长ORF RNA序列上,而不适用于短ORF RNA序列。在本文中,我们提出了一种新的可靠方法,称为NCResNet。NCResNet采用四类57种混合特征作为输入,包括序列、蛋白质、RNA结构和RNA理化性质,并在神经网络模型中引入特征增强和深度特征学习策略来适应这一问题。对8个物种的基准数据集进行的实验表明,与其他现有方法相比,NCResNet具有更高的准确率和更高的马修斯相关系数(MCC)。特别是,在四个短ORF RNA序列数据集上,即小鼠、斑马鱼和牛,NCResNet在准确率和MCC方面比其他现有方法有超过10%和15%的提升。同时,对于长ORF RNA序列数据集,在大多数测试数据集上,NCResNet也比其他现有方法具有更好的准确率和MCC。代码和数据可在https://github.com/abcair/NCResNet上获取。