Mahajan Diwakar, Poddar Ananya, Liang Jennifer J, Lin Yen-Ting, Prager John M, Suryanarayanan Parthasarathy, Raghavan Preethi, Tsou Ching-Huei
IBM Research, Yorktown Heights, NY, United States.
National Taiwan University, Taipei, Taiwan.
JMIR Med Inform. 2020 Nov 27;8(11):e22508. doi: 10.2196/22508.
Although electronic health records (EHRs) have been widely adopted in health care, effective use of EHR data is often limited because of redundant information in clinical notes introduced by the use of templates and copy-paste during note generation. Thus, it is imperative to develop solutions that can condense information while retaining its value. A step in this direction is measuring the semantic similarity between clinical text snippets. To address this problem, we participated in the 2019 National NLP Clinical Challenges (n2c2)/Open Health Natural Language Processing Consortium (OHNLP) clinical semantic textual similarity (ClinicalSTS) shared task.
This study aims to improve the performance and robustness of semantic textual similarity in the clinical domain by leveraging manually labeled data from related tasks and contextualized embeddings from pretrained transformer-based language models.
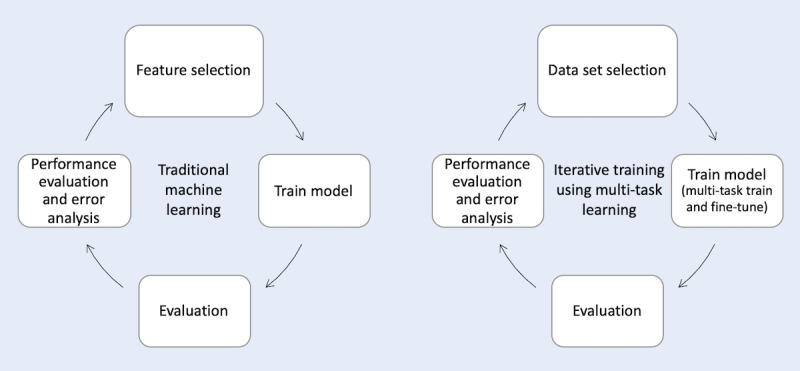
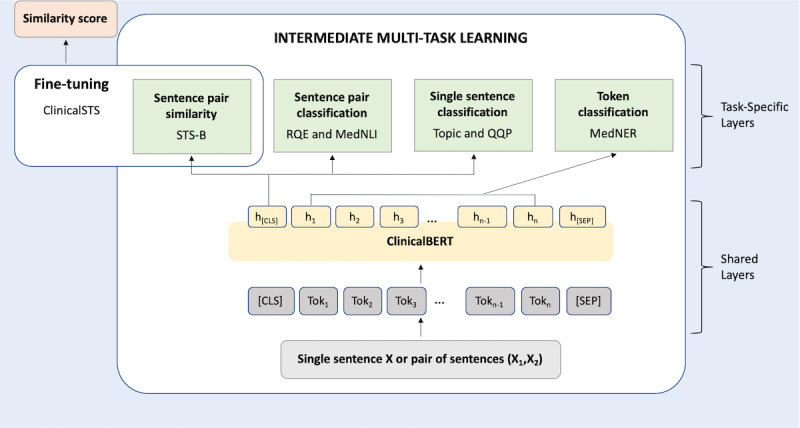
The ClinicalSTS data set consists of 1642 pairs of deidentified clinical text snippets annotated in a continuous scale of 0-5, indicating degrees of semantic similarity. We developed an iterative intermediate training approach using multi-task learning (IIT-MTL), a multi-task training approach that employs iterative data set selection. We applied this process to bidirectional encoder representations from transformers on clinical text mining (ClinicalBERT), a pretrained domain-specific transformer-based language model, and fine-tuned the resulting model on the target ClinicalSTS task. We incrementally ensembled the output from applying IIT-MTL on ClinicalBERT with the output of other language models (bidirectional encoder representations from transformers for biomedical text mining [BioBERT], multi-task deep neural networks [MT-DNN], and robustly optimized BERT approach [RoBERTa]) and handcrafted features using regression-based learning algorithms. On the basis of these experiments, we adopted the top-performing configurations as our official submissions.
Our system ranked first out of 87 submitted systems in the 2019 n2c2/OHNLP ClinicalSTS challenge, achieving state-of-the-art results with a Pearson correlation coefficient of 0.9010. This winning system was an ensembled model leveraging the output of IIT-MTL on ClinicalBERT with BioBERT, MT-DNN, and handcrafted medication features.
This study demonstrates that IIT-MTL is an effective way to leverage annotated data from related tasks to improve performance on a target task with a limited data set. This contribution opens new avenues of exploration for optimized data set selection to generate more robust and universal contextual representations of text in the clinical domain.
尽管电子健康记录(EHR)已在医疗保健领域广泛应用,但由于在病历生成过程中使用模板和复制粘贴导致临床记录中存在冗余信息,EHR数据的有效利用往往受到限制。因此,开发能够浓缩信息同时保留其价值的解决方案势在必行。朝着这个方向迈出的一步是测量临床文本片段之间的语义相似度。为了解决这个问题,我们参加了2019年全国自然语言处理临床挑战(n2c2)/开放健康自然语言处理联盟(OHNLP)临床语义文本相似度(ClinicalSTS)共享任务。
本研究旨在通过利用相关任务的人工标注数据和基于预训练的基于Transformer的语言模型的上下文嵌入,提高临床领域语义文本相似度的性能和鲁棒性。
ClinicalSTS数据集由1642对去标识化的临床文本片段组成,这些片段以0 - 5的连续尺度进行标注,表明语义相似程度。我们开发了一种使用多任务学习的迭代中间训练方法(IIT - MTL),这是一种采用迭代数据集选择的多任务训练方法。我们将此过程应用于临床文本挖掘的Transformer双向编码器表示(ClinicalBERT),这是一种预训练的特定领域基于Transformer的语言模型,并在目标ClinicalSTS任务上对所得模型进行微调。我们逐步将在ClinicalBERT上应用IIT - MTL的输出与其他语言模型(生物医学文本挖掘的Transformer双向编码器表示[BioBERT]、多任务深度神经网络[MT - DNN]和稳健优化的BERT方法[RoBERTa])的输出以及使用基于回归的学习算法的手工制作特征进行集成。基于这些实验,我们采用表现最佳的配置作为我们的正式提交。
在2019年n2c2/OHNLP ClinicalSTS挑战中,我们的系统在87个提交系统中排名第一,以0.9010的皮尔逊相关系数取得了领先成果。这个获胜系统是一个集成模型,它利用了在ClinicalBERT上应用IIT - MTL与BioBERT、MT - DNN以及手工制作的药物特征的输出。
本研究表明,IIT - MTL是利用相关任务的标注数据来提高在有限数据集上目标任务性能的有效方法。这一贡献为优化数据集选择开辟了新的探索途径,以生成临床领域中文本更稳健和通用的上下文表示。