Li Jing, Zhang Xuan, Liu Changning
CAS Key Laboratory of Tropical Plant Resources and Sustainable Use, Xishuangbanna Tropical Botanical Garden, Chinese Academy of Sciences, Menglun, Mengla, Yunnan 666303, China.
Center of Economic Botany, Core Botanical Gardens, Chinese Academy of Sciences, Menglun, Mengla, Yunnan 666303, China.
Comput Struct Biotechnol J. 2020 Nov 19;18:3666-3677. doi: 10.1016/j.csbj.2020.11.030. eCollection 2020.
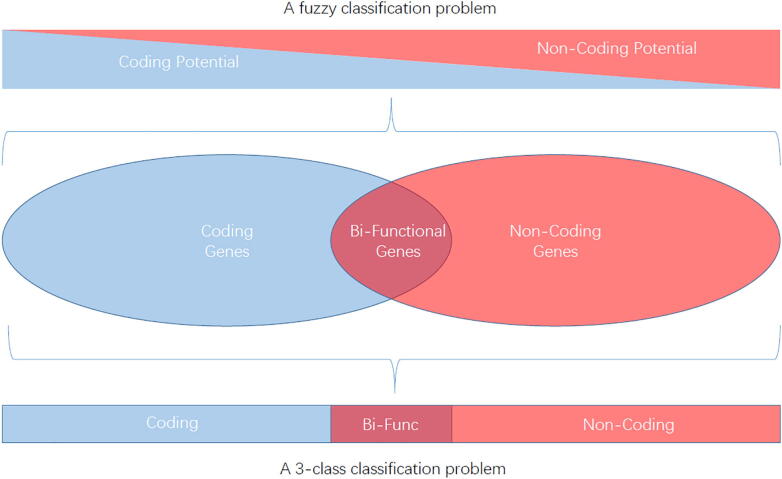
Long noncoding RNAs (lncRNAs) make up a large proportion of transcriptome in eukaryotes, and have been revealed with many regulatory functions in various biological processes. When studying lncRNAs, the first step is to accurately and specifically distinguish them from the colossal transcriptome data with complicated composition, which contains mRNAs, lncRNAs, small RNAs and their primary transcripts. In the face of such a huge and progressively expanding transcriptome data, the approaches provide a practicable scheme for effectively and rapidly filtering out lncRNA targets, using machine learning and probability statistics. In this review, we mainly discussed the characteristics of algorithms and features on currently developed approaches. We also outlined the traits of some state-of-the-art tools for ease of operation. Finally, we pointed out the underlying challenges in lncRNA identification with the advent of new experimental data.
长链非编码RNA(lncRNAs)在真核生物转录组中占很大比例,并已在各种生物过程中显示出许多调控功能。在研究lncRNAs时,第一步是要从复杂组成的庞大转录组数据中准确、特异性地将它们区分出来,这些数据包含mRNA、lncRNA、小RNA及其初级转录本。面对如此庞大且不断扩展的转录组数据,这些方法利用机器学习和概率统计提供了一个切实可行的方案,用于有效且快速地筛选出lncRNA靶点。在本综述中,我们主要讨论了当前已开发方法的算法特点和特征。我们还概述了一些便于操作的最先进工具的特性。最后,我们指出了随着新实验数据出现,lncRNA识别中潜在的挑战。