Li Xiaoxiao, Gu Yufeng, Dvornek Nicha, Staib Lawrence H, Ventola Pamela, Duncan James S
Biomedical Engineering, Yale University, New Haven, CT, 06511, USA.
College of Information Science & Electronic Engineering, Zhejiang University, Hangzhou, 310058, China.
Med Image Anal. 2020 Oct;65:101765. doi: 10.1016/j.media.2020.101765. Epub 2020 Jul 2.
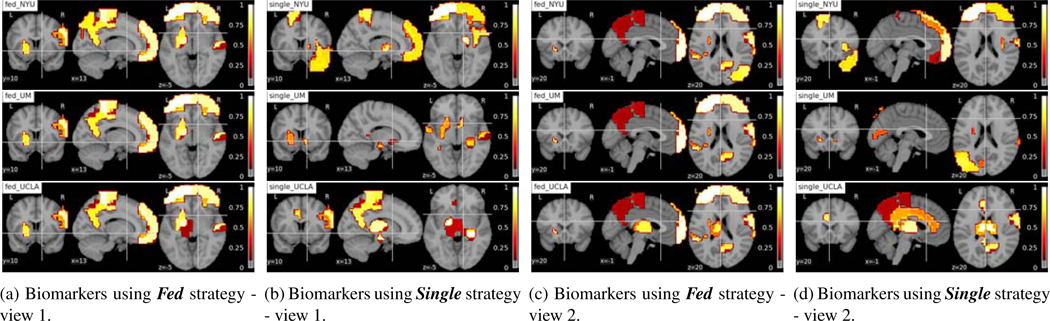
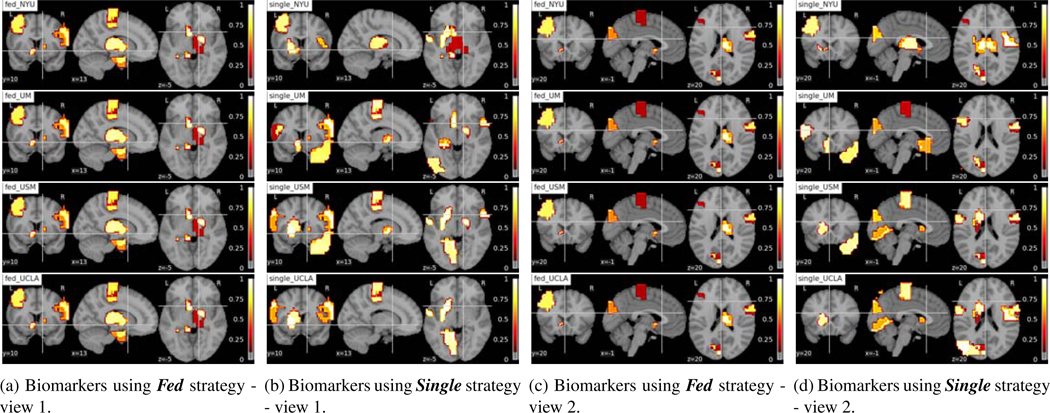
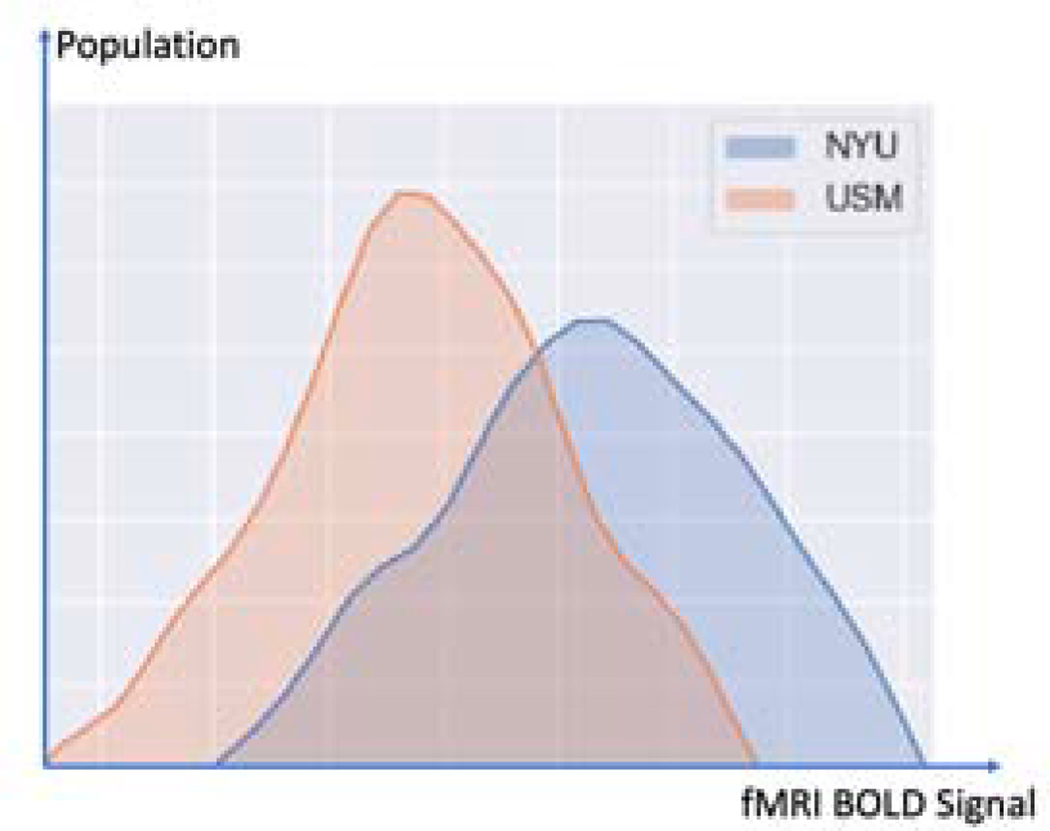
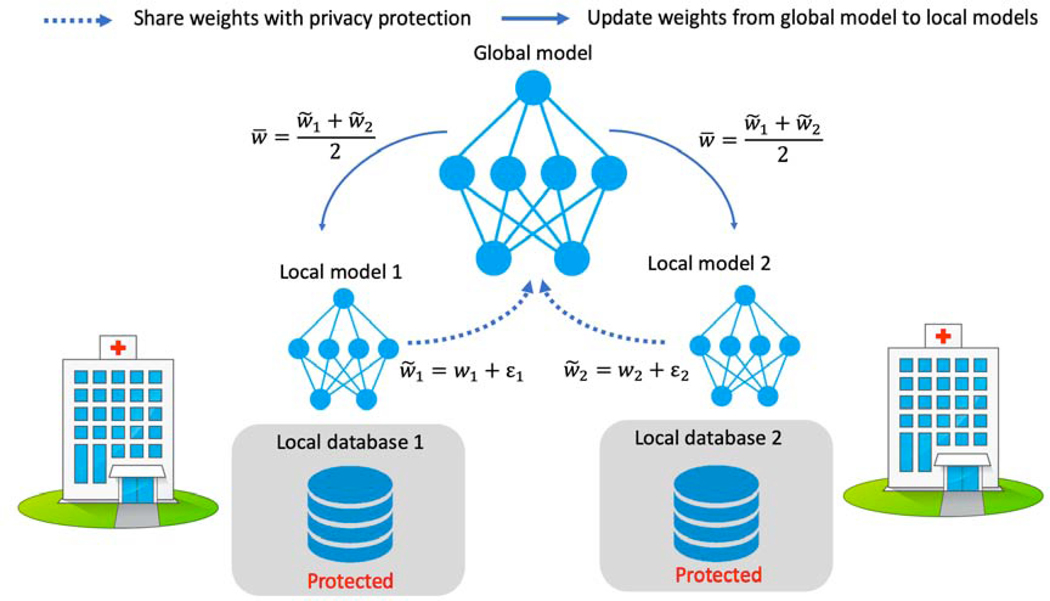
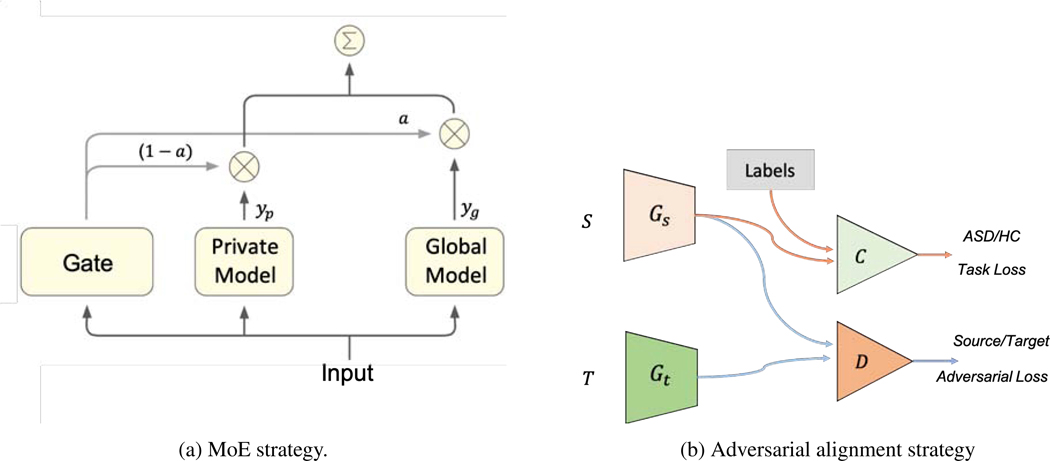
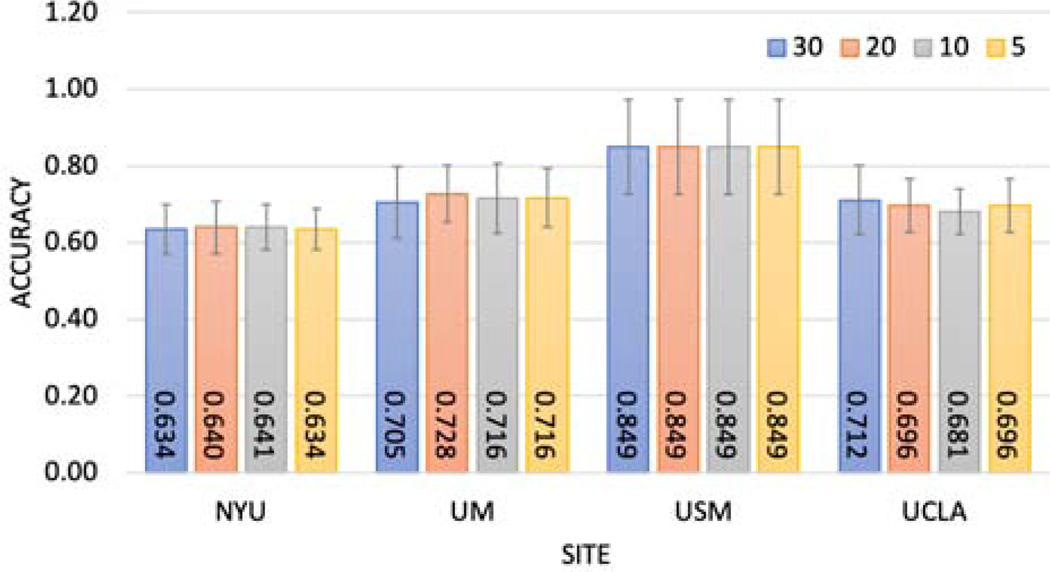
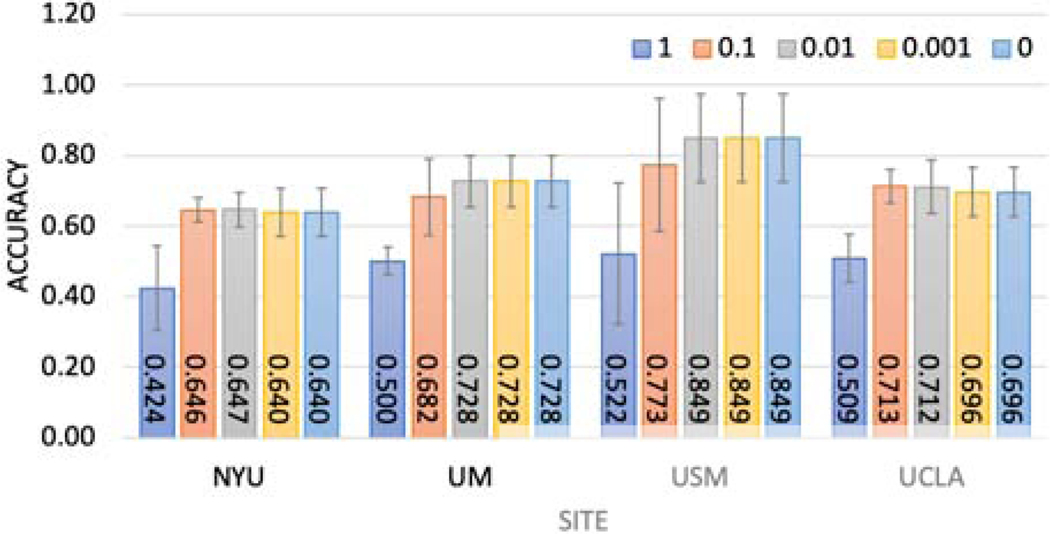
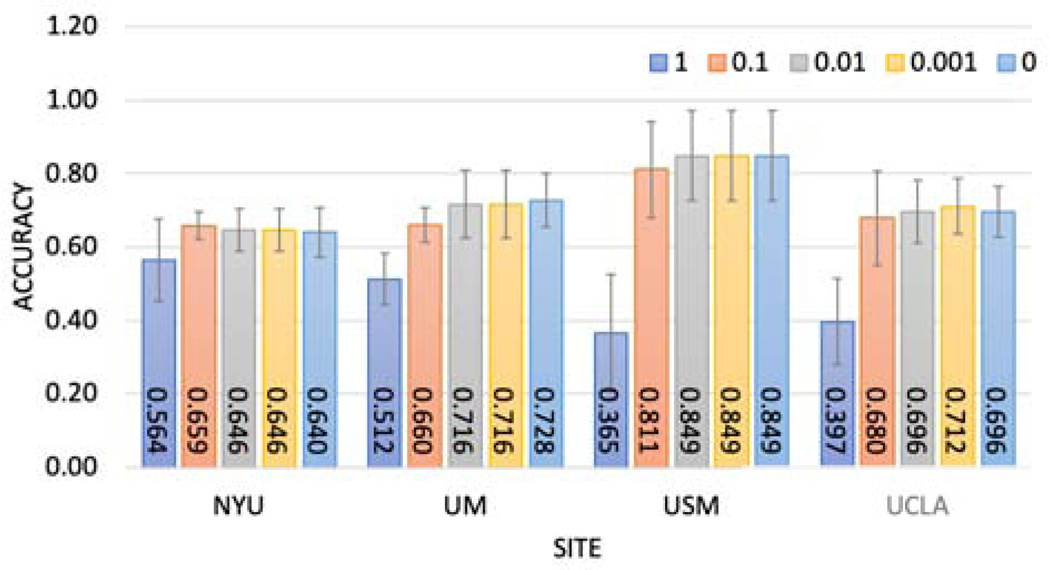
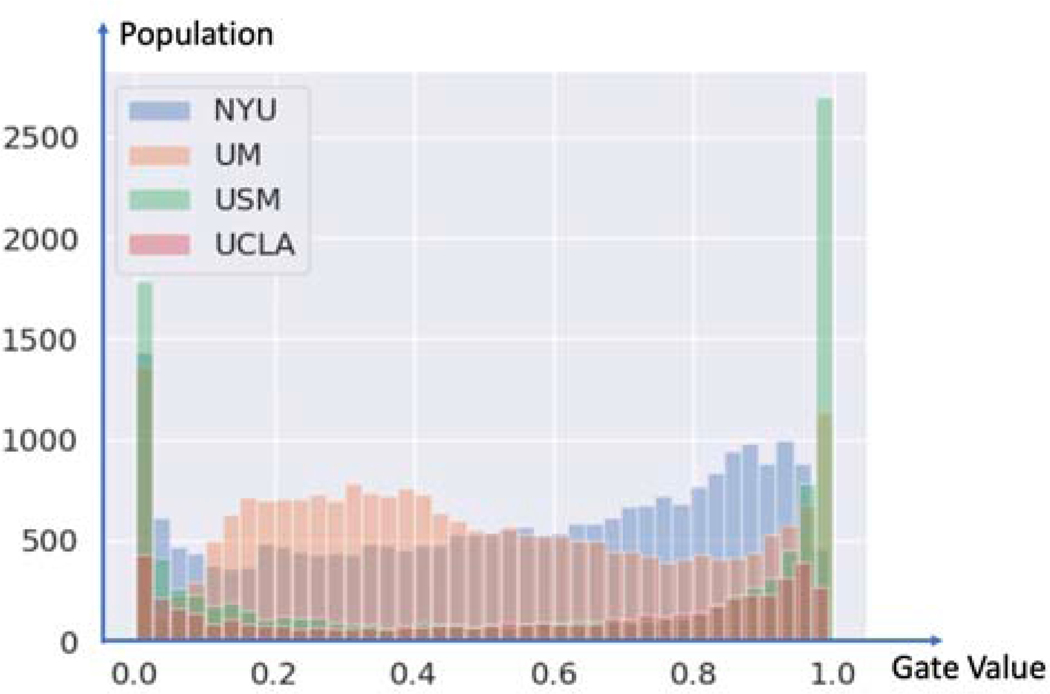
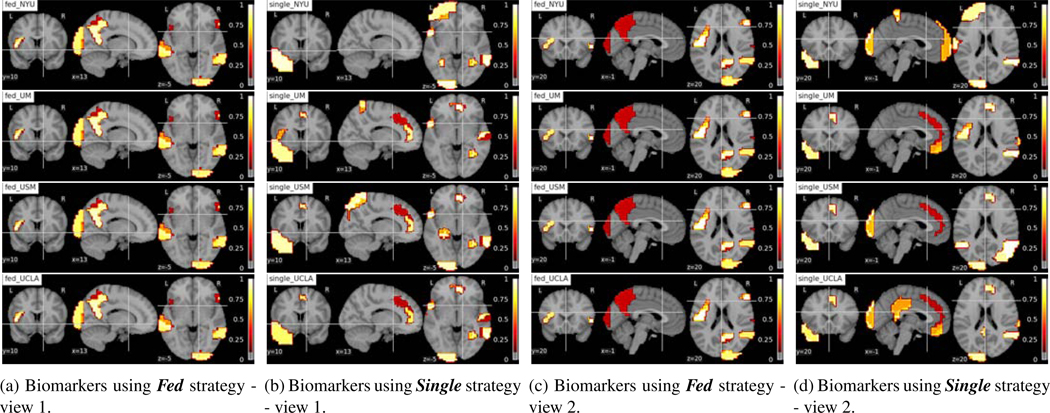
Deep learning models have shown their advantage in many different tasks, including neuroimage analysis. However, to effectively train a high-quality deep learning model, the aggregation of a significant amount of patient information is required. The time and cost for acquisition and annotation in assembling, for example, large fMRI datasets make it difficult to acquire large numbers at a single site. However, due to the need to protect the privacy of patient data, it is hard to assemble a central database from multiple institutions. Federated learning allows for population-level models to be trained without centralizing entities' data by transmitting the global model to local entities, training the model locally, and then averaging the gradients or weights in the global model. However, some studies suggest that private information can be recovered from the model gradients or weights. In this work, we address the problem of multi-site fMRI classification with a privacy-preserving strategy. To solve the problem, we propose a federated learning approach, where a decentralized iterative optimization algorithm is implemented and shared local model weights are altered by a randomization mechanism. Considering the systemic differences of fMRI distributions from different sites, we further propose two domain adaptation methods in this federated learning formulation. We investigate various practical aspects of federated model optimization and compare federated learning with alternative training strategies. Overall, our results demonstrate that it is promising to utilize multi-site data without data sharing to boost neuroimage analysis performance and find reliable disease-related biomarkers. Our proposed pipeline can be generalized to other privacy-sensitive medical data analysis problems. Our code is publicly available at: https://github.com/xxlya/Fed_ABIDE/.
深度学习模型已在包括神经影像分析在内的许多不同任务中展现出优势。然而,要有效训练高质量的深度学习模型,需要聚合大量患者信息。例如,在组装大型功能磁共振成像(fMRI)数据集时,采集和标注所需的时间和成本使得在单个站点难以获取大量数据。然而,由于需要保护患者数据隐私,很难从多个机构组装一个中央数据库。联邦学习允许在不集中实体数据的情况下训练总体水平的模型,方法是将全局模型传输到本地实体,在本地训练模型,然后对全局模型中的梯度或权重进行平均。然而,一些研究表明,可以从模型梯度或权重中恢复私人信息。在这项工作中,我们采用一种隐私保护策略来解决多站点fMRI分类问题。为了解决这个问题,我们提出一种联邦学习方法,其中实施了一种去中心化迭代优化算法,并且通过一种随机化机制改变共享的局部模型权重。考虑到来自不同站点的fMRI分布的系统差异,我们在这个联邦学习框架中进一步提出两种域适应方法。我们研究了联邦模型优化的各个实际方面,并将联邦学习与其他训练策略进行了比较。总体而言,我们的结果表明,在不进行数据共享的情况下利用多站点数据来提高神经影像分析性能并找到可靠的疾病相关生物标志物是有前景的。我们提出的流程可以推广到其他对隐私敏感的医学数据分析问题。我们的代码可在以下网址公开获取:https://github.com/xxlya/Fed_ABIDE/