School of Computer Engineering and Science, Shanghai University, Shanghai 200444, China.
Shanghai Institute for Advanced Communication and Data Science, Shanghai University, Shanghai 200444, China.
Sensors (Basel). 2020 Jul 21;20(14):4048. doi: 10.3390/s20144048.
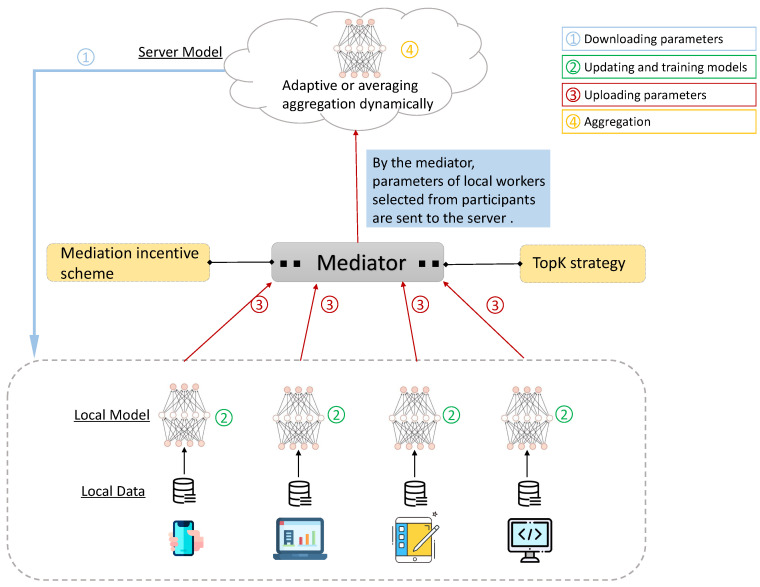
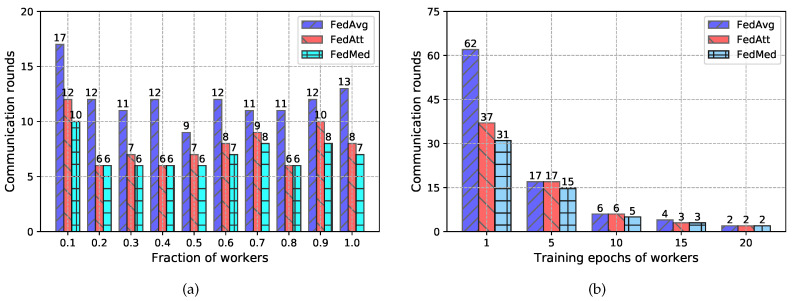
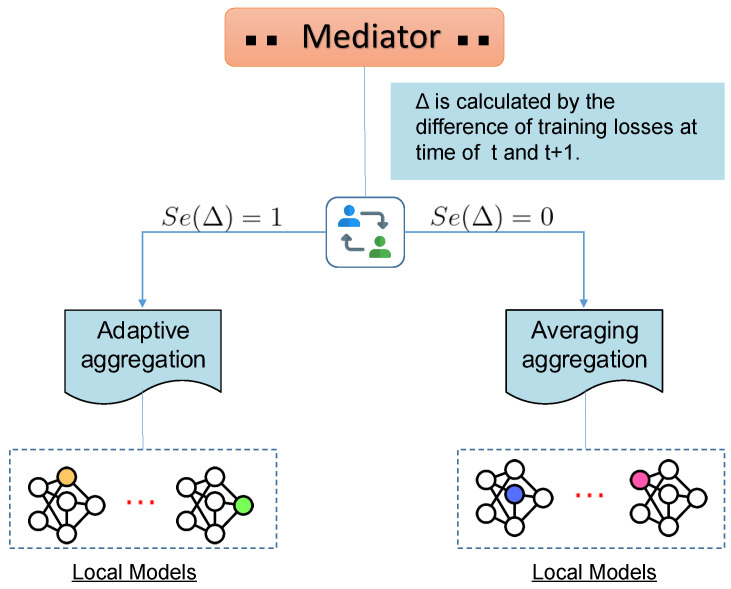
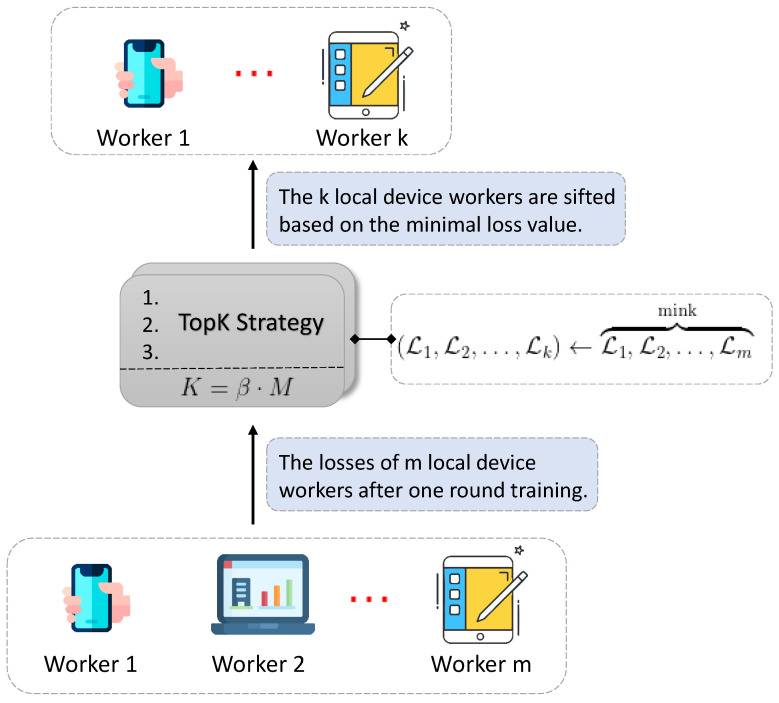
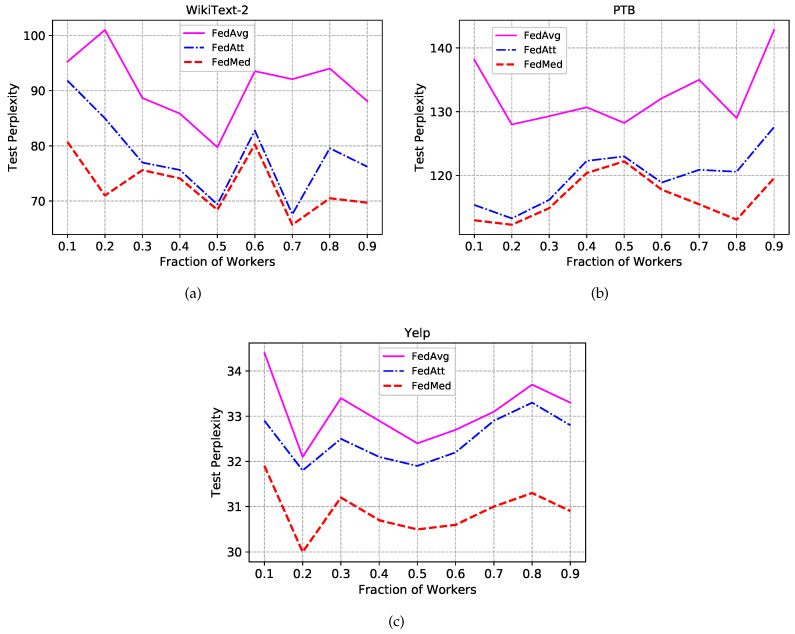
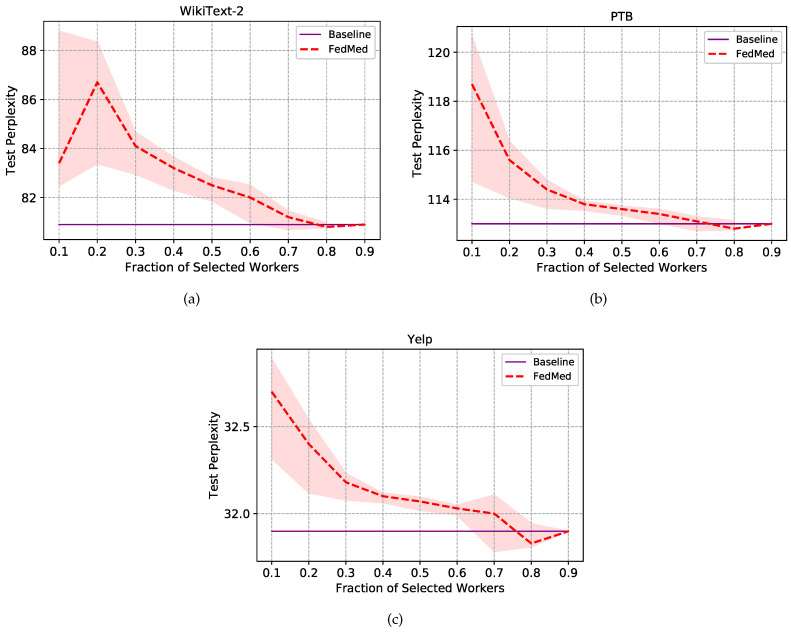
Federated learning (FL) is a privacy-preserving technique for training a vast amount of decentralized data and making inferences on mobile devices. As a typical language modeling problem, mobile keyboard prediction aims at suggesting a probable next word or phrase and facilitating the human-machine interaction in a virtual keyboard of the smartphone or laptop. Mobile keyboard prediction with FL hopes to satisfy the growing demand that high-level data privacy be preserved in artificial intelligence applications even with the distributed models training. However, there are two major problems in the federated optimization for the prediction: (1) aggregating model parameters on the server-side and (2) reducing communication costs caused by model weights collection. To address the above issues, traditional FL methods simply use averaging aggregation or ignore communication costs. We propose a novel Federated Mediation (FedMed) framework with the adaptive aggregation, mediation incentive scheme, and topK strategy to address the model aggregation and communication costs. The performance is evaluated in terms of perplexity and communication rounds. Experiments are conducted on three datasets (i.e., Penn Treebank, WikiText-2, and Yelp) and the results demonstrate that our FedMed framework achieves robust performance and outperforms baseline approaches.
联邦学习(FL)是一种保护隐私的技术,用于训练大量分散的数据,并在移动设备上进行推断。作为一个典型的语言建模问题,移动键盘预测旨在建议一个可能的下一个单词或短语,并在智能手机或笔记本电脑的虚拟键盘中促进人机交互。带有 FL 的移动键盘预测希望满足人工智能应用程序中保护高级别数据隐私的不断增长的需求,即使使用分布式模型进行训练也是如此。然而,在预测的联邦优化中存在两个主要问题:(1)在服务器端聚合模型参数,(2)减少模型权重收集引起的通信成本。为了解决上述问题,传统的 FL 方法简单地使用平均聚合或忽略通信成本。我们提出了一种新颖的联邦调解(FedMed)框架,具有自适应聚合、调解激励方案和 topK 策略,以解决模型聚合和通信成本问题。性能根据困惑度和通信轮数进行评估。在三个数据集(即 Penn Treebank、WikiText-2 和 Yelp)上进行了实验,结果表明我们的 FedMed 框架实现了稳健的性能,优于基线方法。