Shen Cuihua, Chen Anfan, Luo Chen, Zhang Jingwen, Feng Bo, Liao Wang
Department of Communication, University of California, Davis, Davis, CA, United States.
Department of Science Communication and Science Policy, University of Science and Technology of China, Hefei, China.
J Med Internet Res. 2020 May 28;22(5):e19421. doi: 10.2196/19421.
Coronavirus disease (COVID-19) has affected more than 200 countries and territories worldwide. This disease poses an extraordinary challenge for public health systems because screening and surveillance capacity is often severely limited, especially during the beginning of the outbreak; this can fuel the outbreak, as many patients can unknowingly infect other people.
The aim of this study was to collect and analyze posts related to COVID-19 on Weibo, a popular Twitter-like social media site in China. To our knowledge, this infoveillance study employs the largest, most comprehensive, and most fine-grained social media data to date to predict COVID-19 case counts in mainland China.
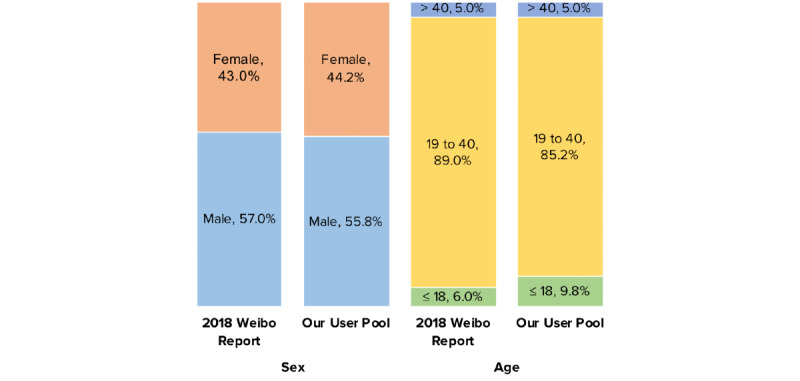
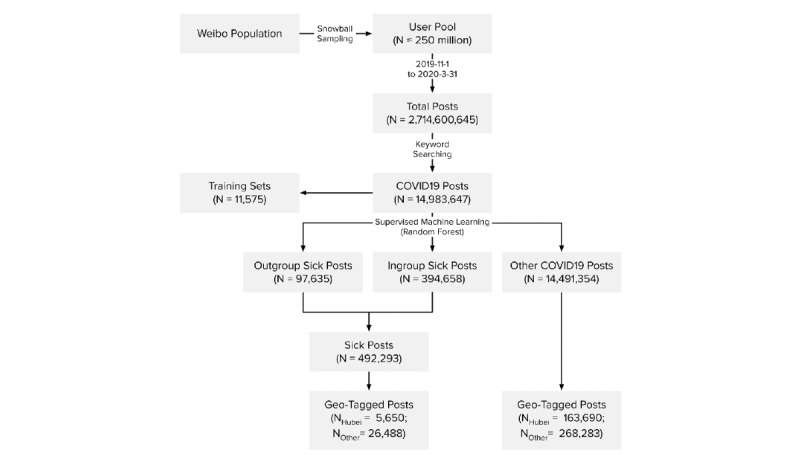
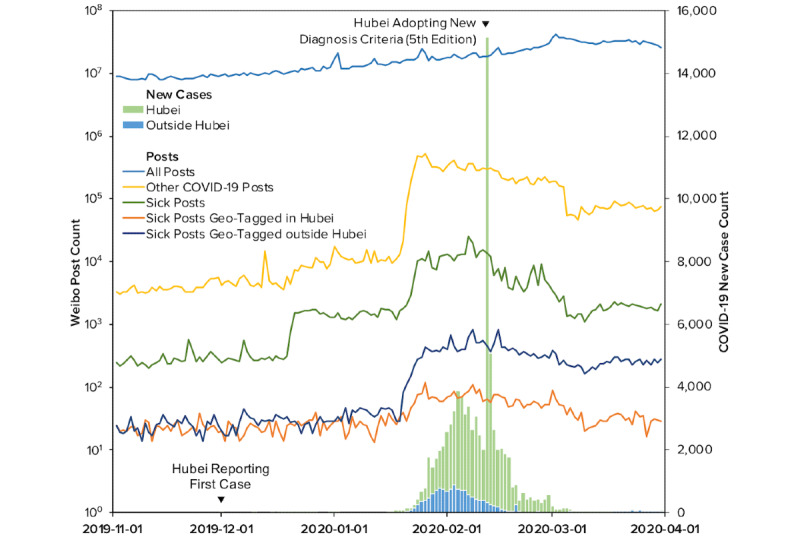
We built a Weibo user pool of 250 million people, approximately half the entire monthly active Weibo user population. Using a comprehensive list of 167 keywords, we retrieved and analyzed around 15 million COVID-19-related posts from our user pool from November 1, 2019 to March 31, 2020. We developed a machine learning classifier to identify "sick posts," in which users report their own or other people's symptoms and diagnoses related to COVID-19. Using officially reported case counts as the outcome, we then estimated the Granger causality of sick posts and other COVID-19 posts on daily case counts. For a subset of geotagged posts (3.10% of all retrieved posts), we also ran separate predictive models for Hubei province, the epicenter of the initial outbreak, and the rest of mainland China.
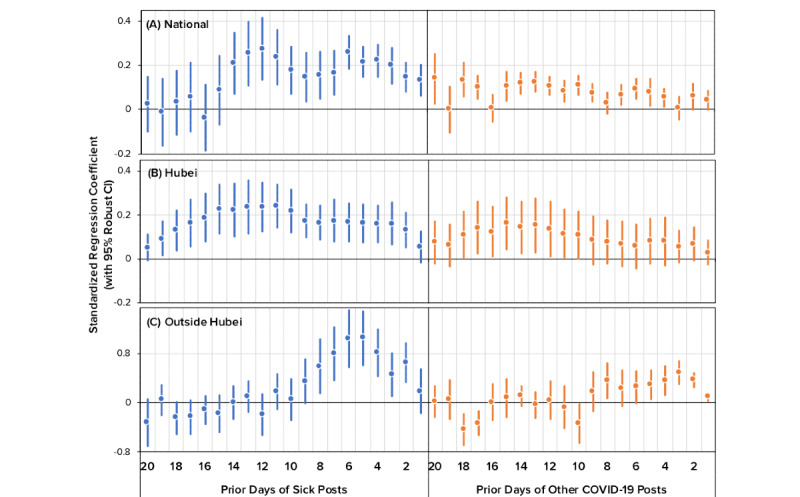
We found that reports of symptoms and diagnosis of COVID-19 significantly predicted daily case counts up to 14 days ahead of official statistics, whereas other COVID-19 posts did not have similar predictive power. For the subset of geotagged posts, we found that the predictive pattern held true for both Hubei province and the rest of mainland China regardless of the unequal distribution of health care resources and the outbreak timeline.
Public social media data can be usefully harnessed to predict infection cases and inform timely responses. Researchers and disease control agencies should pay close attention to the social media infosphere regarding COVID-19. In addition to monitoring overall search and posting activities, leveraging machine learning approaches and theoretical understanding of information sharing behaviors is a promising approach to identify true disease signals and improve the effectiveness of infoveillance.
冠状病毒病(COVID-19)已影响全球200多个国家和地区。这种疾病给公共卫生系统带来了巨大挑战,因为筛查和监测能力往往严重受限,尤其是在疫情爆发初期;这可能会助长疫情传播,因为许多患者可能在不知情的情况下感染他人。
本研究的目的是收集和分析中国类似推特的热门社交媒体微博上与COVID-19相关的帖子。据我们所知,这项信息监测研究采用了迄今为止规模最大、最全面、粒度最细的社交媒体数据来预测中国大陆的COVID-19病例数。
我们建立了一个2.5亿人的微博用户池,约占微博月活跃用户总数的一半。使用167个关键词的综合列表,我们从2019年11月1日至2020年3月31日从用户池中检索并分析了约1500万条与COVID-19相关的帖子。我们开发了一种机器学习分类器来识别“患病帖子”,即用户报告自己或他人与COVID-19相关的症状和诊断的帖子。以官方报告的病例数为结果,然后我们估计了患病帖子和其他COVID-19帖子对每日病例数的格兰杰因果关系。对于一部分带有地理标签的帖子(占所有检索帖子的3.10%),我们还分别针对疫情最初爆发的中心湖北省和中国大陆其他地区运行了预测模型。
我们发现,COVID-19症状和诊断报告在官方统计前长达14天就能显著预测每日病例数,而其他COVID-19帖子则没有类似的预测能力。对于带有地理标签的帖子子集,我们发现,无论医疗资源分配不均和疫情时间线如何,这种预测模式在湖北省和中国大陆其他地区都成立。
公共社交媒体数据可有效地用于预测感染病例并为及时应对提供信息。研究人员和疾病控制机构应密切关注有关COVID-19的社交媒体信息圈。除了监测整体搜索和发布活动外,利用机器学习方法和对信息共享行为的理论理解是识别真正疾病信号并提高信息监测有效性的一种有前途的方法。