Wellcome Centre for Integrative Neuroimaging, University of Oxford, Oxford, England, United Kingdom.
MRC Cognition and Brain Sciences Unit, Cambridge, England, United Kingdom.
PLoS One. 2020 Jun 10;15(6):e0232551. doi: 10.1371/journal.pone.0232551. eCollection 2020.
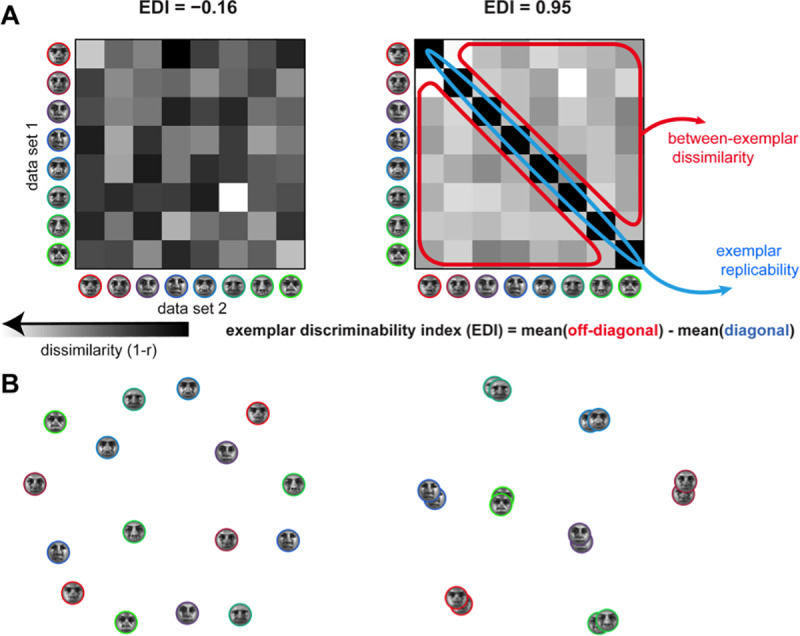
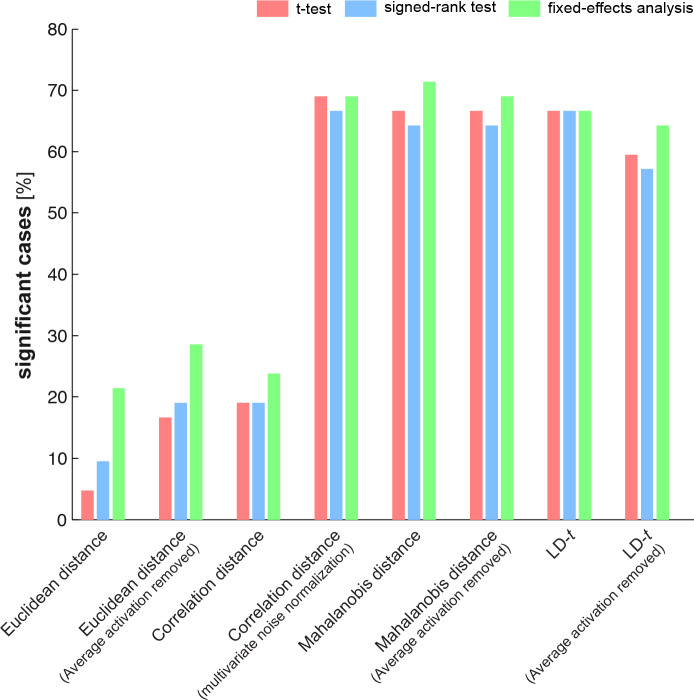
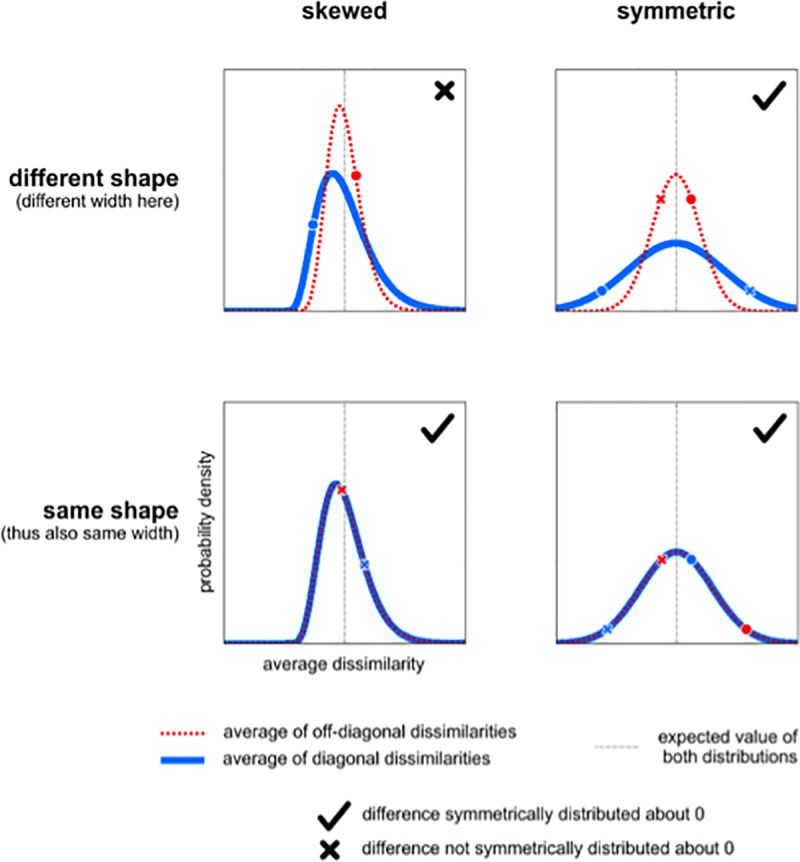
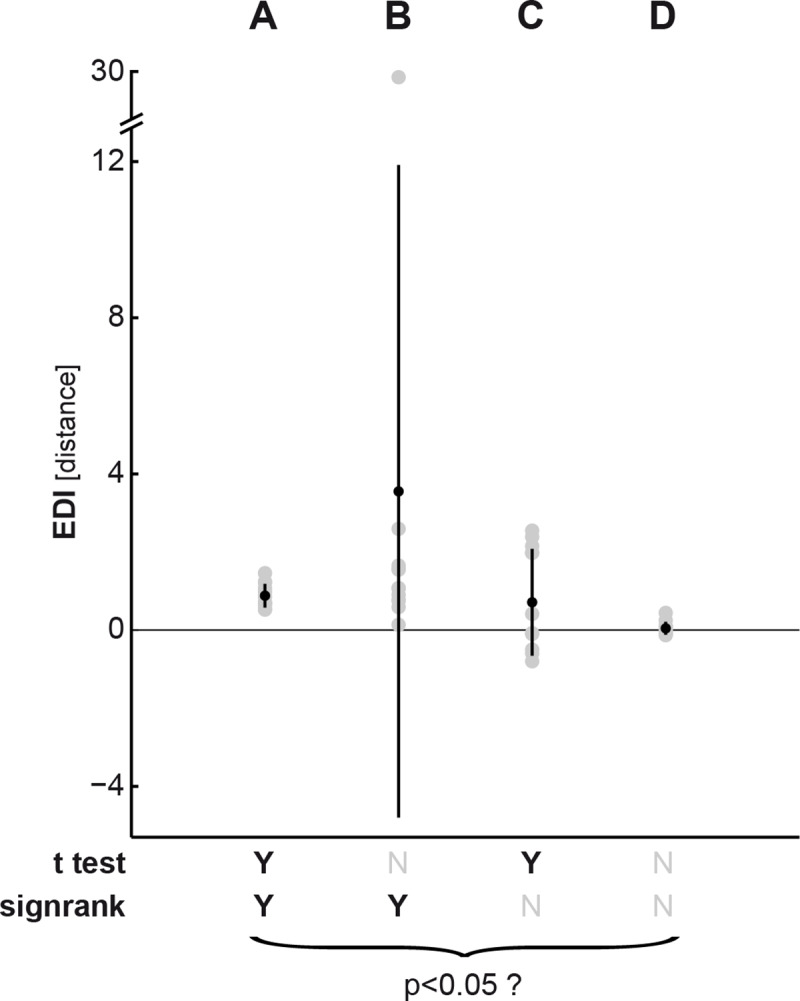
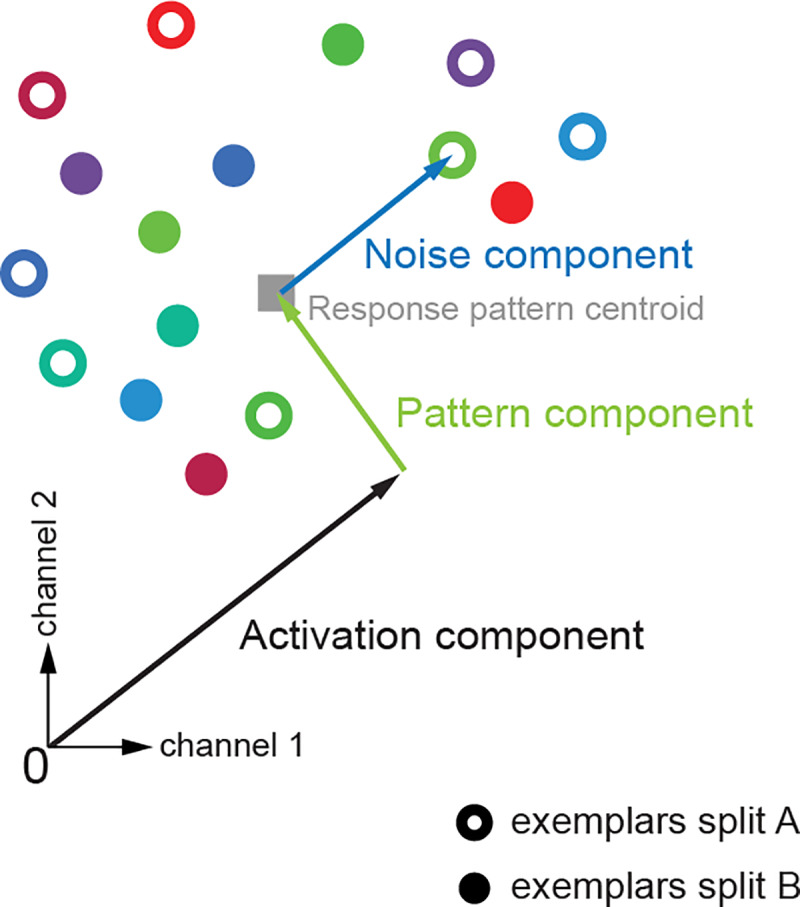
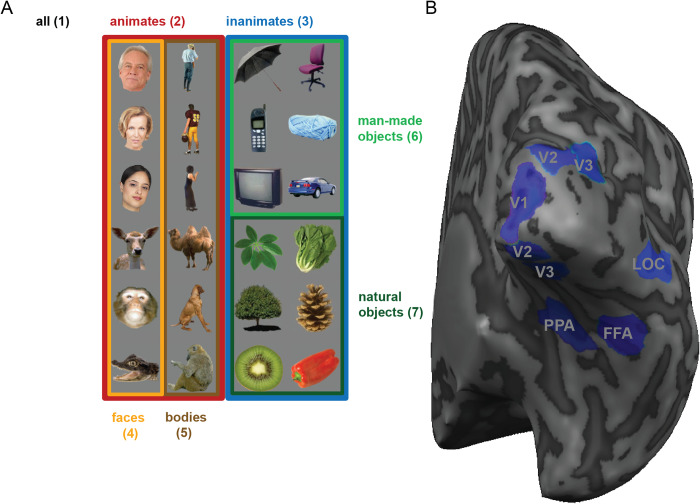
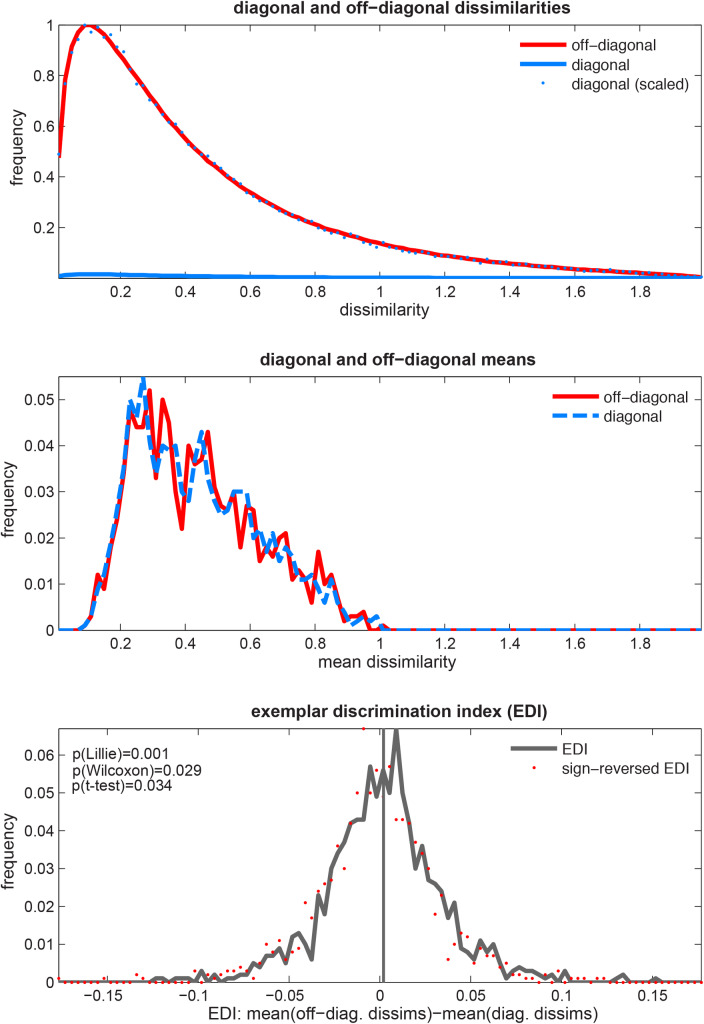
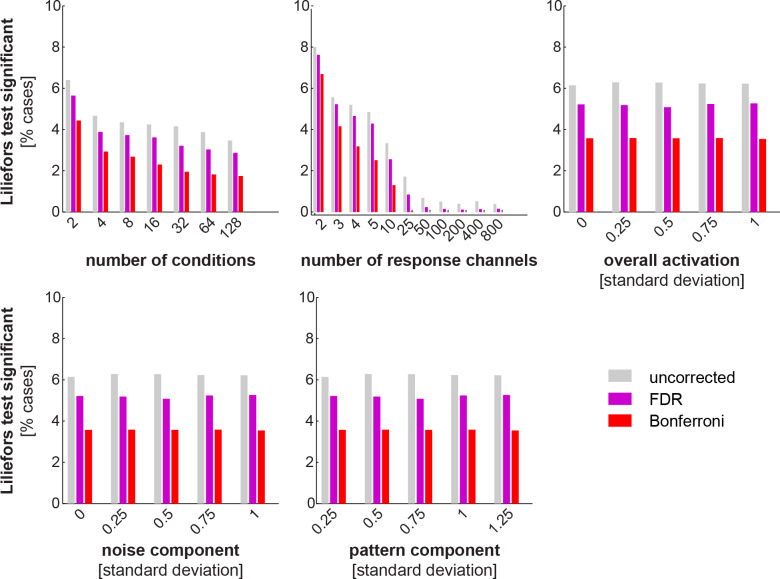
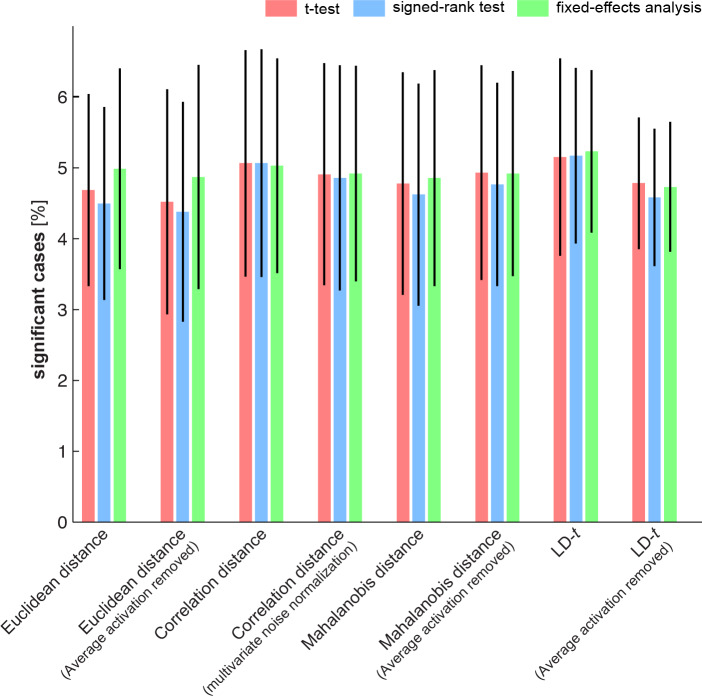
Representational distinctions within categories are important in all perceptual modalities and also in cognitive and motor representations. Recent pattern-information studies of brain activity have used condition-rich designs to sample the stimulus space more densely. To test whether brain response patterns discriminate among a set of stimuli (e.g. exemplars within a category) with good sensitivity, we can pool statistical evidence over all pairwise comparisons. Here we describe a wide range of statistical tests of exemplar discriminability and assess the validity (specificity) and power (sensitivity) of each test. The tests include previously used and novel, parametric and nonparametric tests, which treat subject as a random or fixed effect, and are based on different dissimilarity measures, different test statistics, and different inference procedures. We use simulated and real data to determine which tests are valid and which are most sensitive. A popular test statistic reflecting exemplar information is the exemplar discriminability index (EDI), which is defined as the average of the pattern dissimilarity estimates between different exemplars minus the average of the pattern dissimilarity estimates between repetitions of identical exemplars. The popular across-subject t test of the EDI (typically using correlation distance as the pattern dissimilarity measure) requires the assumption that the EDI is 0-mean normal under H0. Although this assumption is not strictly true, our simulations suggest that the test controls the false-positives rate at the nominal level, and is thus valid, in practice. However, test statistics based on average Mahalanobis distances or average linear-discriminant t values (both accounting for the multivariate error covariance among responses) are substantially more powerful for both random- and fixed-effects inference. Unlike average cross-validated distances, the EDI is sensitive to differences between the distributions associated with different exemplars (e.g. greater variability for some exemplars than for others), which complicates its interpretation. We suggest preferred procedures for safely and sensitively detecting subtle pattern differences between exemplars.
类别内的代表性区别在所有感知模式中以及在认知和运动表现中都很重要。最近对大脑活动的模式信息研究使用了条件丰富的设计来更密集地采样刺激空间。为了测试大脑反应模式是否可以很好地敏感地区分一组刺激(例如类别中的示例),我们可以汇总所有成对比较的统计证据。在这里,我们描述了广泛的示例可辨别性统计检验,并评估了每种检验的有效性(特异性)和功效(敏感性)。这些检验包括以前使用过的和新的、参数和非参数检验,它们将主体视为随机或固定效应,并且基于不同的不相似性度量、不同的检验统计量和不同的推断程序。我们使用模拟和真实数据来确定哪些检验是有效的,哪些检验最敏感。反映示例信息的流行检验统计量是示例辨别指数(EDI),它定义为不同示例之间的模式不相似性估计的平均值减去相同示例的重复之间的模式不相似性估计的平均值。EDI 的流行的跨主体 t 检验(通常使用相关距离作为模式不相似性度量)需要假设 EDI 在 H0 下为 0-均值正态。尽管此假设并不严格正确,但我们的模拟表明,该检验在实践中控制了假阳性率在名义水平,因此是有效的。但是,基于平均马氏距离或平均线性判别 t 值的检验统计量(都考虑了响应之间的多元误差协方差)对于随机和固定效应推断都具有更高的功效。与平均交叉验证距离不同,EDI 对与不同示例相关联的分布之间的差异敏感(例如,某些示例的变化比其他示例大),这使其解释变得复杂。我们建议用于安全且敏感地检测示例之间细微模式差异的首选程序。