Bioinformatics and Functional Genomics Group, Cancer Research Center (CiC-IMBCC, CSIC/USAL/IBSAL), Consejo Superior de Investigaciones Científicas (CSIC) and University of Salamanca (USAL), 37007 Salamanca, Spain.
Department of Chemistry, Pontifical Catholic University of Puerto Rico (PCUPR), 00717 Ponce, Puerto Rico.
Biomolecules. 2020 Apr 25;10(5):667. doi: 10.3390/biom10050667.
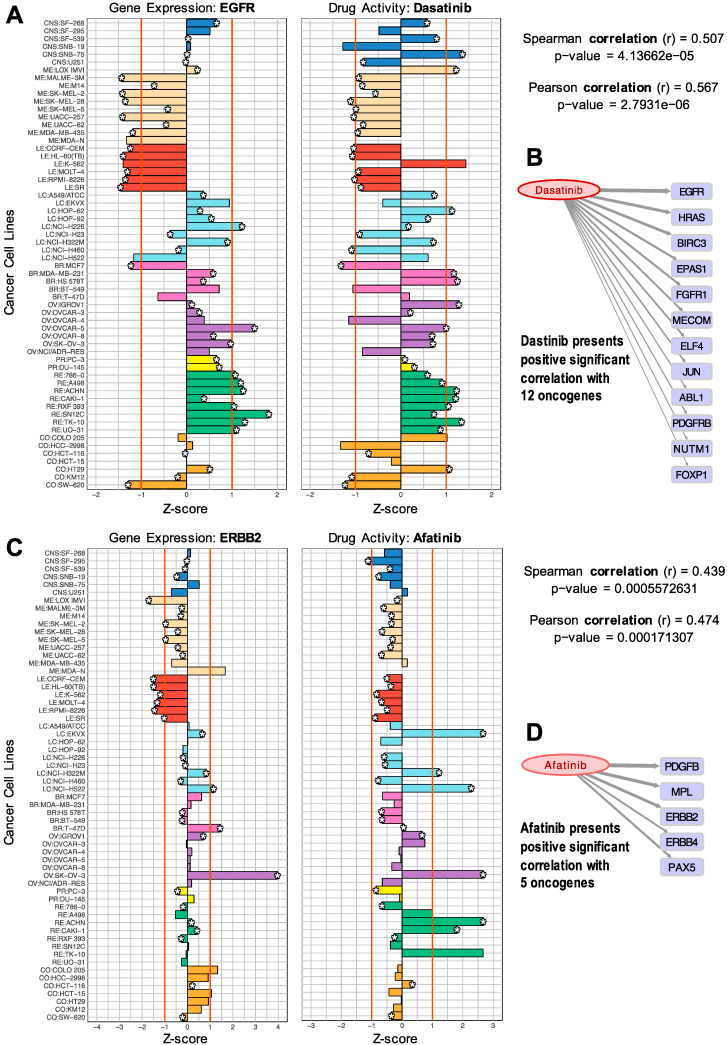
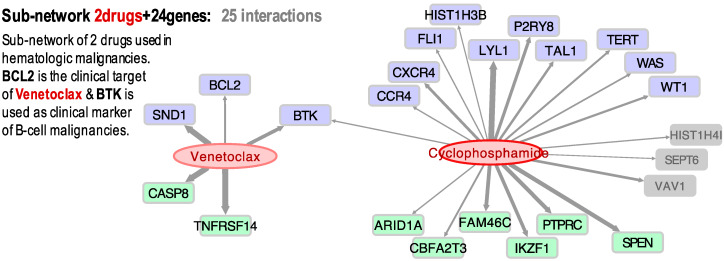
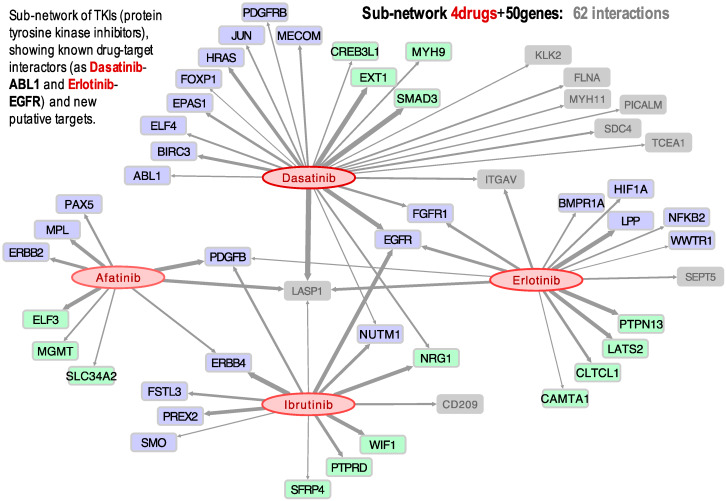
Cancer is a complex disease affecting millions of people worldwide, with over a hundred clinically approved drugs available. In order to improve therapy, treatment, and response, it is essential to draw better maps of the targets of cancer drugs and possible side interactors. This study presents a large-scale screening method to find associations of cancer drugs with human genes. The analysis is focused on the current collection of Food and Drug Administration (FDA)-approved drugs (which includes about one hundred chemicals). The approach integrates global gene-expression transcriptomic profiles with drug-activity profiles of a set of 60 human cell lines obtained for a collection of chemical compounds (small bioactive molecules). Using a standardized expression for each gene versus standardized activity for each drug, Pearson and Spearman correlations were calculated for all possible pairwise gene-drug combinations. These correlations were used to build a global bipartite network that includes 1007 gene-drug significant associations. The data are integrated into an open web-tool called GEDA (Gene Expression and Drug Activity) which includes a relational view of cancer drugs and genes, disclosing the putative indirect interactions found for FDA-approved drugs as well as the known targets of these drugs. The results also provide insight into the complex action of pharmaceuticals, presenting an alternative view to address predicted pleiotropic effects of the drugs.
癌症是一种影响全球数百万人的复杂疾病,目前已有超过一百种临床批准的药物。为了改善治疗效果、治疗方法和反应,有必要更好地绘制癌症药物的靶点和可能的相互作用的图谱。本研究提出了一种大规模筛选方法,以发现癌症药物与人类基因之间的关联。该分析集中在当前食品和药物管理局 (FDA) 批准的药物(约含 100 种化学物质)。该方法将全球基因表达转录组图谱与一组 60 个人类细胞系的药物活性图谱相结合,这些细胞系是为一组化学化合物(小型生物活性分子)获得的。使用每个基因的标准化表达与每个药物的标准化活性,计算了所有可能的基因-药物对组合的 Pearson 和 Spearman 相关性。这些相关性用于构建一个包含 1007 个基因-药物显著关联的全局二分网络。这些数据被整合到一个名为 GEDA(基因表达和药物活性)的开放网络工具中,该工具包括癌症药物和基因的关系视图,揭示了 FDA 批准药物的潜在间接相互作用以及这些药物的已知靶点。研究结果还深入了解了药物的复杂作用,为解决药物的潜在多效性预测提供了另一种视角。