Dakin Helen A, Leal José, Briggs Andrew, Clarke Philip, Holman Rury R, Gray Alastair
Nuffield Department of Population, Health Economics Research Centre, University of Oxford, Oxford, Oxfordshire, UK.
Department of Health Services Research & Policy, London School of Hygiene and Tropical Medicine, London, UK.
Med Decis Making. 2020 May;40(4):460-473. doi: 10.1177/0272989X20916442. Epub 2020 May 20.
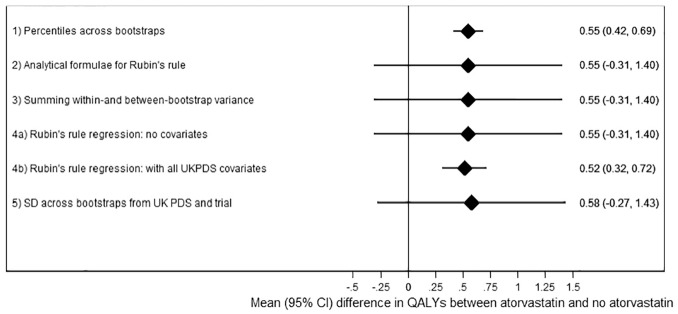
Patient-level simulation models facilitate extrapolation of clinical trial data while allowing for heterogeneity, prior history, and nonlinearity. However, combining different types of uncertainty around within-trial and extrapolated results remains challenging. We tested 4 methods to combine parameter uncertainty (around the regression coefficients used to predict future events) with sampling uncertainty (uncertainty around mean risk factors within the finite sample whose outcomes are being predicted and the effect of treatment on these risk factors). We compared these 4 methods using a simulation study based on an economic evaluation extrapolating the AFORRD randomized controlled trial using the UK Prospective Diabetes Study Outcomes Model version 2. This established type 2 diabetes model predicts patient-level health outcomes and costs. The 95% confidence intervals around life years gained gave 25% coverage when sampling uncertainty was excluded (i.e., 25% of 95% confidence intervals contained the "true" value). Allowing for sampling uncertainty as well as parameter uncertainty widened confidence intervals by 6.3-fold and gave 96.3% coverage. Methods adjusting for baseline risk factors that combine sampling and parameter uncertainty overcame the bias that can result from between-group baseline imbalance and gave confidence intervals around 50% wider than those just considering parameter uncertainty, with 99.8% coverage. Analyses extrapolating data for individual trial participants should include both sampling uncertainty and parameter uncertainty and should adjust for any imbalance in baseline covariates.
患者层面的模拟模型有助于临床试验数据的外推,同时考虑到异质性、既往史和非线性。然而,将试验内和外推结果周围不同类型的不确定性结合起来仍然具有挑战性。我们测试了4种方法,以将参数不确定性(围绕用于预测未来事件的回归系数)与抽样不确定性(在有限样本内平均风险因素周围的不确定性,其结果正在被预测,以及治疗对这些风险因素的影响)相结合。我们使用一项模拟研究比较了这4种方法,该模拟研究基于一项经济评估,使用英国前瞻性糖尿病研究结果模型第2版对AFORRD随机对照试验进行外推。这个已建立的2型糖尿病模型预测患者层面的健康结果和成本。当排除抽样不确定性时,获得的生命年周围的95%置信区间覆盖范围为25%(即95%置信区间中有25%包含“真实”值)。同时考虑抽样不确定性和参数不确定性会使置信区间扩大6.3倍,并给出96.3%的覆盖范围。调整基线风险因素以结合抽样和参数不确定性的方法克服了组间基线不平衡可能导致的偏差,其给出的置信区间比仅考虑参数不确定性时宽约50%,覆盖范围为99.8%。对单个试验参与者的数据进行外推的分析应同时包括抽样不确定性和参数不确定性,并应调整基线协变量中的任何不平衡。