Zhu Hongyin, Zeng Yi, Wang Dongsheng, Huangfu Cunqing
Research Center for Brain-Inspired Intelligence, Institute of Automation, Chinese Academy of Sciences, Beijing, China.
School of Artificial Intelligence, University of Chinese Academy of Sciences, Beijing, China.
Front Hum Neurosci. 2020 Apr 21;14:128. doi: 10.3389/fnhum.2020.00128. eCollection 2020.
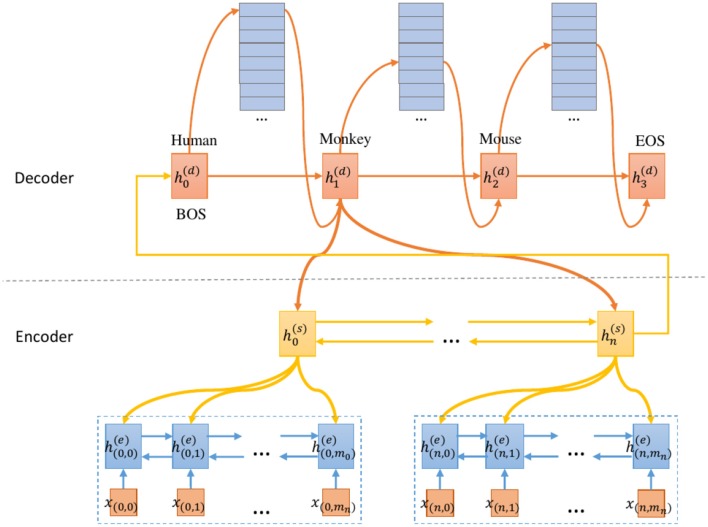
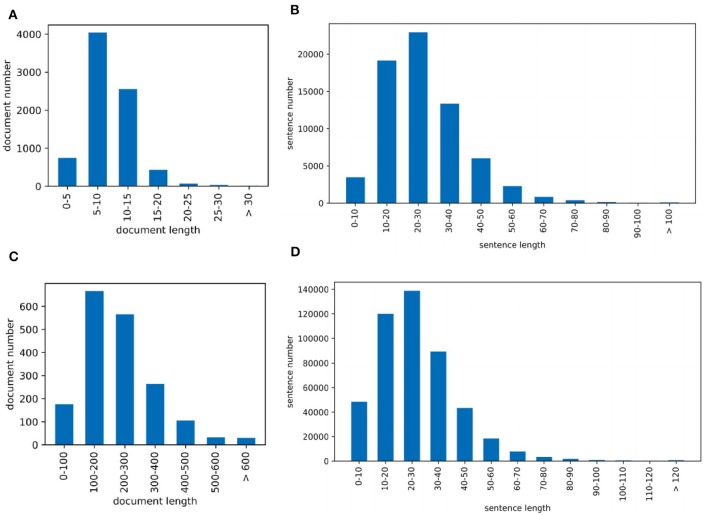
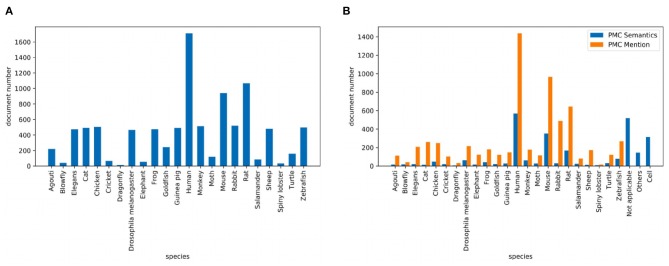
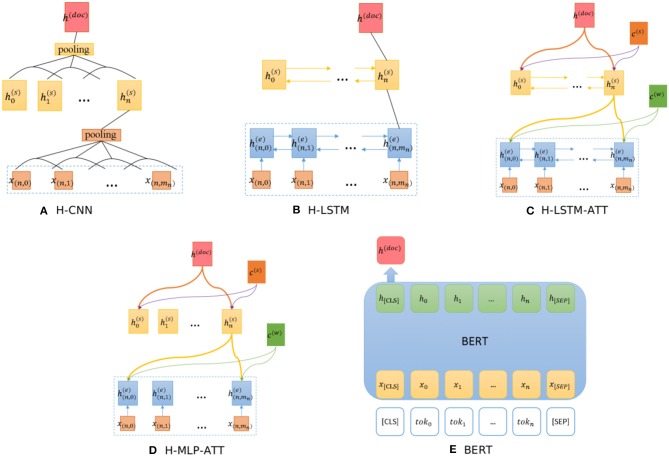
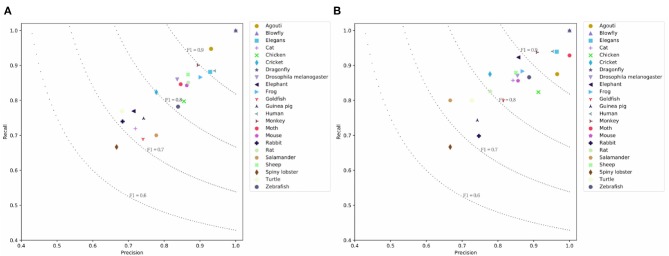
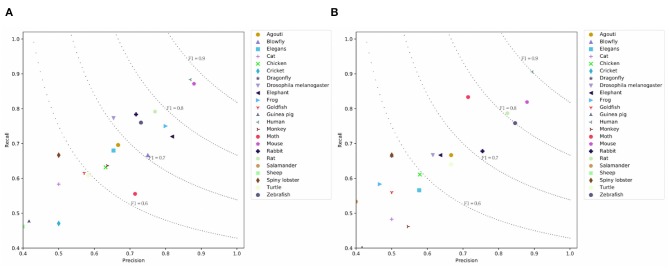
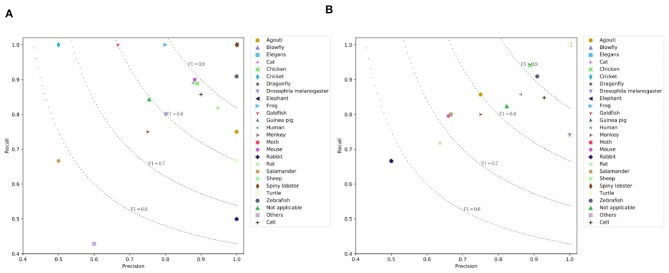
Large-scale neuroscience literature call for effective methods to mine the knowledge from species perspective to link the brain and neuroscience communities, neurorobotics, computing devices, and AI research communities. Structured knowledge can motivate researchers to better understand the functionality and structure of the brain and link the related resources and components. However, the abstracts of massive scientific works do not explicitly mention the species. Therefore, in addition to dictionary-based methods, we need to mine species using cognitive computing models that are more like the human reading process, and these methods can take advantage of the rich information in the literature. We also enable the model to automatically distinguish whether the mentioned species is the main research subject. Distinguishing the two situations can generate value at different levels of knowledge management. We propose SpecExplorer project which is used to explore the knowledge associations of different species for brain and neuroscience. This project frees humans from the tedious task of classifying neuroscience literature by species. Species classification task belongs to the multi-label classification which is more complex than the single-label classification due to the correlation between labels. To resolve this problem, we present the sequence-to-sequence classification framework to adaptively assign multiple species to the literature. To model the structure information of documents, we propose the hierarchical attentive decoding (HAD) to extract span of interest (SOI) for predicting each species. We create three datasets from PubMed and PMC corpora. We present two versions of annotation criteria (mention-based annotation and semantic-based annotation) for species research. Experiments demonstrate that our approach achieves improvements in the final results. Finally, we perform species-based analysis of brain diseases, brain cognitive functions, and proteins related to the hippocampus and provide potential research directions for certain species.
大规模的神经科学文献需要有效的方法,以便从物种角度挖掘知识,从而将大脑与神经科学界、神经机器人技术、计算设备以及人工智能研究社区联系起来。结构化知识能够促使研究人员更好地理解大脑的功能和结构,并将相关资源与组件联系起来。然而,大量科学著作的摘要并未明确提及物种。因此,除了基于词典的方法之外,我们还需要使用更类似于人类阅读过程的认知计算模型来挖掘物种,这些方法能够利用文献中的丰富信息。我们还使模型能够自动区分所提及的物种是否为主要研究对象。区分这两种情况能够在不同层次的知识管理中产生价值。我们提出了SpecExplorer项目,该项目用于探索不同物种在大脑和神经科学方面的知识关联。这个项目将人类从按物种对神经科学文献进行分类的繁琐任务中解放出来。物种分类任务属于多标签分类,由于标签之间的相关性,它比单标签分类更为复杂。为了解决这个问题,我们提出了序列到序列分类框架,以便为文献自适应地分配多个物种。为了对文档的结构信息进行建模,我们提出了分层注意力解码(HAD)方法,以提取感兴趣的跨度(SOI)来预测每个物种。我们从PubMed和PMC语料库中创建了三个数据集。我们提出了两个版本的物种研究注释标准(基于提及的注释和基于语义的注释)。实验表明,我们的方法在最终结果上取得了改进。最后,我们对与海马体相关的脑部疾病、脑认知功能和蛋白质进行了基于物种的分析,并为某些物种提供了潜在的研究方向。